
NLP: Text Summarization and Keyword Extraction on Property Rental Listings — Part 1
A practical implementation of NLP techniques such as text summarization, NER, topic modeling, and text classification on rental listing data
Introduction
Natural Language Processing (NLP) can significantly enhance the analysis and usability of rental listing descriptions. In this exercise, we’ll explore the practical application of NLP techniques such as text summarization, Named Entity Recognition (NER), and topic modeling to extract insights and enrich the listing description on Airbnb listing data in Tokyo. Using publicly available data and tools like spaCy and SciKit-Learn, you can follow along, reproduce the results, or apply these techniques to your own text data with minimal adjustments. The codebase is available on GitHub for you to fork and experiment with.
Part 1 (this article) covers the basics: the goal, the data and its preparation, and the methods used to extract keywords and text summaries using various techniques such as named entity recognition (NER), TF-IDF / sentence scoring, and Google’s T5 (Text-to-Text Transformer). We’ll also touch on leveraging these insights to improve user experience — serving suggestions included.
Part 2 (coming soon) covers topic modeling and text prediction: Part 2 will demonstrate how to perform topic modeling on unlabeled data. This upcoming article will discuss techniques like clustering to uncover hidden themes and building a predictive model to classify property rentals based on their categories and themes.
Goal
The task is straightforward:
Given an example input: The rental description
Generate output:
- Keywords: “commercial street”, “stores”, or “near station”
Keywords help visualize data, uncover themes, identify similarities, and improve search functionality on the front end. Suggestions to serve these keywords are included at the bottom of this article. - Summary: A sentence or two, roughly about 80 characters.
Summaries provide concise information, enhancing the user experience by quickly conveying the most essential aspects of a listing. - Theme/Topic: “Excellent Access”, “Family Friendly.”
Categorizing listings that share the same theme can serve as a recommender system, aiding users in finding properties that match their preferences. Unlike individual keywords, these themes can cover a group of multiple keywords (kitchen, desk, queen bed, long-term => “Digital-Nomad Friendly”). We will deep-dive this in Part 2 (upcoming article).
Chapters:
- Data and Preparation
Getting the data, cleaning, custom lemma - Text Summarization
TFIDF/sentence scoring, Deep-Learning, LLM (T5), evaluation - Keyword Extraction using NER
Regex, Matcher, Deep-Learning - Serving Suggestion
1. Data and Preparation
Our dataset consists of rental listing descriptions sourced from insideairbnb.com, licensed under a Creative Commons Attribution 4.0 International License. We focus on the text written by property owners. The data contains nearly 15,000 rental descriptions, mainly in English. Records written in Japanese (surprisingly, only a handful of them!) were removed as part of the data cleaning task, which also involved removing duplicates and HTML artifacts left by the scraper. Due to a lot of data deduplication, which could be the byproduct of the web scraper, or possibly even more complex issues (such as owners posting multiple identical listings), data cleaning removed about half of the original size.
1a. spaCy Pipeline
Once the data is clean, we can start building the spaCy pipeline. We can begin with a blank slate or use a pre-trained model like en_core_web_sm to process documents in English. This model includes a robust pipeline with:
- Tokenization: Splitting text into words, punctuation marks, etc.
- Part-of-Speech Tagging: Tagging words as nouns, verbs, etc.
- Dependency Parsing: Identifying relationships between words.
- Sentencizer: Breaking down the documents into sentences.
- Lemmatization: Reducing words to their base forms (e.g., seeing, see, saw, seen).
- Attribute Ruler: Adding, removing, or changing token attributes.
- Named Entity Recognition: Identifying categories of named entities (persons, locations, etc.).
1b. Custom Lemmatization
Even with a battle-tested pipeline like en_core_web_sm, adjustments are often needed to cover specific use cases. For example, abbreviations commonly used in the rental industry (e.g., br for bedroom, apt for apartment, st for street) could be introduced into the pipeline through custom lemmatization. To evaluate this, we can count the number of token.lemma_ between pipeline with and without the custom lemma. If needed, other more robust pre-made pipeline, such as en_core_web_md (medium), or en_core_web_lg (large), are also available.
In production-level projects, a more thorough list is needed and more rigorous data cleaning might be required. For example, emojis and emoji-like symbols are frequently included in culturally influenced writing, like by Japanese users. These symbols can introduce noise and require specific handling, such as removal or transformation. Other data pre-processing, such as a more robust proper sentence boundary detector may also be necessary to address sentences with missing spaces, such as “This is a sentence.This is too. And also this.and this. But, no, this Next.js is a valid term and not two sentences!”
2. Text Summarization
Navigating rental options in Tokyo can be overwhelming. Each listing promises to be the ideal home. Still, the data suggests that the property descriptions often fall short — they can be overly long, frustratingly brief, or muddled with irrelevant details; this is why text summarization can come in handy.

