

Practical insights and analysis from experiments with MMLU-Pro
Introduction
Developing AI agents that can, among other things, think, plan and decide with human-like proficiency is a prominent area of current research and discussion. For now, LLMs have taken the lead as the foundational building block for these agents. As we pursue ever increasingly complex capabilities, regardless of the LLM(s) being utilized, we inevitably encounter the same types of questions over and over, including:
- Does the model have the necessary knowledge to complete a task accurately and efficiently?
- If the appropriate knowledge is available, how do we reliably activate it?
- Is the model capable of imitating complex cognitive behavior such as reasoning, planning and decision making to an acceptable level of proficiency?
This article explores these questions through the lens of a recent mini-experiment I conducted that leverages the latest MMLU-Pro benchmark. The findings lead to some interesting insights around cognitive flexibility and how we might apply this concept from cognitive science to our AI agent and prompt engineering efforts.
Background
MMLU-Pro — A multiple choice gauntlet
The recently released MMLU-Pro (Massive Multitask Language Understanding) benchmark tests the capability boundaries of AI models by presenting a more robust and challenging set of tasks compared to its predecessor, MMLU [1]. The goal was to create a comprehensive evaluation covering a diverse array of subjects, requiring models to possess a broad base of knowledge and demonstrate the ability to apply it in varied contexts. To this end, MMLU-Pro tests models against very challenging, reasoning-oriented multiple-choice questions spread across 14 different knowledge domains.
We are all quite familiar with multiple-choice exams from our own academic journeys. The strategies we use on these types of tests often involve a combination of reasoning, problem solving, recall, elimination, inference, and educated guessing. Our ability to switch seamlessly between these strategies in underpinned by cognitive flexibility, which we employ to adapt our approach to the demands of each specific question.
Cognitive flexibility encompasses mental capabilities such as switching between different concepts and thinking about multiple concepts simultaneously. It enables us to adapt our thinking in response to the situation at hand. Is this concept potentially useful in our AI agent and prompt engineering efforts? Before we explore that, let’s examine a sample question from MMLU-Pro in the “business” category:
Question 205: If the annual earnings per share has mean $8.6 and standard deviation $3.4, what is the chance that an observed EPS less than $5.5?
Answers: A: 0.3571, B: 0.0625, C: 0.2345, D: 0.5000, E: 0.4112, F: 0.1814, G: 0.3035, H: 0.0923, I: 0.2756, J: 0.1587
Although categorically labelled as ‘business’, this question requires knowledge of statistics. We need to standardize the value and calculate how many standard deviations it is away from the mean to get a probability estimate. This is done by calculating the Z-score as follows:
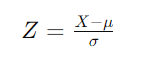
Where:
X is the value in question ($5.50 in this case)
μ is the mean (given as $8.6).
σ is the standard deviation (given as $3.4)
If we substitute those values into the formula we get -0.09118. We then consult the standard normal distribution table and find that the probability of Z being less than -0.9118 is approximately 18.14% which correspond to answer “F” from our choices.
I think it is safe to say that this is a non-trivial problem for an LLM to solve. The correct answer cannot be memorized and needs to be calculated. Would an LLM have the knowledge and cognitive flexibility required to solve this type of problem? What prompt engineering strategies might we employ?
Prompt Engineering to the Rescue
In approaching the above problem with an LLM, we might consider: does our chosen model have the knowledge of statistics needed? Assuming it does, how do we reliably activate the knowledge around standard normal distributions? And finally, can the model imitate the mathematical reasoning steps to arrive at the correct answer?
The widely known “Chain-of-Thought” (CoT) prompt engineering strategy seems like a natural fit. The strategy relies on prompting the model to generate intermediate reasoning steps before arriving at the final answer. There are two basic approaches.
Chain-of-Thought (CoT): Involves few-shot prompting, where examples of the reasoning process are provided to guide the model [2].
Zero-Shot Chain-of-Thought (Zero-Shot CoT): Involves prompting the model to generate reasoning steps without prior examples, often using phrases like “Let’s think step by step” [3].
There are numerous other strategies, generally relying on a combination of pre-generation feature activation, i.e. focusing on activating knowledge in the initial prompt, and intra-generation feature activation, i.e. focusing on the LLM dynamically activating knowledge as it generates its output token by token.
