Transforming customer data into actionable insights with RFM segmentation

Part 1: RFM Segmentation
The methods vary when we talk about customer segmentation. Well, it depends on what we aim to achieve, but the primary purpose of customer segmentation is to put customers in different kinds of groups according to their similarities. This method, in practical applications, will help businesses specify their market segments with tailored marketing strategies based on the information from the segmentation.
RFM segmentation is one example of customer segmentation. RFM stands for recency, frequency, and monetary. This technique is prevalent in commercial businesses due to its straightforward yet powerful approach. According to its abbreviation, we can define each metric in RFM as follows:
- Recency (R): When was the last time customers made a purchase? Customers who have recently bought something are more inclined to make another purchase, unlike customers who haven’t made a purchase in a while.
- Frequency (F): How often do customers make purchases? Customers who buy frequently are seen as more loyal and valuable.
- Monetary (M): How much money a customer spends? We value customers who spend more money as they are valuable to our business.
The workflow of RFM segmentation is relatively straightforward. First, we collect data about customer transactions in a selected period. Please ensure we already know when the customer is transacting, how many quantities of particular products the customer buys in each transaction, and how much money the customer spends. After that, we will do the scoring. There are so many thresholds available for us to consider, but how about we opt for a scale ranging from 1 to 5 to evaluate each —where 1 represents the lowest score while 5 stands for the highest score. In the final step, we combine the three scores to create customer segments. For example, the customer who has the highest RFM score (5 in recency, frequency, and monetary) is seen as loyal, while the customer with the lowest RFM score (1 in recency, frequency, and monetary) is seen as a churning user.
In the following parts of the article, we will create an RFM segmentation utilizing a popular unsupervised learning technique known as K-Means.
Part 2: Practical Example
We don’t need to collect the data in this practical example because we already have the dataset. We will use the Online Retail II dataset from the UCI Machine Learning Repository. The dataset is licensed under CC BY 4.0 and eligible for commercial use. You can access the dataset for free through this link.
The dataset has all the information regarding customer transactions in online retail businesses, such as InvoiceDate, Quantity, and Price. There are two files in the dataset, but we will use the “Year 2010–2011” version in this example. Now, let’s do the code.
Step 1: Data Preparation
The first step is we do the data preparation. We do this as follows:
# Load libraries
library(readxl) # To read excel files in R
library(dplyr) # For data manipulation purpose
library(lubridate) # To work with dates and times
library(tidyr) # For data manipulation (use in drop_na)
library(cluster) # For K-Means clustering
library(factoextra) # For data visualization in the context of clustering
library(ggplot2) # For data visualization
# Load the data
data <- read_excel("online_retail_II.xlsx", sheet = "Year 2010-2011")
# Remove missing Customer IDs
data <- data %>% drop_na(`Customer ID`)
# Remove negative or zero quantities and prices
data <- data %>% filter(Quantity > 0, Price > 0)
# Calculate the Monetary value
data <- data %>% mutate(TotalPrice = Quantity * Price)
# Define the reference date for Recency calculation
reference_date <- as.Date("2011-12-09")
The data preparation process is essential because the segmentation will refer to the data we process in this step. After we load the libraries and load the data, we perform the following steps:
- Remove missing customer IDs: Ensuring each transaction has a valid Customer ID is crucial for accurate customer segmentation.
- Remove negative or zero quantities and prices: Negative or zero values for Quantity or Price are not meaningful for RFM analysis, as they could represent returns or errors.
- Calculate monetary value: We calculate it by multiplying Quantity and Price. Later we will group the metrics, one of them in monetary by customer id.
- Define reference date: This is very important to determine the Recency value. After examining the dataset, we know the date “2011–12–09” is the most recent date in it, so set it as the reference date. The reference date calculates how many days have passed since each customer’s last transaction.