2a. Level: Easy — TF-IDF
One typical approach to text summarization involves leveraging a technique called TF-IDF (Term Frequency-Inverse Document Frequency). TF-IDF considers both how frequently a word appears in a specific document (the rental listing) and how uncommon it is across the entire dataset of listings or corpus. This technique is also helpful for various text analysis tasks, such as indexing, similarity detection, and clustering (which we will explore in Part 2).
Another variation of the technique is sentence scoring based on word co-occurrence. Like TF-IDF, this method calculates scores by comparing word occurrences within the document. This approach is fast and easy and requires no additional tools or even awareness of other documents. You can even do this on the fly at the front end using typescript, although it is not recommended.
However, extractive summarization techniques like these have a pitfall: they only find the best sentence in the document, which means that typos or other issues in the chosen sentence will appear in the summary. These typos also affect the scoring, making this model less forgiving of mistakes and important information not included in the selected sentence (or sentences) might be missed.
2b. Level: Intermediate — Deep Learning
Beyond frequency-based methods, we can leverage the power of deep learning for text summarization. Sequence-to-sequence (Seq2Seq) models are a neural network architecture designed to translate sequences from one form to another. In text summarization tasks, these models act like complex translators.
A Seq2Seq model typically consists of two parts: an encoder and a decoder. The encoder processes the entire input text, capturing its meaning and structure. This information is then compressed into a hidden representation. Then, the decoder takes this hidden representation from the encoder to generate a new sequence — the text summary. During training, the decoder learns to translate the encoded representation that captures the key points of the original text. Unlike extractive methods, these models perform abstractive summarization: generating summaries in their own words rather than extracting sentences directly from the text.
2c. Level: Advanced — Pre-Trained Language Models

Pre-trained language models like T5 (Text-To-Text Transfer Transformer) or BERT (Bidirectional Encoder Representations from Transformers) can significantly enhance summarization for those with the resources and setup capabilities. However, while these models can be effective for large text, they might be overkill for this specific use case. Not only does it require more setup to function optimally, but it also includes the need for prompt engineering (pre-processing), retraining or fine-tuning, and post-processing (such as grammar, text capitalization, or even fact-checking and sanity check) to guide the model toward the desired output.
2.d Evaluating Text Summarization

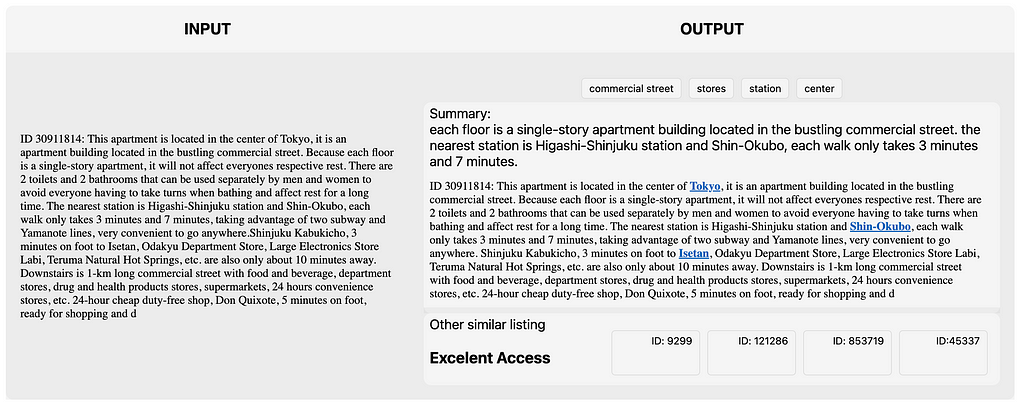
As seen from the picture above, when comparing “simple” model using TFIDF versus complex model using LLM, the winner isn’t always clear. Evaluating the quality of a text summarization system is a complicated challenge. Unlike tasks with a single, definitive answer, there’s no single perfect summary for a given text. Humans can prioritize different aspects of the original content, which further makes it hard to design automatic metrics that perfectly align with human judgment.
Evaluation metrics like ROUGE (Recall-Oriented Understudy for Gisting Evaluation) attempt to do just this. By comparing the overlaps between n-grams (sequences of words) between generated summaries and human-written summaries, ROUGE systematically scores the quality of the summaries. This method relies on a collection of human-written summaries as a baseline for evaluation, which often not available.
3. Keyword Extraction Using Named Entity Recognition (NER)
While summaries are helpful, keywords have different purposes. Keywords capture the most essential aspects that potential renters might be looking for. To extract keywords, we can use NLP techniques such as Named Entity Recognition (NER). This process goes beyond just identifying frequent words. We can extract critical information by considering factors like word co-occurrence and relevance to the domain of rental listings. This information can be a single word, such as ‘luxurious’ (adjective), ‘Ginza’ (location), or a phrase like ‘quiet environment’ (noun phrases) or ‘near to Shinjuku’ (proximity).

