Building a high-performance embedding and indexing system for large-scale document processing

1. Intro
Recently, Retrieval-Augmented Generation (or simply RAG) has become a de facto standard for building generative AI applications using large language models. RAG enhances text generation by ensuring the generative model uses the appropriate context while avoiding the time, cost, and complexity involved in fine-tuning LLMs for the same task. RAG also allows for more efficient use of external data sources and easier updates to the model’s “knowledge”.
Although AI applications based on RAG can often use more modest or smaller LLMs, they still depend on a powerful pipeline that embeds and indexes the required knowledge base, as well as on being able to efficiently retrieve and inject the relevant context to the model prompt.
In many use cases, RAG can be implemented in a few lines of code using any of the great frameworks that are widely available for the task. This post focuses on more complex and demanding pipelines, such as when the volume of the data to embed and index is relatively high, or when it needs to be updated very frequently or just very fast.
This post demonstrates how to design a Rust application that reads, chunks, embeds, and stores textual documents as vectors at blazing speed. Using HuggingFace’s Candle framework for Rust and LanceDB, it shows how to develop an end-to-end RAG indexing pipeline that can be deployed anywhere as a standalone application, and serve as a basis for a powerful pipeline, even in very demanding and isolated environments.
The main purpose of this post is to create a working example that can be applied to real-world use cases, while guiding the reader through its key design principles and building blocks. The application and its source code are available in the accompanying GitHub repository (linked below), which can be used as-is or as an example for further development.
The post is structured as follows: Section 2 explains the main design choices and relevant components at a high level. Section 3 details the main flow and component design of the pipeline. Sections 4 and 5 discuss the embedding flow and the write task, respectively. Section 6 concludes.
2. Design Choices and Key Components
Our main design goal is to build an independent application that can run an end-to-end indexing pipeline without external services or server processes. Its output will be a set of data files in LanceDB’s Lance format, that can be used by frameworks such as LangChain or Llamaindex, and queried using DuckDB or any application using LanceDB API.
The application will be written in Rust and based on two major open source frameworks: we will be using the Candle ML framework to handle the machine learning task of generating document embedding with a BERT-like model, and LanceDB as our vector db and retrieval API.

It might be useful to say a few words about these components and design choices before we get into the details and structure of our application.
Rust is an obvious choice where performance matters. Although Rust has a steep learning curve, its performance is comparable to native programming languages, such as C or C++, and it provides a rich library of abstractions and extensions that make challenges such as memory safety and concurrency easier to handle than in native languages. Together with Hugging Face’s Candle framework, using LLMs and embedding models in native Rust has never been smoother.
LanceDB, however, is a relatively new addition to the RAG stack. It is a lean and embedded vector database (like SQLite) that can be integrated directly into applications without a separate server process. It can therefore be deployed anywhere and embedded in any application, while offering blazing fast search and retrieval capabilities, even over data that lies in remote object storage, such as AWS S3. As mentioned earlier, it also offers integrations with LangChain and LlamaIndex, and can be queried using DuckDB, which makes it an even more attractive choice of vector storage.
In a simple test conducted on my 10-core Mac (without GPU acceleration), the application processed, embedded, and stored approximately 25,000 words (equivalent to 17 text files, each containing around 1,500 words) in just one second. This impressive throughput demonstrates Rust’s efficiency in handling both CPU-intensive tasks and I/O operations, as well as LanceDB’s robust storage capabilities. The combination proves exceptional for addressing large-scale data embedding and indexing challenges.

3. Pipeline Architecture and Flow
Our RAG application and indexing pipeline consists of 2 main tasks: A read and embed task, which reads text from a text file and embed it in a BERT vector using an embedding model, and a write task, which writes the embedding to the vector store. Because the former is mostly CPU bound (embedding a single document may require multiple ML model operations), and the latter is mostly waiting on IO, we will separate these tasks to different threads. Additionally, in order to avoid contention and back-pressure, we will also connect the 2 tasks with an MPSC channel. In Rust (and other languages), sync channels basically enable thread-safe and asynchronous communication between threads, thereby allowing it to better scale.
The main flow is simple: each time an embedding task finishes embedding a text document into a vector, it will “send” the vector and its ID (filename) to the channel and then immediately continue to the next document (see the reader side in the diagram below). At the same time, the write task continuously reads from the channel, chunk the vectors in memory and flush it when it reaches a certain size. Because I expect the embedding task to be more time and resource consuming, we will parallelize it to use as many cores that are available on the machine where the application is running. In other words, we will have multiple embedding tasks that read and embed documents, and a single writer that chunk and write the vectors to the database.
