OMOP & DataSHIELD: A Perfect Match to Elevate Privacy-Enhancing Healthcare Analytics?
Exploring synergies between DataSHIELD and OHDSI/OMOP for collaborative healthcare analytics
Context
Cross-border or multi-site data sharing can be challenging due to variations in regulations and laws, as well as concerns around data privacy, security, and ownership. However, there is a growing demand for conducting
large-scale cross-country and multi-site clinical studies to generate more robust and timely evidence for better healthcare. To address this, the Federated Open Science team at Roche believes in Federated Analytics (privacy-enhancing decentralized statistical analysis) as a promising solution to facilitate more multi-site and data-driven collaborations.
The availability and accessibility of high-quality (curated) patient-level data remains a persistent bottleneck to progress. A federated model is one of the enablers for collaborative analytics and machine learning in the medical domain without moving any sensitive patient-level data.
Federated model for analytics
The idea of the federated paradigm is to bring analysis to the data, not data to the analysis.
That means that data remains within the boundaries of its respective organizations and collaborative analytical effort does not mean copying the data outside local infrastructure nor giving unlimited access to queries against the data.
It has many advantages including:
- Reduced data exposure risk
- No data copies that are hard to track and manage leave premises
- Avoiding the up front cost and effort of building data lakes
- Crossing regulatory boundaries
- Interactive way of trying different analytical approaches and functions
Let’s use a simplified example of diabetes patients from three different hospitals. Let’s say the external data scientist would like to analyze the mean age of patients.
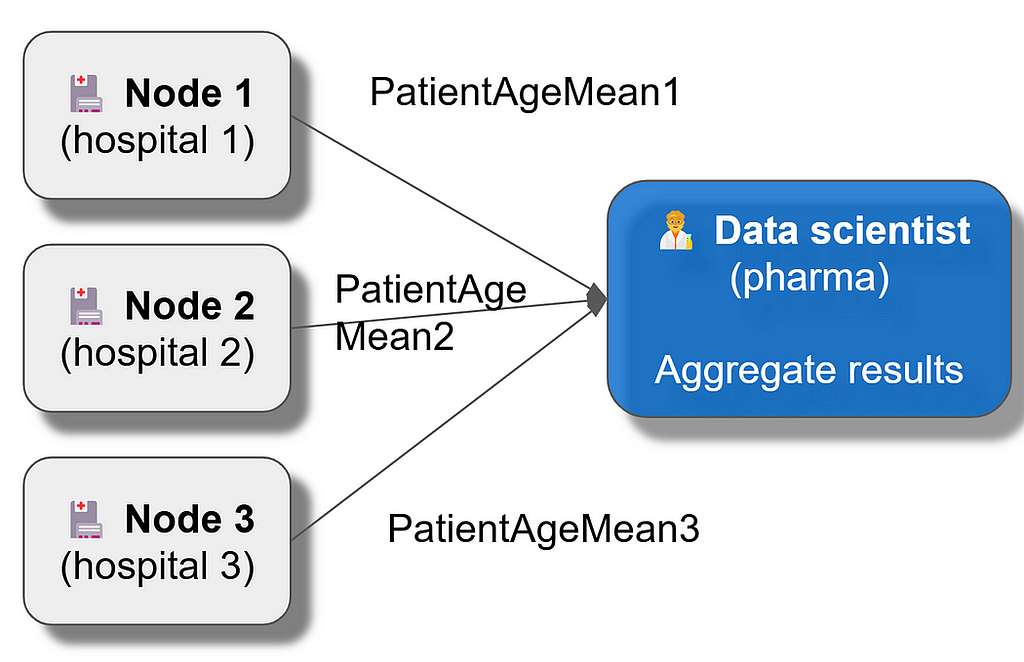
Remote data scientists are not fully trusted by the data owners, are not supposed to access the data, have no access to any row level data and cannot send any query they like (such as DataFrame.get) but they can call federated functions and get aggregated mean values in the network.
Data owners enable remote data scientists to run federated function mean against the specified cohorts and variables (for example Age).
Such advanced analytical capabilities are a great added value and support when conducting observational studies to e.g. assess treatment effectiveness in diverse populations across regions.
