Overview of PPCA, an extension of classical PCA, and its application to incomplete data via the EM Algorithm
Probabilistic Principal Components Analysis (PPCA) is a dimensionality reduction technique that leverages a latent variable framework to recover the directions of maximal variance in the data. When the noise follows an Isotropic Gaussian distribution, the probabilistic principal components will be closely related to the classical principal components, identical up to a scaling factor and an orthogonal rotation. PPCA can thus be used for many of the same applications as classical PCA, such as data visualization and feature extraction. The latent variable framework behind PPCA also offers functionality which classical PCA does not. For instance, PPCA can easily be extended to accommodate data with missing values, whereas classical PCA is undefined on incomplete data.
PPCA can be implemented using a number of different methods. Tipping and Bishop provided an implementation of PPCA via the EM algorithm in their original 1999 article; however, they did not explicitly show how the EM algorithm for PPCA extends to incomplete data. A previous article on Towards Data Science discussed an alternative approach to PPCA, which uses variational inference in place of the EM algorithm to impute missing values and derive the probabilistic principal components. This approach starts from the simplifying assumption that the standard deviation of the noise is known in advance, an assumption which makes it easier to optimize the variational distribution but is not representative of most applications. For this post, I will focus on the EM algorithm, expanding upon previous discussions by illustrating all of the steps needed to extend Tipping and Bishop’s EM algorithm for PPCA to incomplete data.
Overview of PPCA and its Relationship to Classical PCA:
Classical PCA is a deterministic method which does not model the data in terms of distinct signal and noise components. By contrast, PPCA is derived from a probabilistic model of the form
where z_i is a vector of q unobserved latent variables, W is a loading matrix that maps the q latent variables into the p observed variables, and epsilon_i is a noise term which makes the procedure probabilistic rather than deterministic. It’s typically assumed that z_i follows a standard normal distribution. The noise term, epsilon_i, must follow an Isotropic Gaussian distribution with mean zero and a covariance matrix of the form sigma ^2 I for the relationship between PPCA and classical PCA to hold.
Under this latent variable model, Tipping and Bishop (1999) have shown that the directions of maximal variance in the data can be recovered through maximum likelihood estimation. They prove that the MLEs for W and sigma are given by
Here, U_q is the matrix whose columns are the q principal eigenvectors of the sample covariance matrix, Lambda_q is a diagonal matrix of the eigenvalues corresponding to the q principal eigenvectors, and R is an arbitrary orthogonal rotation matrix. Note that the classical principal components are given by the matrix U_q. As a result of the other terms in the expression for W_MLE, the probabilistic principal components may have different scalings and different orientations than the classical components, but both sets of components will span the same subspace and can be used interchangeably for most applications requiring dimensionality reduction.
In practice, the identity matrix can be substituted for the arbitrary orthogonal matrix R to calculate W_MLE. Using the identity matrix not only reduces the computational complexity but also ensures that there will be a perfect correlation or anti-correlation between the probabilistic principal components and their classical counterparts. These closed-form expressions are very convenient for complete data, but they cannot directly be applied to incomplete data. An alternative option for finding W_MLE, which can easily be extended to accommodate incomplete data, is to use the EM algorithm to iteratively arrive at the maximum likelihood estimators, in which case R will be arbitrary at convergence. I’ll briefly review the EM algorithm below before illustrating how it can be used to apply PPCA to incomplete data.
EM Algorithm for PPCA with Missing Data:
The EM algorithm is an iterative optimization method which alternates between estimating the latent variables and updating the parameters. Initial values must be specified for all parameters at the beginning of the EM algorithm. In the E-Step, the expected value of the log-likelihood is computed with respect to the current parameter estimates. The parameter estimates are then re-calculated to maximize the expected log-likelihood function in the M-Step. This process repeats until the change in the parameter estimates is small and the algorithm has thus converged.
Before illustrating how the EM algorithm for PPCA extends to incomplete data, I will first introduce some notation. Suppose that we observe D different combinations of observed and unobserved predictors in the data. The set of D combinations will include the pattern where all predictors are observed, assuming the data contains at least some complete observations. For each distinct combination d=1,…,D, let x_1,…,x_n_d denote the set of observations which share the dth pattern of missing predictors. Each data point in this set can be decomposed as
where the subscripts obs_d and mis_d denote which predictors are observed and unobserved in the dth combination.

The algorithm in the image above shows all of the steps needed to apply PPCA to incomplete data, using my notation for observed and unobserved values. To initialize the parameters for the EM algorithm, I impute any missing values with the predictor means and then use the closed-form estimators given by Tipping and Bishop (1999). The mean-imputed estimates may be biased, but they provide a more optimal starting point than a random initialization, reducing the likelihood of the algorithm converging to a local minimum. Note that the imputed data is not used beyond the initialization.
In the E-step, I first compute the expectation of each z_i with respect to the observed values and the current parameter estimates. Then I treat the missing values as additional latent variables and compute their expectation with respect to the current parameters and z_i. In the M-step, I update the estimates for W, mu, and sigma based on the expected log-likelihood that was computed in the E-Step. This differs from Tipping and Bishop’s EM algorithm for complete data, where mu is estimated based on the sample mean and only W and sigma are iteratively updated in the EM algorithm. It is not necessary to iteratively estimate mu when X is complete or when the unobserved values are missing completely at random since the sample mean is the MLE. For other patterns of missingness, however, the mean of the observed values is generally not the MLE, and the EM algorithm will yield more accurate estimates of mu by accounting for the likely values of the missing data points. Thus, I’ve included the update for mu in the M-Step along with the other parameter updates.
