

This is probably the solution to your next NLP problem.
In this story we introduce and broadly explore the topic of weak supervision in machine learning. Weak supervision is one learning paradigm in machine learning that started gaining notable attention in recent years. To wrap it up in a nutshell, full supervision requires that we have a training set (x,y) where y is the correct label for x; meanwhile, weak supervision assumes a general setting (x, y’) where y’ does not have to be correct (i.e., it’s potentially incorrect; a weak label). Moreover, in weak supervision we can have multiple weak supervisors so one can have (x, y’1,y’2,…,y’F) for each example where each y’j comes from a different source and is potentially incorrect.
Table of Contents
∘ Problem Statement
∘ General Framework
∘ General Architecture
∘ Snorkel
∘ Weak Supervision Example
Problem Statement
In more practical terms, weak supervision goes towards solving what I like to call the supervised machine learning dilemma. If you are a business or a person with a new idea in machine learning you will need data. It’s often not that hard to collect many samples (x1, x2, …, xm) and sometimes, it can be even done programtically; however, the real dilemma is that you will need to hire human annotators to label this data and pay some $Z per label. The issue is not just that you may not know if the project is worth that much, it’s also that you may not afford hiring annotators to begin with as this process can be quite costy especially in fields such as law and medicine.
You may be thinking but how does weak supervision solve any of this? In simple terms, instead of paying annotators to give you labels, you ask them to give you some generic rules that can be sometimes inaccurate in labeling the data (which takes far less time and money). In some cases, it may be even trivial for your development team to figure out these rules themselves (e.g., if the task doesn’t require expert annotators).
Now let’s think of an example usecase. You are trying to build an NLP system that would mask words corresponding to sensitive information such as phone numbers, names and addresses. Instead of hiring people to label words in a corpus of sentences that you have collected, you write some functions that automatically label all the data based on whether the word is all numbers (likely but not certainly a phone number), whether the word starts with a capital letter while not in the beginning of the sentence (likely but not certainly a name) and etc. then training you system on the weakly labeled data. It may cross your mind that the trained model won’t be any better than such labeling sources but that’s incorrect; weak supervision models are by design meant to generalize beyond the labeling sources by knowing that there is uncertainty and often accounting for it in a way or another.
General Framework
Now let’s formally look at the framework of weak supervision as its employed in natural language processing.
✦ Given
A set of F labeling functions {L1 L2,…,LF} where Lj assigns a weak (i.e., potentially incorrect) label given an input x where any labeling function Lj may be any of:
- Crowdsource annotator (sometimes they are not that accurate)
- Label due to distance supervision (i.e., extracted from another knowledge base)
- Weak model (e.g., inherently weak or trained on another task)
- Heuristic function (e.g., label observation based on the existence of a keyword or pattern or defined by domain expert)
- Gazetteers (e.g., label observation based on its occurrence in a specific list)
- LLM Invocation under a specific prompt P (recent work)
- Any function in general that (preferably) performs better than random guess in guessing the label of x.
It’s generally assumed that Li may abstain from giving a label (e.g., a heuristic function such as “if the word has numbers then label phone number else don’t label”).
Suppose the training set has N examples, then this given is equivalent to an (N,F) weak label matrix in the case of sequence classification. For token classification with a sequence of length of T, it’s a (N,T,F) matrix of weak labels.
✦ Wanted
To train a model M that effectively leverages the weakly labeled data along with any strong data if it exists.
✦ Common NLP Tasks
- Sequence classification (e.g., sentiment analysis) or token classification (e.g., named entity recognition) where labeling functions are usually heuristic functions or gazetteers.
- Low resource translation (x→y) where labeling function(s) is usually a weaker translation model (e.g., a translation model in the reverse direction (y→x) to add more (x,y) translation pairs.