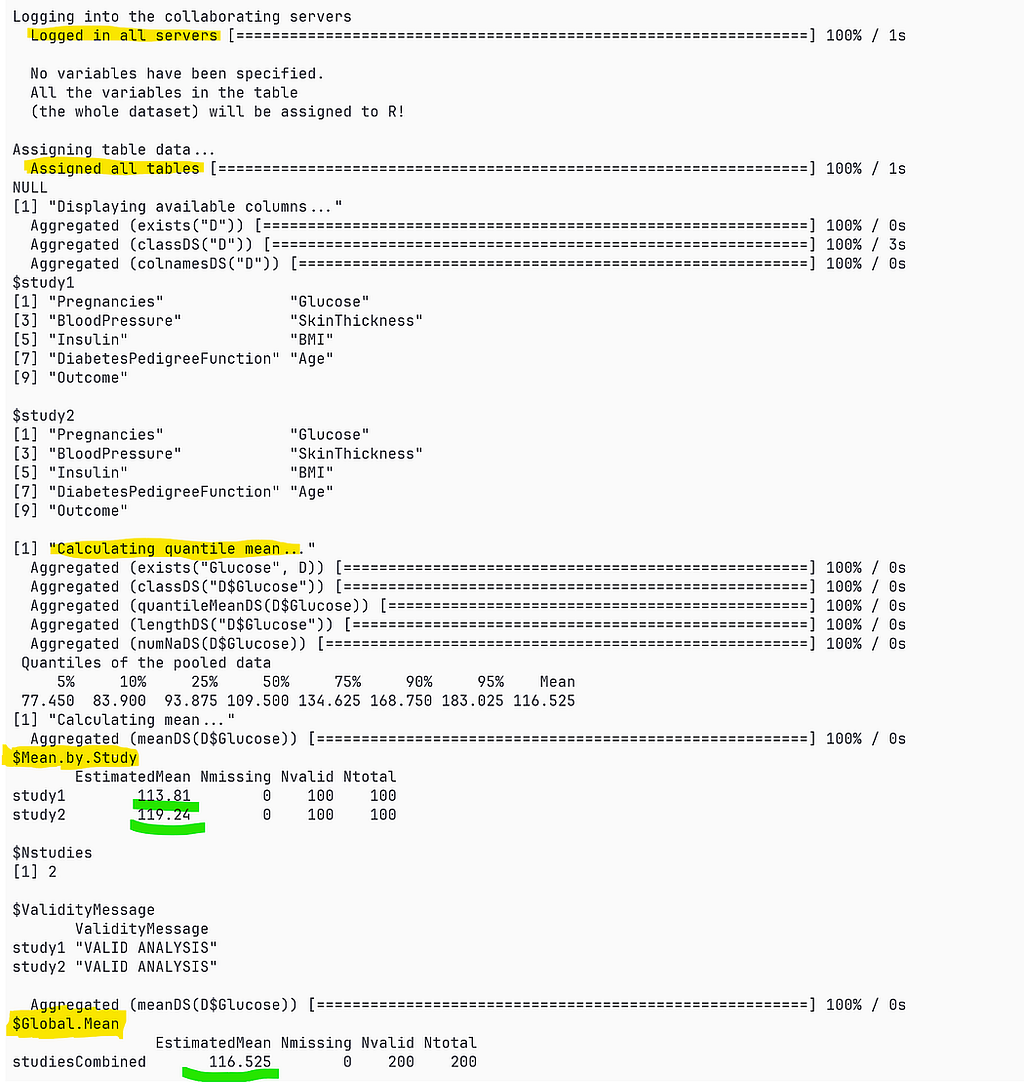
This is how it looks from the data scientist perspective who uses a popular Federated Analytics solution called DataSHIELD.
DataSHIELD what is it?
DataSHIELD is a system to allow you to analyze sensitive data without viewing it or deducing any revealing information about the subjects contained therein.
It is driven from the academic DataSHIELD project (University Liverpool) and from obiba.org (McGill University).
It’s an open source solution available on GitHub, which helps with trust and transparency, as this code is running behind firewalls inside data owner infrastructure.
It’s more than ten years on the market and was used in multiple successful projects.