Mini-Experiment
Experiment Design
In designing the mini-experiment, I utilized ChatGPT-4o and randomly sampled 10 questions from each of the 14 knowledge domains in the MMLU-Pro data set. The experiment aimed to evaluate two main aspects:
- Effectiveness of different prompt engineering techniques: Specifically, the impact of using different techniques for activating the necessary knowledge and desired behavior in the model. The techniques were selected to align with varying degrees of cognitive flexibility and were all zero-shot based.
- The impact from deliberately limiting reasoning and cognitive flexibility: Specifically, how limiting the model’s ability to reason openly (and by consequence severely limiting cognitive flexibility) affects accuracy.
The different prompt techniques tested relied on the following templates:
Direct Question — {Question}. Select the correct answer from the following answer choices: {Answers}. Respond with the letter and answer selected.
CoT — {Question}. Let’s think step by step and select the correct answer from the following answer choices: {Answers}. Respond with the letter and answer selected.
Knowledge Domain Activation — {Question}. Let’s think about the knowledge and concepts needed and select the correct answer from the following answer choices: {Answers}. Respond with the letter and answer selected.
Contextual Scaffolds — {Question}. My expectations are that you will answer the question correctly. Create an operational context for yourself to maximize fulfillment of my expectations and select the correct answer from the following answer choices: {Answers}. Respond with the letter and answer selected. [4]
The Direct Question approach served as the baseline, likely enabling the highest degree of cognitive flexibility from the model. CoT would likely lead to the least amount of cognitive flexibility as the model is instructed to proceed step-by-step. Knowledge Domain Activation and Contextual Scaffolds fall somewhere between Direct Question and CoT.
Deliberately constraining reasoning was accomplished by taking the last line of the above prompt templates, i.e. “Respond with the letter and answer selected.” and specifying instead “Respond only with the letter and answer selected and nothing else.”
If you are interested in the code I used to run the experiment and results, they can be found in this GitHub repo linked here.
Results
Here are the results for the different prompt techniques and their reasoning constrained variants:
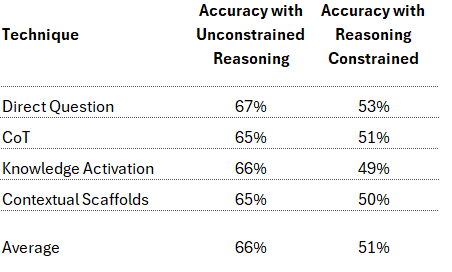
All unconstrained reasoning prompts performed comparably, with the Direct Question approach performing slightly better than the others. This was a bit of a surprise since the MMLU-Pro paper [1] reports significant underperformance in direct question and strong performance gains with few-shot CoT. I won’t dwell on the discrepancy here since the purpose of the mini-experiment was not to replicate their setup.
More importantly for this mini-experiment, when reasoning was deliberately constrained, all techniques showed a comparable decline in accuracy, dropping from an average of 66% to 51%. This result is along the lines of what we expected. The more pertinent observation is that none of the techniques were successful in enhancing pre-generation knowledge activation beyond what would occur with Direct Question where pre-generation feature activation primarily occurs from the model being exposed to the text in the question and answer choices.
The overall conclusion from these high-level results suggests that an optimal combination for prompt engineering effectiveness may very well involve:
- Allowing the model to exercise some degree of cognitive flexibility as exemplified best in the Direct Question approach.
- Allowing the model to reason openly such that the reasoning traces are an active part of the generation.
The Compute Cost Dimension
Although not often discussed, token efficiency is becoming more and more important as LLMs find their way into varied industry use cases. The graph below shows the accuracy of each unconstrained prompt technique versus the average tokens generated in the answer.