The data will be look like this after this step:

Step 2: Calculate & Scale RFM Metrics
In this step, we’ll calculate each metric and scale those before the clustering part. We do this as follows:
# Calculate RFM metrics
rfm <- data %>%
group_by(`Customer ID`) %>%
summarise(
Recency = as.numeric(reference_date - max(as.Date(InvoiceDate))),
Frequency = n_distinct(Invoice),
Monetary = sum(TotalPrice)
)
# Assign scores from 1 to 5 for each RFM metric
rfm <- rfm %>%
mutate(
R_Score = ntile(Recency, 5),
F_Score = ntile(Frequency, 5),
M_Score = ntile(Monetary, 5)
)
# Scale the RFM scores
rfm_scaled <- rfm %>%
select(R_Score, F_Score, M_Score) %>%
scale()
We divide this step into three parts:
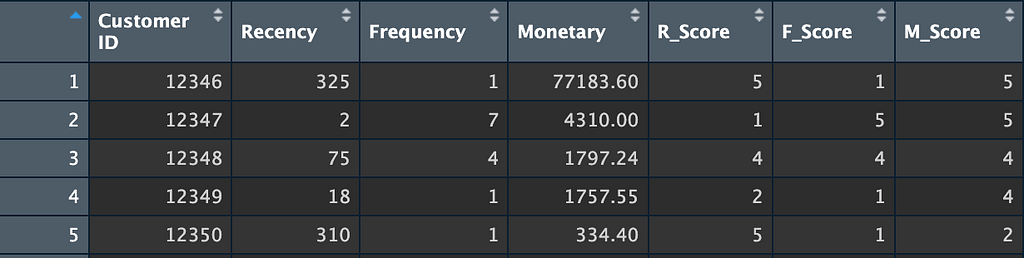
- Calculate RFM metrics: We make a new dataset called RFM. We start by grouping by CustomerID so that each customer’s subsequent calculations are performed individually. Then, we calculate each metric. We calculate Recency by subtracting the reference date by the most recent transaction date for each customer, Frequency by counting the number of unique Invoice for each customer, and Monetary by summing the TotalPrice for all transactions for each customer.
- Assign scores 1 to 5: The scoring helps categorize the customers from highest to lowest RFM, with 5 being the highest and 1 being the lowest.
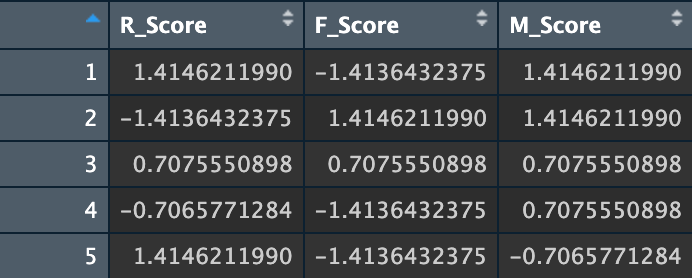
- Scale the scores: We then scale the score for each metric. This scaling ensures that each RFM score contributes equally to the clustering process, avoiding the dominance of any one metric due to different ranges or units.
After we complete this step, the result in the RFM dataset will look like this:
And the scaled dataset will look like this:
Step 3: K-Means Clustering
Now we come to the final step, K-Means Clustering. We do this by:
# Determine the optimal number of clusters using the Elbow method
fviz_nbclust(rfm_scaled, kmeans, method = "wss")
# Perform K-means clustering
set.seed(123)
kmeans_result <- kmeans(rfm_scaled, centers = 4, nstart = 25)
# Add cluster assignment to the original RFM data
rfm <- rfm %>% mutate(Cluster = kmeans_result$cluster)
# Visualize the clusters
fviz_cluster(kmeans_result, data = rfm_scaled,
geom = "point",
ellipse.type = "convex",
palette = "jco",
ggtheme = theme_minimal(),
main = "Online Retail RFM Segmentation",
pointsize = 3) +
theme(
plot.title = element_text(size = 15, face = "bold"),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
legend.title = element_text(size = 12, face = "bold"),
legend.text = element_text(size = 10)
)
The first part of this step is determining the optimal number of clusters using the elbow method. The method is wss or “within-cluster sum of squares”, which measures the compactness of the clusters. This method works by choosing the number of clusters at the point where the wss starts to diminish rapidly, and forming an “elbow.” The elbow diminishes at 4.