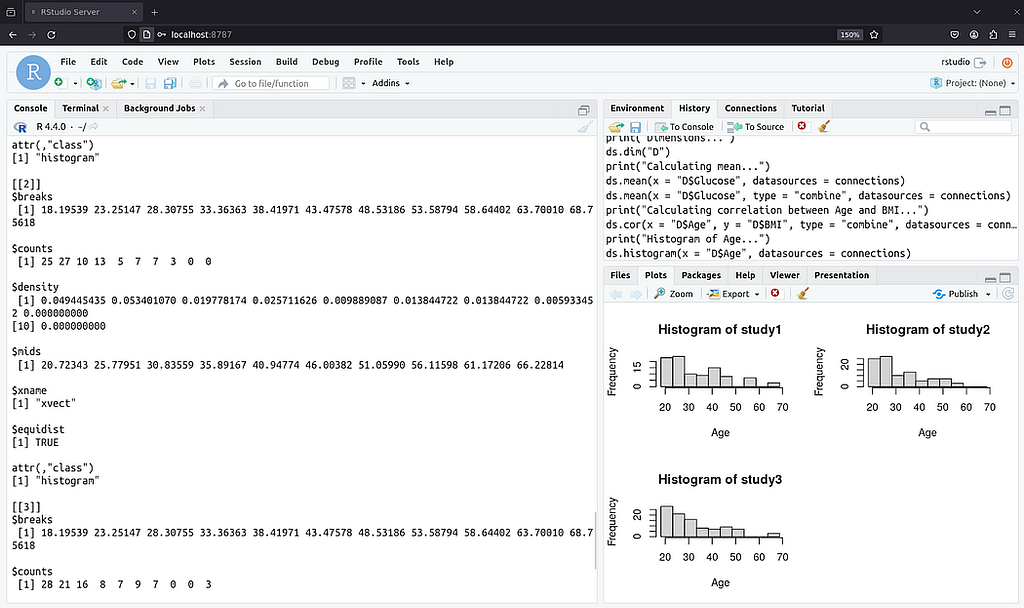
The main advantages of DataSHIELD are:
- Advanced federated analytical functions with disclosure checks and smart aggregation of the results
- Federated authentication and authorization, empowering data owners to be in full control of who does what against their data
- APIs for automation of all the parts of the architecture
- Built-in extensibility mechanism to create custom federated functions
- Community packages of additional functions
- Full transparency, all the code available on GitHub
Data owners are responsible for:
- Deploying local DataSHIELD Opal and Rock node in their infrastructure
- Managing users, permissions (functions to variables)
- Configuration of disclosure check filters
- Review and acceptance of custom functions and their local deployment
Data analysts are:
- Calling federated functions and aggregating the results, usually with high accuracy instead of meta-analysis, always with data disclosure protection
- Writing and testing their custom federated functions which then are shared with the network to be deployed in all the nodes by data owners and then used in collaborative analytical efforts
The Observational Health Data Sciences and Informatics advantages
OHDSI is best known for their data harmonization and standardization known as Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM).
The current version of the standard is 5.4, while it’s evolving to accommodate the feedback from real world applications and new requirements, it’s already mature and supported by tools from OHDSI ecosystem such as ATLAS, HADES and Strategus.
The OHDSI stack is more than ten years old with many successful practical implementations.
OHDSI does not require hospitals and other data sources to expose their data nor APIs to the internet so the analysis may be performed by delivering analysis specification to the data owner who executes analytical queries and algorithms, reviews outputs and sends them over secure channels to the analytical side. OHDSI provides end to end tools to support all the steps of this workflow.
Business value of integration
DataSHIELD, while it requires connectivity to its analytical server APIs (Opal), enables interactive ways of analyzing data while preserving data privacy using a set of non-disclosive analytical functions and built-in advanced disclosure checks.
This makes the analysis more agile, exploratory (to an extent), and enables data analysts to try different analytical methods to learn from data.
In case of traditional OHDSI approach the code is fixed in defined study definition and is executed manually by data owners. This leads to longer wait times to get the results (human dependency) up to weeks and months depending on the particular organization. In the case of the described Federated Analytics approach the results are available within seconds.
On the other hand there’s no manual review of the results sent back to the external analysts, data owners are expected to trust built-in federated functions and disclosure checks. Also, internet connectivity is required for federated approaches.
Summary of benefits:
- DataSHIELD enables results available immediately and automatically
- built-in federated aggregation leads to improved accuracy
- disclosure protection protects raw data
- reusing investment in OMOP CDM data harmonization
- improved data quality through harmonization using OMOP → higher quality analysis results
In other words, one could get the best of both worlds for improved analytical results in real-world healthcare applications.
Integration scenarios
We, in collaboration with the DataSHIELD team, identified four main integration scenarios. Our role (Federated Open Science Team) was not only to express our interest and business justification for the integration, but to define viable integration architectures and a proof of concept definition.
Option 1. Extract, Load and Transform (ETL) data from OMOP CDM data source to DataSHIELD data store (at start of project).