3a. Level: Easy — Regex
The ‘find’ function in string operations, along with regular expressions, can do the job of finding keywords. However, this approach requires an exhaustive list of words and patterns, which is sometimes not practical. If an exhaustive list of keywords to look for is available (like stock exchange abbreviations for finance-related projects), regex might be the simplest way to do it.
3b. Level: Intermediate — The Matcher
While regular expressions can be used for simple keyword extraction, the need for extensive lists of rules makes it hard to cover all bases. Fortunately, most NLP tools have this NER capability that is out of the box. For example, Natural Language Toolkit (NLTK) has Named Entity Chunkers, and spaCy has Matcher.
Matcher allows you to define patterns based on linguistic features like part-of-speech tags or specific keywords. These patterns can be matched against the rental descriptions to identify relevant keywords and phrases. This approach captures single words (like, Tokyo) and meaningful phrases (like, beautiful house) that better represent the selling points of a property.
noun_phrases_patterns = [
[{'POS': 'NUM'}, {'POS': 'NOUN'}], #example: 2 bedrooms
[{'POS': 'ADJ', 'OP': '*'}, {'POS': 'NOUN'}], #example: beautiful house
[{'POS': 'NOUN', 'OP': '+'}], #example: house
]
# Geo-political entity
gpe_patterns = [
[{'ENT_TYPE': 'GPE'}], #example: Tokyo
]
# Proximity
proximity_patterns = [
# example: near airport
[{'POS': 'ADJ'}, {'POS': 'ADP'}, {'POS': 'NOUN', 'ENT_TYPE': 'FAC', 'OP': '?'}],
# example: near to Narita
[{'POS': 'ADJ'}, {'POS': 'ADP'}, {'POS': 'PROPN', 'ENT_TYPE': 'FAC', 'OP': '?'}]
]
3c. Level: Advanced — Deep Learning-Based Matcher
Even with Matcher, some terms may not be captured by rule-based matching due to the context of the words in the sentence. For example, the Matcher might miss a term like ‘a stone’s throw away from Ueno Park’ since it won’t pass any predefined patterns, or mistake “Shinjuku Kabukicho” as a person (it’s a neighborhood, or LOC).
In such cases, deep-learning-based approaches can be more effective. By training on a large corpus of rental listing with associated keywords these model learn the semantic relationships between words. This makes this method more adaptable to evolving language use and can uncover hidden insights.
Using spaCy, performing deep-learning-based NER is straightforward. However, the major building block for this method is usually the availability of the labeled training data, as also the case for this exercise. The label is a pair of the target terms and the entity name (example: ‘a stone throw away’ is a noun phrase — or as shown in picture: Shinjuku Kabukicho is a LOC, not a person), formatted in a certain way. Unlike rule-based where we describe the terms into noun, location, and others from the built-in functionality, data exploration or domain expert are needed to discover the target terms that we want to identify.
Part 2 of the article will discuss this technique of discovering themes or labels from the data for topic modeling using clustering, bootstrapping, and other methods.
4. Serving Suggestions
Extracted keywords are valuable for both backend and frontend applications. We can use them for various downstream analyses, such as theme and topic exploration (discussed in Part 2). On the front end, these keywords can empower users to find listings with similar characteristics — think of them like hashtags on Instagram or Twitter (but automatic!). You can also highlight and display these keywords or make them clickable. For example, named entity recognition (NER) can identify locations like “Iidabashi” or “Asakusa.” When a user hovers over these keywords, a pop-up can display relevant information about those places.
Summaries provide a concise overview of the listing, making them ideal for quickly grasping the key details, or for mobile displays.

Moving Forward
In this article, we demonstrated the practical implementation of various NLP techniques, such as text summarization and named entity recognition (NER) on a rental listing dataset. These techniques can significantly improve user experience by providing concise, informative, and easily searchable rental listings.
In the upcoming article (Part 2), we will use methods like clustering to discover hidden themes and labels. This will allow us to build a robust model that can act as a recommender engine. We will also explore advanced NLP techniques like topic modeling and text classification further to enhance the analysis and usability of rental listing descriptions.
以上です★これからもうよろしくおねがいします☆また今度。
Note:
1) Github Repository: https://github.com/kristiyanto/nlp_on_airbnb_dataset
2) Data (Creative Commons Attribution 4.0 International License): https://insideairbnb.com/get-the-data/
3) All images in this article are produced by the author.
NLP: Text Summarization and Keyword Extraction on Property Rental Listings — Part 1 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
NLP: Text Summarization and Keyword Extraction on Property Rental Listings — Part 1