General Architecture
For sequence or token classification tasks, the most common architecture in the literature plausibly takes this form:
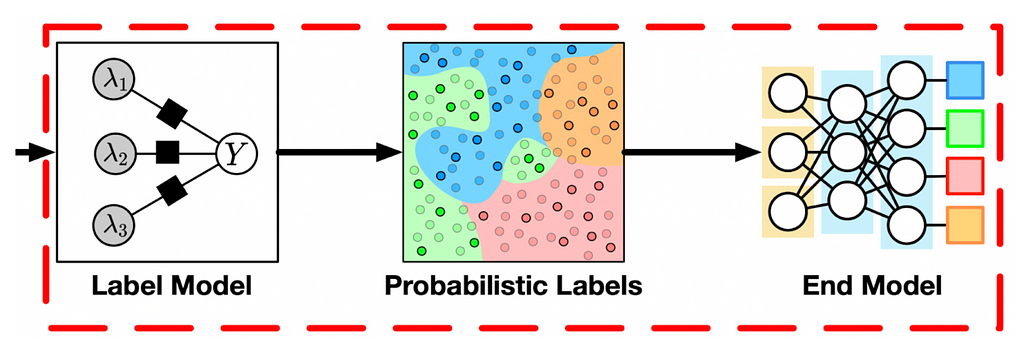
The label model learns to map the outputs from the label functions to probabilistic or deterministic labels which are used to train the end model. In other words, it takes the (N,F) or (N,T,F) label matrix discussed above and returns (N) or (N,T) matrix of labels (which are often probabilistic (i.e., soft) labels).
The end model is used separately after this step and is just an ordinary classifier that operates on soft labels (cross-entropy loss allows that) produced by the label model. Some architectures use deep learning to merge label and end models.
Notice that once we have trained the label model, we use it to generate the labels for the end model and after that we no longer use the label model. In this sense, this is quite different from staking even if the label functions are other machine learning models.
Another architecture, which is the default in the case of translation (and less common for sequence/token classification), is to weight the weak examples (src, trg) pair based on their quality (usually only one labeling function for translation which is a weak model in the reverse direction as discussed earlier). Such weight can then be used in the loss function so the model learns more from better quality examples and less from lower quality ones. Approaches in this case attempt to devise methods to evaluate the quality of a specific example. One approach for example uses the roundtrip BLEU score (i.e., translates sentence to target then back to source) to estimate such weight.
Snorkel
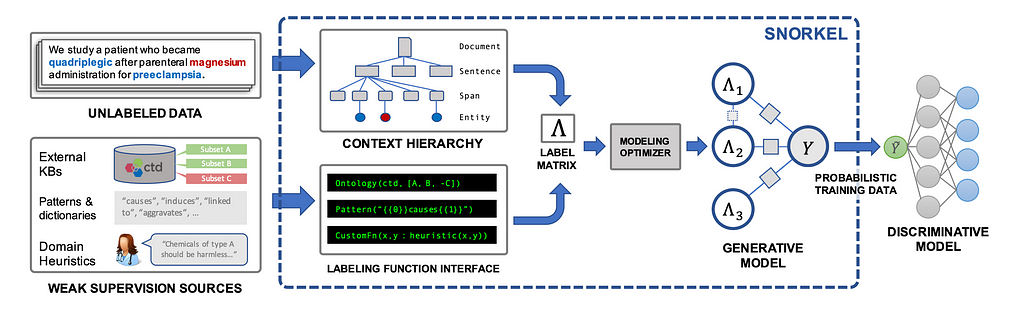
To see an example of how the label model can work, we can look at Snorkel which is arguably the most fundamental work in weaks supervision for sequence classification.
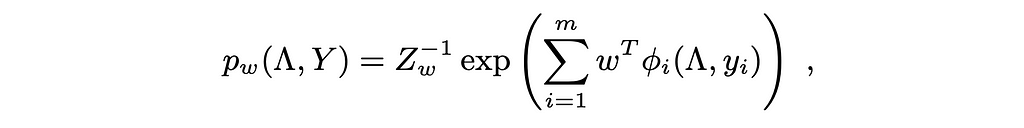
In Snorkel, the authors were interested in finding P(yi|Λ(xi)) where Λ(xi) is the weak label vector of the ith example. Clearly, once this probability is found, we can use it as soft label for the end model (because as we said cross entropy loss can handle soft labels). Also clearly, if we have P(y, Λ(x)) then we can easily use to find P(y|Λ(x)).
We see from the equation above that they used the same hypothesis as logistic regression to model P(y, Λ(x)) (Z is for normalization as in Sigmoid/Softmax). The difference is that instead of w.x we have w.φ(Λ(xi),yi). In particular, φ(Λ(xi),yi) is a vector of dimensionality 2F+|C|. F is the number of labeling functions as mentioned earlier; meanwhile, C is the set of labeling function pairs that are correlated (thus, |C| is the number of correlated pairs). Authors refer to a method in another paper to automate constructing C which we won’t delve into here for brevity.