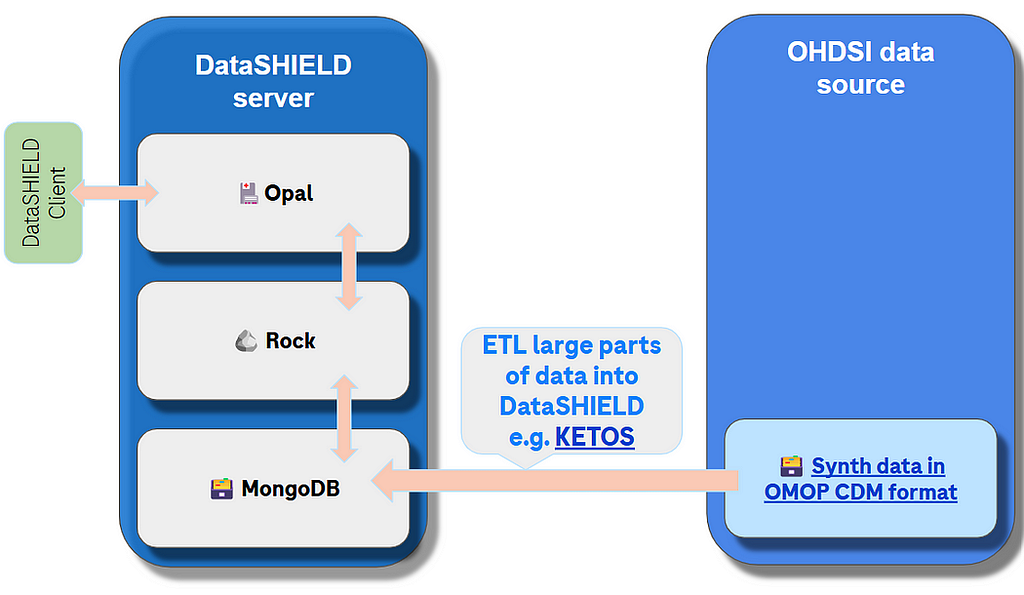
In this approach we use the classical ETL approach to extract data from OHDSI data source and transform it into data that is going to become data source, then add it as a resource or import directly to the DataSHIELD Opal server.
Option 2. OMOP CDM as a natively supported data source in DataSHIELD.

DataSHIELD supports various data sources (flat files such as CSV, structured data such as XML, JSON, relational databases, and others) but does not provide direct support for OHDSI OMOP CDM data source.
The goal of dsOMOP library (under development) is to provide extension to DataSHIELD to provide first class support for OMOP CDM data sources.
Option 3. Use REST API to retrieve subsets of data as needed.
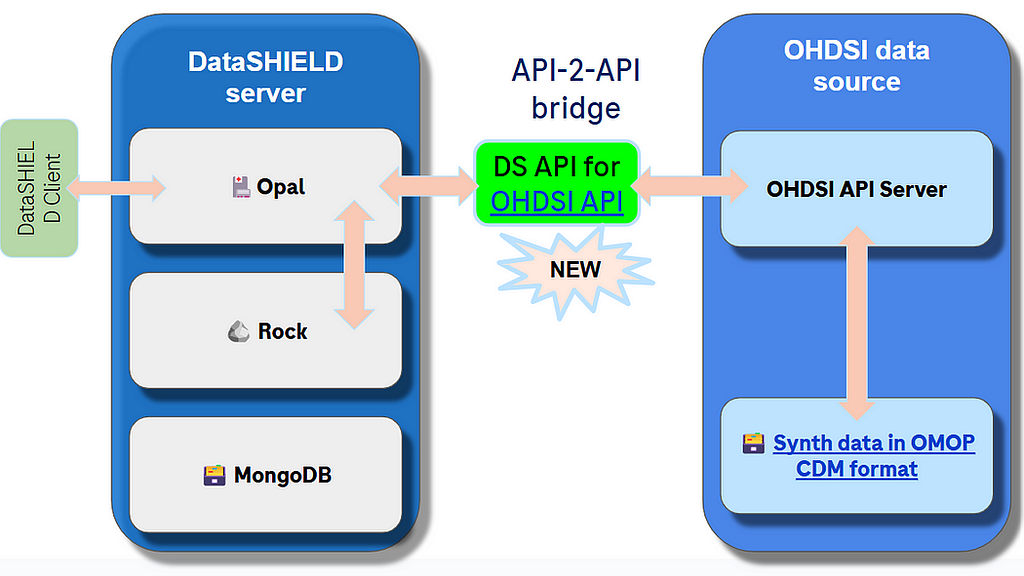
This option does not bypass API layers of OHDSI stack and works as DataSHIELD API to OHDSI tools API bridge, orchestration and translation layer.