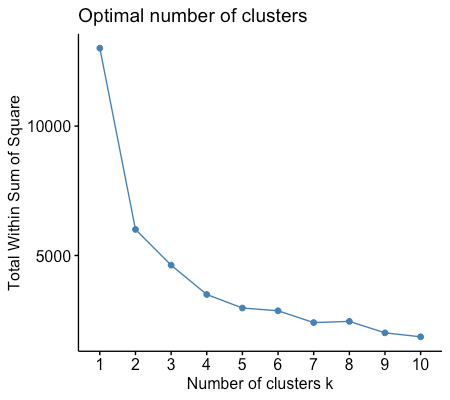
The next part is we do the clustering. We specify 4 as the number of clusters and 25 as random sets of initial cluster centers and then choose the best one based on the lowest within-cluster sum of squares. Then, add it to the cluster to the RFM dataset. The visualization of the cluster can be seen below:

Note that the sizes of the clusters in the plot are not directly related to the count of customers in each cluster. The visualization shows the spread of the data points in each cluster based on the scaled RFM scores (R_Score, F_Score, M_Score) rather than the number of customers.
Part 3: Summary
With running this code, the summary of RFM segmentation can be seen as follows:
# Summary of each cluster
rfm_summary <- rfm %>%
group_by(Cluster) %>%
summarise(
Recency = mean(Recency),
Frequency = mean(Frequency),
Monetary = mean(Monetary),
Count = n()
)
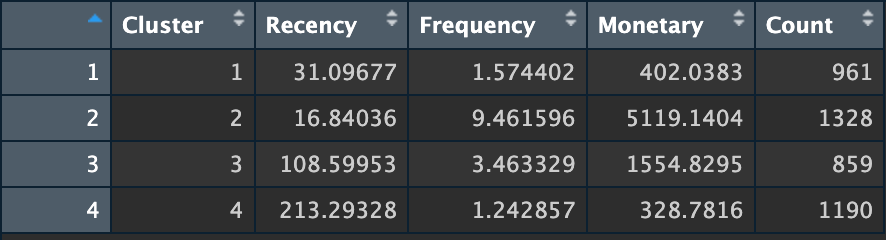
From the summary, we can get generate insights from each cluster. The suggestions will vary greatly. However, what I can think of if I were a Data Scientist in an online retail business is the following:
- Cluster 1: They recently made a purchase — typically around a month ago — indicating recent engagement. This cluster of customers, however, tends to make purchases infrequently and spend relatively small amounts overall, averaging 1–2 purchases. Implementing retention campaigns based on these findings can prove to be very effective. Given their recent engagement, it would be beneficial to consider strategies such as follow-up emails or loyalty programs with personalized deals to encourage repeat purchases. This presents an opportunity to suggest additional products that complement their previous purchases, ultimately boosting this group’s average order value and overall spending.
- Cluster 2: The customers in this group recently purchased around two weeks ago and have shown frequent buying habits with significant spending. They are considered top customers, deserving VIP treatment: excellent customer service, special deals, and early access to new items. Utilizing their satisfaction, we could offer referral programs with bonuses and discounts for their family and friends, potentially growing our customer base and increasing overall sales.
- Cluster 3: Customers in this segment have been inactive for over three months, even though their frequency and monetary value are moderate. To re-engage these customers, we should consider launching reactivation campaigns. Sending win-back emails with special discounts or showcasing new arrivals could entice them to return. Additionally, gathering feedback to uncover the reasons behind their lack of recent purchases and addressing any issues or concerns they may have can significantly improve their future experience and reignite their interest.
- Cluster 4: Customers in this group have only purchased in up to seven months, indicating a significant period of dormancy. They display the lowest frequency and monetary value, making them highly susceptible to churning. In these situations, it is essential to implement strategies designed explicitly for dormant customers. Sending important offer-based reactivation emails or personalized incentives usually proves effective in returning these customers to your business. Moreover, conducting exit surveys can help identify the reasons behind their inactivity, enabling you to enhance your offerings and customer service to better meet their needs and reignite their interest.
Congrats! you already know how to conduct RFM Segmentation using K-Means, now it’s your turn to do the same way with your own dataset.
RFM Segmentation: Unleashing Customer Insights was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
RFM Segmentation: Unleashing Customer Insights
Go Here to Read this Fast! RFM Segmentation: Unleashing Customer Insights