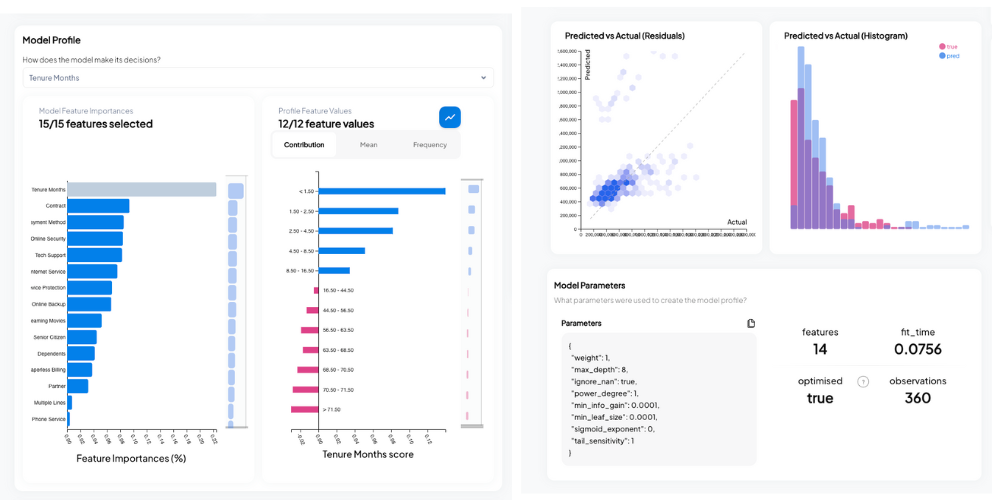
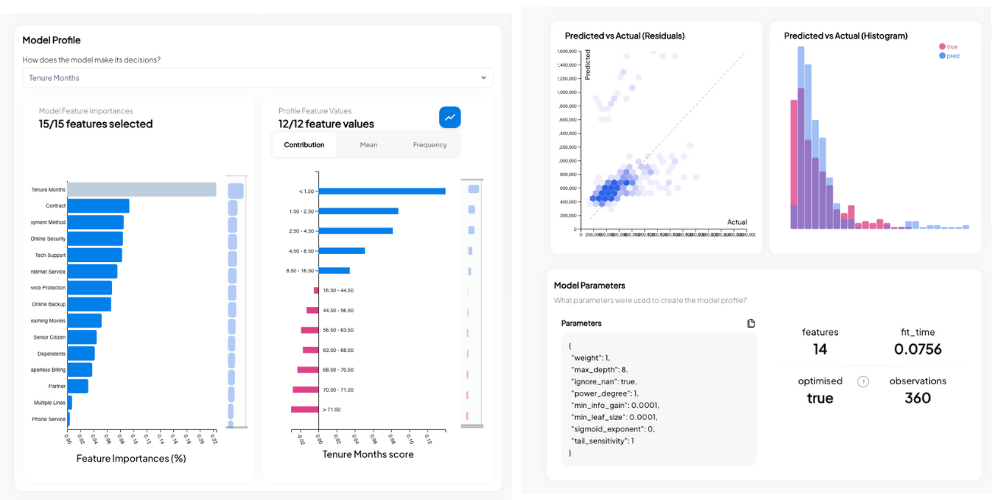
These are terms commonly used to describe the transparency of a model, but what do they really mean?
Machine Learning (ML) has become increasingly prevalent across various industries due to its ability to generate accurate predictions and actionable insights from large datasets. Globally, 34% of companies have deployed ML, reporting significant improvements to customer retention, revenue growth, and cost efficiencies (IBM, 2022). This surge in machine learning adoption can be attributed to more accessible models that produce results with higher accuracies, surpassing traditional business methods in several areas.
However, as machine learning models become more complex, yet further relied upon, the need for transparency becomes increasingly important. According to IBM’s Global Adoption Index, 80% of businesses cite the ability to determine how their model arrived at a decision as a crucial factor. This is especially important in industries such as healthcare and criminal justice, where trust and accountability in both the models and the decisions they make are vital. Lack of transparency is likely a limiting factor preventing the widespread use of ML in these sectors, potentially hindering significant improvements in operational speed, decision-making processes, and overall efficiencies.
Three key terms — explainability, interpretability, and observability — are widely agreed upon as constituting the transparency of a machine learning model.
Despite their importance, researchers have been unable to establish rigorous definitions and distinctions for each of these terms, stemming from the lack of mathematical formality and an inability to measure them by a specific metric (Linardatos et al., 2020).
Explainability
Explainability has no standard definition, but rather is generally accepted to refer to “the movement, initiatives, and efforts made in response to AI transparency and trust concerns” (Adadi & Berrada, 2018). Bibal et al. (2021) aimed to produce a guideline on the legal requirements, concluding that an explainable model must be able to “(i) [provide] the main features used to make a decision, (ii) [provide] all the processed features, (iii) [provide] a comprehensive explanation of the decision and (iv) [provide] an understandable representation of the whole model”. They defined explainability as providing “meaningful insights on how a particular decision is made” which requires “a train of thought that can make the decision meaningful for a user (i.e. so that the decision makes sense to him)”. Therefore, explainability refers to the understanding of the internal logic and mechanics of a model that underpin a decision.