Option 4. Embed DataSHIELD in OHDSI stack.
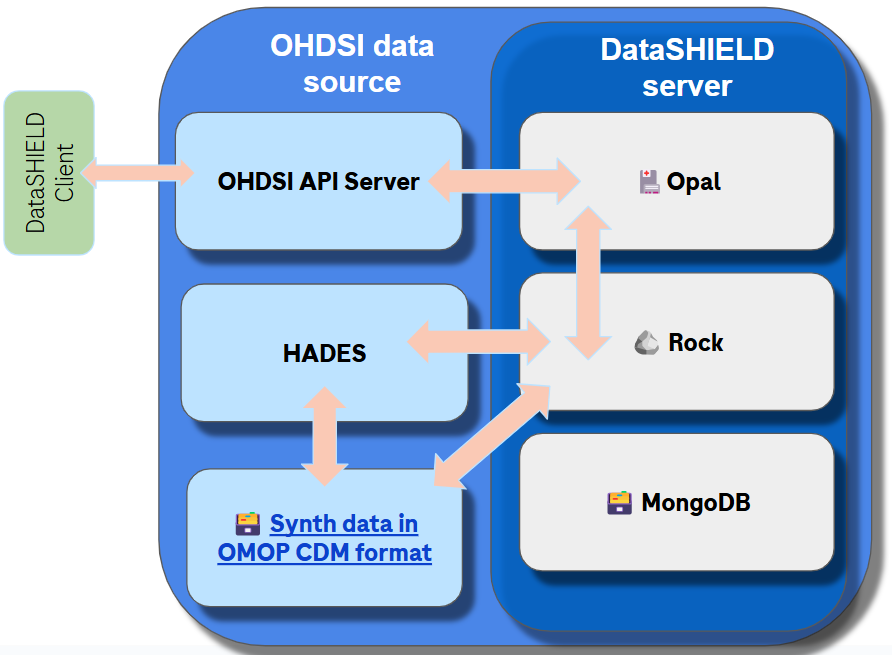
This means deep integration of both ecosystems to maximize the benefits, at the expense of the high effort and coordination between two teams (DataSHIELD and OHDSI technology teams).
Adoption barriers
Both solutions and communities have a track record of successful analytical projects using their respective tools and approaches. There were limited attempts in the past on the DataSHIELD side to embrace OMOP CDM and query libraries (i.e. GitHub — sib-swiss/dsSwissKnife, early https://github.com/isglobal-brge/dsomop).
The main problem we try to address is the continued limited awareness of the federated model, which we gladly presented at the OHDSI Europe 2024 Symposium in Rotterdam with very positive feedback, recognizing the benefits of future integration. Hands-on demonstrations of how Federated Analytics works from a data analyst perspective were very helpful to convey the message. The main question asked about the planned integration was “when” not “why”, we perceive that as a good sign and encouragement for the future.
Both technology ecosystems (DataSHIELD, OHDSI) are mature, however their integration is under development (as of June 2024) and not production ready yet. DataSHIELD can be and is used without OMOP CDM and while the problem of data quality and harmonization are recognized, OMOP was never a direct requirement nor guidance for federated projects.
The value of federated networks also could be higher if the projects were focused more on longer term collaborations instead of one-off analysis, the initial cost of building the networks (from all the perspectives) could be reused when there would be more than a single study executed in the consortia. There are signs of progress in this area, while the majority of the federated projects are single study projects.
Future steps
Our views on the potential and future of the integration of OHDSI and DataSHIELD are optimistic. This is what industry expects to happen and was well received by both communities.
The development of dsOMOP R libraries for DataSHIELD has accelerated recently.
The results are expected to deliver an end to end solution for the data source integration (strategy number 2) and allow further development and closer collaboration of both ecosystems. Practical applications of the expected integration are always the best way to gather invaluable feedback and detect issues.
The author would like to thank Jacek Chmiel for significant impact on the blog post itself, as well as the people who helped shaping this effort: Jacek Chmiel, Rebecca Wilson, Olly Butters and Frank DeFalco and the Federated Open Science team at Roche.
OMOP & DataSHIELD: A perfect match to elevate privacy-enhancing healthcare analytics? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.