The vector φ(Λ(xi),yi) contains:
- F binary elements to specify whether each of the labeling functions has abstained for given example
- F binary elements to specify whether each of the labeling functions is equal to the true label y (here y will be left as a variable; it’s an input to the distribution) given this example
- C binary elements to specify whether each correlated pair made the same vote given this example
They then train this label models (i.e., estimate the weights vector of length 2F+|C|) by solving the following objective (minimizing negative log marginal likelihood):
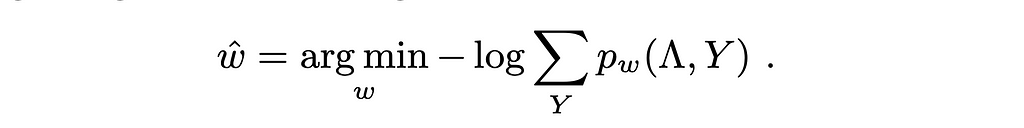
Notice that they don’t need information about y as this objective is solved regardless of any specific value of it as indicated by the sum. If you look closely (undo the negative and the log) you may find that this is equivalent to finding the weights that maximize the probability for any of the true labels.
Once the label model is trained, they use it to produce N soft labels P(y1|Λ(x1)), P(y2|Λ(x2)),…,P(yN|Λ(xN)) and use that to normally train some discriminative model (i.e., a classifier).
Weak Supervision Example
Snorkel has an excellent tutorial for spam classification here. Skweak is another package (and paper) that is fundamental for weak supervision for token classification. This is an example on how to get started with Skweak as shown on their Github:
First define labeling functions:
import spacy, re
from skweak import heuristics, gazetteers, generative, utils
### LF 1: heuristic to detect occurrences of MONEY entities
def money_detector(doc):
for tok in doc[1:]:
if tok.text[0].isdigit() and tok.nbor(-1).is_currency:
yield tok.i-1, tok.i+1, "MONEY"
lf1 = heuristics.FunctionAnnotator("money", money_detector)
### LF 2: detection of years with a regex
lf2= heuristics.TokenConstraintAnnotator("years", lambda tok: re.match("(19|20)d{2}$",
tok.text), "DATE")
### LF 3: a gazetteer with a few names
NAMES = [("Barack", "Obama"), ("Donald", "Trump"), ("Joe", "Biden")]
trie = gazetteers.Trie(NAMES)
lf3 = gazetteers.GazetteerAnnotator("presidents", {"PERSON":trie})
Apply them on the corpus
# We create a corpus (here with a single text)
nlp = spacy.load("en_core_web_sm")
doc = nlp("Donald Trump paid $750 in federal income taxes in 2016")
# apply the labelling functions
doc = lf3(lf2(lf1(doc)))
Create and fit the label model
# create and fit the HMM aggregation model
hmm = generative.HMM("hmm", ["PERSON", "DATE", "MONEY"])
hmm.fit([doc]*10)
# once fitted, we simply apply the model to aggregate all functions
doc = hmm(doc)
# we can then visualise the final result (in Jupyter)
utils.display_entities(doc, "hmm")
Then you can of course train a classifier on top of this on using the estimated soft labels.
In this article, we explored the problem addressed by weak supervision, provided a formal definition, and outlined the general architecture typically employed in this context. We also delved into Snorkel, one of the foundational models in weak supervision, and concluded with a practical example to illustrate how weak supervision can be applied.

Hope you found the article to be useful. Until next time, au revoir.
References
[1] Zhang, J. et al. (2021) Wrench: A comprehensive benchmark for weak supervision, arXiv.org. Available at: https://arxiv.org/abs/2109.11377 .
[2] Ratner, A. et al. (2017) Snorkel: Rapid Training Data Creation with weak supervision, arXiv.org. Available at: https://arxiv.org/abs/1711.10160.
[3] NorskRegnesentral (2021) NorskRegnesentral/skweak: Skweak: A software toolkit for weak supervision applied to NLP tasks, GitHub. Available at: https://github.com/NorskRegnesentral/skweak.
An Intuitive Overview of Weak Supervision was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
An Intuitive Overview of Weak Supervision
Go Here to Read this Fast! An Intuitive Overview of Weak Supervision