Python Implementation:
I have provided an implementation of the EM algorithm for PPCA here, following the steps of the algorithm above to accommodate missing data. My function requires the user to specify the data matrix and the number of components in PPCA (i.e., q, the latent variable dimension). Common techniques for selecting the number of components in classical PCA can also be applied to PPCA when the latent variable dimension is not known. For instance, one option for selecting q would be to create a scree plot and apply the so-called ‘elbow method.’ Alternatively, q could be chosen through cross-validation.
I will now consider three different simulations to test my implementation of the EM algorithm for PPCA: one without any missing values, one with missing values that are selected completely at random, and one with missing values that are selected not-at-random. To simulate data that is missing completely at random, I assume that each of the nxp values has an equal 10% chance of being unobserved. Meanwhile, to simulate data that is missing not-at-random, I assume that data points with a higher z-score have a greater chance of being unobserved, with an expected proportion of 10% missing overall.
I use the same synthetic data for all simulations, simply altering the pattern of missingness to assess the performance on incomplete data. To generate the data, I let n=500, p=30, and q=3. I sample both W and mu from a Uniform[-1, 1] distribution. Then I draw the latent variables z_i, i=1,…,n from a standard normal distribution and the noise terms epsilon_i, i=1,…,n, from an Isotropic Gaussian distribution with sigma=0.7. I assume that q is correctly specified in all simulations. For additional details, see the simulation code here.
To evaluate the accuracy of the EM algorithm, I report the relative error of the parameter estimates. The relative error for mu is reported with respect to the l2 norm, and the relative error for W is reported with respect to the Frobenius norm. Since W can only be recovered up to an orthogonal rotation, I have used NumPy’s orthogonal prosecutes function to rotate the estimated matrix W in the direction of the true W before computing the relative error.
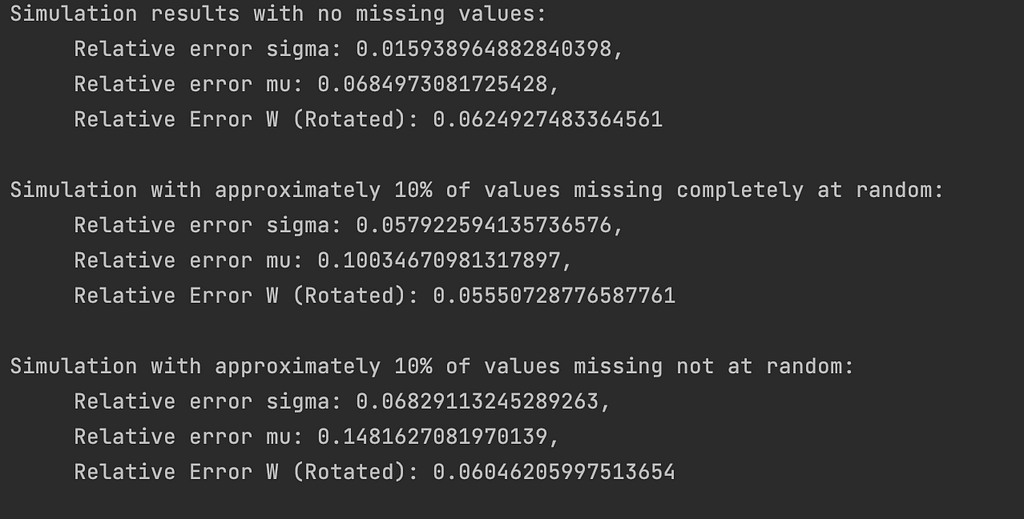
My results confirm that the EM algorithm can accurately estimate the parameters in all three of these setups. It is not surprising that the EM algorithm performs well in the complete data simulation since the initialization should already be optimal. However, it is more noteworthy that the accuracy remains high when missing values are introduced. The parameter estimates even show a relatively high degree of robustness to non-random patterns of missingness, at least under the assumed setup for this simulation. For real datasets, the performance of the EM algorithm will depend on a number of different factors, including the accuracy of the initialization, the pattern of missingness, the signal to noise ratio, and the sample size.
Conclusion:
Probabilistic principal components analysis (PPCA) can recover much of the same structure as classical PCA while also extending its functionality, for instance, by making it possible to accommodate data with missing values. In this article, I have introduced PPCA, explored the relationship between PPCA and classical PCA, and illustrated how the EM algorithm for PPCA can be extended to accommodate missing values. My simulations indicate that the EM algorithm for PPCA yields accurate parameter estimates when there are missing values, even demonstrating some robustness when values are missing not-at-random.
References:
M. Tipping, C. Bishop, Probabilistic principal component analysis (1999). Journal of the Royal Statistical Society Series B: Statistical Methodology.
Principal Components Analysis (PCA) Through a Latent Variable Lens was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Principal Components Analysis (PCA) Through a Latent Variable Lens
Go Here to Read this Fast! Principal Components Analysis (PCA) Through a Latent Variable Lens