A historical example of explainability is the Go match between AlphaGo, a algorithm, and Lee Sedol, considered one of the best Go players of all time. In game 2, AlphaGo’s 19th move was widely regarded by experts and the creators alike as “so surprising, [overturning] hundreds of years of received wisdom” (Coppey, 2018). This move was extremely ‘unhuman’, yet was the decisive move that allowed the algorithm to eventually win the game. Whilst humans were able to determine the motive behind the move afterward, they could not explain why the model chose that move compared to others, lacking an internal understanding of the model’s logic. This demonstrates the extraordinary ability of machine learning to calculate far beyond human ability, yet raises the question: is this enough for us to blindly trust their decisions?
Whilst accuracy is a crucial factor behind the adoption of machine learning, in many cases, explainability is valued even above accuracy.
Doctors are unwilling, and rightfully so, to accept a model that outputs that they should not remove a cancerous tumour if the model is unable to produce the internal logic behind the decision, even if it is better for the patient in the long run. This is one of the major limiting factors as to why machine learning, even despite its immense potential, has not been fully utilised in many sectors.
Interpretability
Interpretability is often considered to be similar to explainability, and is commonly used interchangeably. However, it is widely accepted that interpretability refers to the ability to understand the overall decision based on the inputs, without requiring a complete understanding of how the model produced the output. Thus, interpretability is considered a broader term than explainability. Doshi-Velez and Kim (2017) defined interpretability as “the ability to explain or to present in understandable terms to a human”. Another popular definition of interpretability is “the degree to which a human can understand the cause of a decision” (Miller, 2019).
In practice, an interpretable model could be one that is able to predict that images of household pets are animals due to identifiable patterns and features (such as the presence of fur). However this model lacks the human understanding behind the internal logic or processes that would make the model explainable.
Whilst many researchers use intepretability and explainability in the same context, explainability typically refers to a more in-depth understanding of the model’s internal workings.
Doshi-Velez and Kim (2017) proposed three methods of evaluating interpretability. One method is undergoing application level evaluation. This consists of ensuring the model works by evaluating it with respect to the task against domain experts. One example would be comparing the performance of a CT scan model against a radiologist with the same data. Another method is human level evaluation, asking laypeople to evaluate the quality of an explanation, such as choosing which model’s explanation they believe is of higher quality. The final method, functionally-grounded evaluation, requires no human input. Instead, the model is evaluated against some formal definition of interpretability. This could include demonstrating the improvement in prediction accuracy for a model that has already been proven to be interpretable. The assumption is that if the prediction accuracy has increased, then the interpretability is higher, as the model has produced the correct output with foundationally solid reasoning.
Observability
Machine learning observability is the understanding of how well a machine learning model is performing in production. Mahinda (2023) defines observability as a “means of measuring and understanding a system’s state through the outputs of a system”, further stating that it “is a necessary practice for operating a system and infrastructure upon which the reliability would depend”. Observability aims to address the underlying issue that a model that performs exceptionally in research and development may not be as accurate in deployment. This discrepancy is often due to factors such as differences between real-world data the model encounters and the historical data the it was initially trained upon. Therefore, it is crucial to maintain continuous monitoring of inputted data and the model performance. In industries that deal with high stake issues, ensuring that a model will perform as expected is a crucial prerequisite for adoption.
Observability is a key aspect of maintaing model performance under real-world conditions.
Observability is comprised of two main methods, monitoring and explainability (A Guide to Machine Learning Model Observability, n.d.).
Many metrics can be used to monitor a models performance during deployment, such as precision, F1 score and AUC ROC. These are typically set to alert whenever a certain value is reached, allowing for a prompt investigation into the root cause of any issues.
Explainability is a crucial aspect of observability. Understanding why a model performed poorly on a dataset is important to be able to refine the model to perform more optimally in the future under similar situations. Without an understanding of the underlying logic that was used to form the decision, one is unable to improve the model.
Conclusion
As machine learning continues to become further relied upon, the importance of transparency in these models is a crucial factor in ensuring trust and accountability behind their decisions.
Explainability allows users to understand the internal logic of ML models, fostering confidence behind the predictions made by the models. Interpretability ensures the rationale behind the model predictions are able to be validated and justified. Observability provides monitoring and insights into the performance of the model, aiding in the prompt and accurate detection of operation issues in production environments.
Whilst there is significant potential for machine learning, the risks associated with acting based on the decisions made by models we cannot completely understand should not be understated. Therefore, it is imperative that explainability, interpretability and observability are prioritised in the development and integration of ML systems.
The creation of transparent models with high prediction accuracies has and will continue to present considerable challenges. However the pursuit will result in responsible and informed decision-making that significantly surpasses current models.
Explainability, Interpretability and Observability in Machine Learning was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Explainability, Interpretability and Observability in Machine Learning
Go Here to Read this Fast! Explainability, Interpretability and Observability in Machine Learning