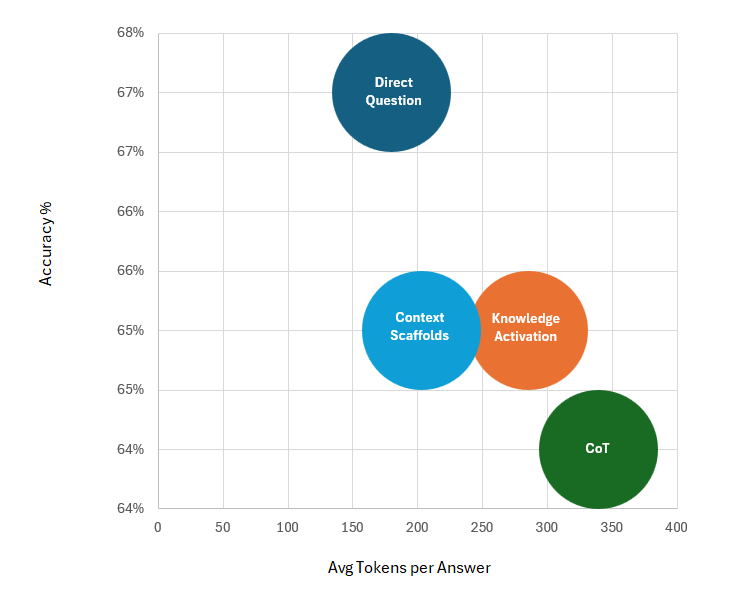
While the accuracy differential is not the primary focus, the efficiency of the Direct Question approach, generating an average of 180 tokens per answer, is notable compared to CoT, which produced approximately 339 tokens per answer (i.e. 88% more). Since accuracy was comparable, it leads us to speculate that CoT is on average less efficient compared to the other strategies when it comes to intra-generation knowledge activation, producing excessively verbose results. But what drove the excessive verbosity? To try and answer this it was helpful to examine the unconstrained reasoning prompts and number of times the model chose to answer with just the answer and no reasoning trace, even if not explicitly instructed to do so. The results were as follows:

What was even more interesting was accuracy when the model chose to answer directly without any reasoning trace which is shown in the following table:
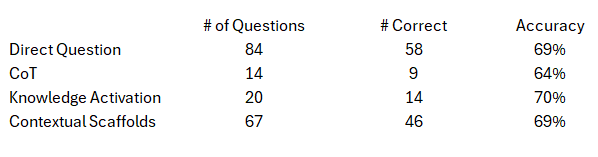
The accuracy ranged from 64% to 70% without any reasoning traces being generated. Even with MMLU-Pro questions that are purposely designed to require reasoning and problem solving, when not over-constrained by the prompt, the model appears to demonstrate somethin akin to selecting different strategies based on the specific question at hand.
Practical Implications
The practical takeaway from these results is that straightforward prompt strategies can often be just as effective as overly structured ones. While CoT aims to simulate reasoning by inducing specific feature activations that are reasoning oriented, it may not always be necessary or optimal especially if excess token generation is a concern. Striving instead to allow the model to exercise cognitive flexibility can be a potentially more suitable approach.
Conclusion: Paving the Way for Cognitive Flexibility in AI Agents
The findings from this mini-experiment offer compelling insights into the importance of cognitive flexibility in LLMs and AI Agents. In human cognition, cognitive flexibility refers to the ability to adapt thinking and behavior in response to changing tasks or demands. It involves switching between different concepts, maintaining multiple concepts simultaneously, and shifting attention as needed. In the context of LLMs, it can be understood as the model’s ability to dynamically adjust its internal activations in response to textual stimuli.
Continued focus on developing technologies and techniques in this area could result in significant enhancements to AI agent proficiency in a variety of complex task settings. For example, exploring the idea alongside other insights such as those surfaced by Anthropic in their recent paper “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet,” could yield techniques that unlock the ability to dynamically observe and tailor the level of cognitive flexibility employed based on the task’s complexity and domain.
As we push the boundaries of AI, cognitive flexibility will likely be key to creating models that not only perform reliably but also understand and adapt to the complexities of the real world.
Thanks for reading and follow me for insights that result from future explorations connected to this work. If you would like to discuss do not hesitate to connect with me on LinkedIn.
Unless otherwise noted, all images in this article are by the author.
References:
[1] Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, Wenhu Chen: MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. arXiv:2406.01574, 2024
[2] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903v6 , 2023
[3] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa: Large Language Models are Zero-Shot Reasoners. arXiv:2205.11916v4, 2023
[4] Giuseppe Scalamogna, A Universal Roadmap for Prompt Engineering: The Contextual Scaffolds Framework (CSF), https://medium.com/towards-data-science/a-universal-roadmap-for-prompt-engineering-the-contextual-scaffolds-framework-csf-fdaf5a9fa86a, 2023
Prompt Engineering for Cognitive Flexibility was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Prompt Engineering for Cognitive Flexibility
Go Here to Read this Fast! Prompt Engineering for Cognitive Flexibility