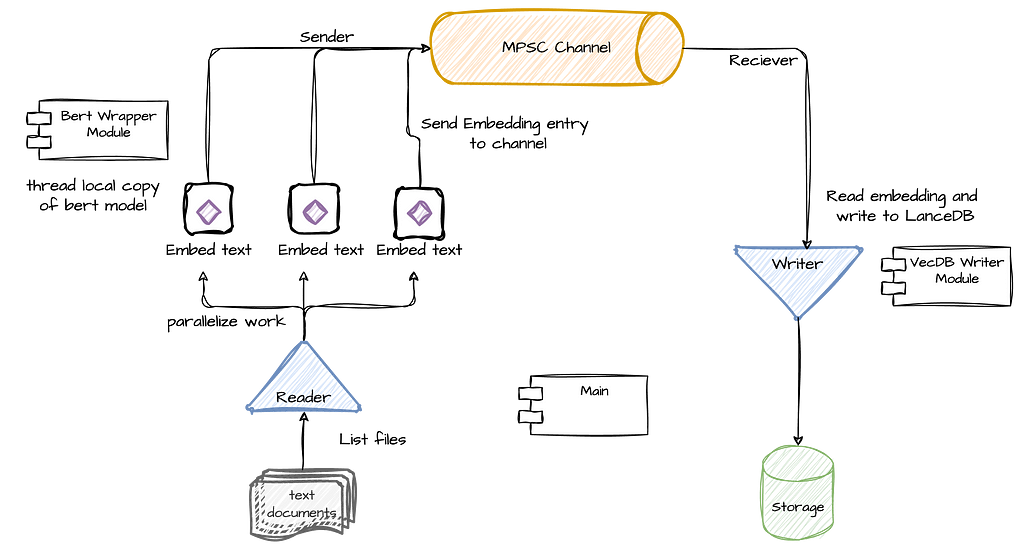
Lets start with the main() function, which will make the flow of the pipeline clearer.
As you can see above, after setting up the channel (line 3), we initialize the write task thread, which starts polling messages from the channel until the channel is closed. Next, it lists the files in the relevant directory and stores them in a collection of strings. Finally, it uses Rayon to iterate the list of files (with the par_iter function) in order to parallelize its processing using the process_text_file() function. Using Rayon will allow us to scale the parallel processing of the documents as much as we can get out from the machine we are working on.
As you can see, the flow is relatively straightforward, primarily orchestrating two main tasks: document processing and vector storage. This design allows for efficient parallelization and scalability. The document processing task uses Rayon to parallelize file handling, maximizing the use of available system resources. Simultaneously, the storage task manages the efficient writing of embedded vectors to LanceDB. This separation of concerns not only simplifies the overall architecture but also allows for independent optimization of each task. In the sections that follow, we’ll delve into both of these functions in greater detail.
4. Document Embedding with Candle
As we saw earlier, on one end of our pipeline we have multiple embedding tasks, each running on its own thread. Rayon’s iter_par function effectively iterates through the file list, invoking the process_text_file() function for each file while maximizing parallelization.
Lets start with the function itself:
The function starts by first getting its own reference to the embedding model (that’s the trickiest part of the function and I will address this shortly). Next, it reads the file into chunks of a certain size, and call the embedding function (which basically calls the model itself) over each chunk. The embedding function returns a vector of type Vec<f32> (and size [1, 384]), which is the outcome of embedding and normalizing each chunk, and afterwards taking the mean of all text chunks together. When this part is done, then the vector is sent to the channel, together with the file name, for persistence, query, and retrieval by the writing task.
As you can see most of the work here is done by the BertModelWrapper struct (to which we get a reference in line 2). The main purpose of BertModelWrapper is to encapsulate the model’s loading and embedding operations, and provide the embed_sentences() function, which essentially embeds a group of text chunks and calculates their mean to produce a single vector.
To achieve that, BertModelWrapper uses HuggingFace’s Candle framework. Candle is a native Rust library with an API similar to PyTorch that is used to load and manage ML models, and has a very convenient support in models hosted in HuggingFace. There are other ways in Rust to generate text embedding though Candle seems like the “cleanest” in terms of its being native and not dependent on other libraries.
While a detailed explanation of the wrapper’s code is beyond our current scope, I’ve written more about this in a separate post (linked here) and its source code is available in the accompanying GitHub repository. You can also find excellent examples in Candle’s examples repository.
However, there is one important part that should be explained about the way we are using the embedding model as this will be a challenge anywhere we will need to work with models in scale within our process. In short, we want our model to be used by multiple threads running embedding tasks yet due to its loading times, we don’t want to create the model each time it is needed. In other words, we want to ensure that each thread will create exactly one instance of the model, which it will own and reuse to generate embedding over multiple embedding tasks.
Due to Rust’s well-known constraints these requirements are not very easy to implement. Feel free to skip this part (and just use the code) if you don’t want to get too much into the details of how this is implement in Rust.
Let’s start with the function that gets a model reference:
Our model is wrapped in a few layers in order to enable the functionality detailed above. First, it is wrapped in a thread_local clause which means that each thread will have its own lazy copy of this variable — i.e., all threads can access BERT_MODEL, but the initialization code which is invoked when with() is first called (line 18), will only be executed lazily and once per thread so that each thread will have a valid reference that is initialized once. The second layer is a reference counting type — Rc, which simply makes it easier to create references of the model without dealing with lifetimes. Each time we call clone() on it, we get a reference that is automatically released when it goes out of scope.
The last layer is essentially the serving function get_model_reference(), which simply calls the with() function that provides access to the thread local area in memory holding the initialized model. The call to clone() will give us a thread local reference to the model, and if it was not initialized yet then the init code will be executed first.
Now that we learned how to run multiple embedding tasks, executed in parallel, and writing vectors to the channel, we can move on to the other part of the pipeline — the writer task.

4. Writing Task: Efficient Vector Storage
The writing task is somewhat simpler and mainly serve as an interface that encapsulates LanceDB’s writing functions. Recall that LanceDB is an embedded database, which means it’s a query engine as a library that reads and writes data that can reside on remote storage, such as AWS S3, and it does not own the data . This makes it especially convenient for use cases in which we have to process large-scale data with low latency without managing a separate database server.
LanceDB’s Rust API uses Arrow for schema definition and for representing data (its Python API might be more convenient for some). For example, this is how we define our schema in Arrow format:
As you can see, our current schema consists of two fields: a “filename” field, which will hold the actual file location and will serve as our key, and a “vector” field that holds the actual document vector. In LanceDB, vectors are represented using a FixedSizeList Arrow type (which represents an array), while each item in the vector will be of type Float32. (The length of the vector, set last, will be 384.)
Connecting to LanceDB is straightforward, requiring only a storage location, which can be either a local storage path or an S3 URI. However, appending data to LanceDB using Rust and Arrow data structures is less developer-friendly. Similar to other Arrow-based columnar data structures, instead of appending a list of rows, each column is represented as a list of values. For example, if you have 10 rows to insert with 2 columns, you need to append 2 lists, one for each column, with 10 values in each.
Here is an example:
The core of the code is on line 2, where we build an Arrow RecordBatch from our schema and column data. In this case, we have two columns — filename and vector. We initialize our record batch with two lists: key_array, a list of strings representing filenames, and vectors_array, a list of arrays containing the vectors. From there, Rust’s strict type safety requires us to perform extensive wrapping of this data before we can pass it to the add() function of the table reference obtained on line 1.
To simplify this logic, we create a storage module that encapsulates these operations and provides a simple interface based on a connect(uri) function and an add_vector function. Below is the full code of the writing task thread that reads embedding from the channel, chunks them, and writes when it reaches a certain size:
Once data is written, LanceDB data files can be accessed from any process. Here is an example for how we can use the same data for a vector similarity search using LanceDB Python API that can be executed from a completely different process.
uri = "data/vecdb1"
db = lancedb.connect(uri)
tbl = db.open_table("vectors_table_1")
# the vector we are finding similarities for
encoded_vec = get_some vector()
# perform a similiarity search for top 3 vectors
tbl.search(embeddings[0])
.select(["filename"])
.limit(3).to_pandas()
5. Conclusion
In this post, we’ve seen a working example of a high-performance RAG pipeline using Rust, HuggingFace’s Candle framework, and LanceDB. We saw how we can leverage Rust’s performance capabilities together with Candle in order efficiently read and embed multiple text files in parallel. We have also seen how we can use sync channels to concurrently run the embedding tasks together with a writing flow without dealing with complex locking and sync mechanisms. Finally, we learned how we can take advantage of LanceDB’s efficient storage using Rust, and generate vector storage that can be integrated with multiple AI frameworks and query libraries.
I believe that the approach outlined here can serves as a powerful basis for building scalable, production-ready RAG indexing pipeline. Whether you’re dealing with large volumes of data, requiring frequent knowledge base updates, or operating in resource-constrained environments, the building blocks and design principles discussed here can be adapted to meet your specific needs. As the field of AI continues to evolve, the ability to efficiently process and retrieve relevant information will remain crucial. By combining the right tools and thoughtful design, as demonstrated in this post, developers can create RAG pipelines that not only meet current demands but are also well-positioned to tackle future challenges in AI-powered information retrieval and generation.
Notes and Links
- Accompanying GitHub with source code can be found here. The repo also contains sample jupyter notebook showing how to test this using Python
- My previous post focusing on HuggingFace Candle can be found here.
- Candle framwork and its documentation, including their comprehensive example folder
- LanceDB and its Rust API documentation
Scale Up Your RAG: A Rust-Powered Indexing Pipeline with LanceDB and Candle was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Scale Up Your RAG: A Rust-Powered Indexing Pipeline with LanceDB and Candle