How data engineering is practiced today and why we should redefine it
What is the Problem with Data Engineering Today?
If you search for a clear definition of what data engineering actually is, you’ll get so many different proposals that it leaves you with more questions than answers.
But as I want to explain what needs to be redefined, I’ll better use one of the more popular definitions that clearly represents the current state and mess we all face:
Data engineering is the development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning. Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering. A data engineer manages the data engineering lifecycle, beginning with getting data from source systems and ending with serving data for use cases, such as analysis or machine learning.
— Joe Reis and Matt Housley in “Fundamentals of Data Engineering”
That is a fine definition and now, what is the mess?
Let’s look at the first sentence, where I highlight the important part that we should delve into:
…take in raw data and produce high-quality, consistent information that supports downstream use cases…
Accordingly, data engineering takes raw data and transforms it to (produces) information that supports use cases. Only two examples are given, like analysis or machine learning, but I would assume that this includes all other potential use cases.
The data transformation is what drives me and all my fellow data engineers crazy. Data transformation is the monumental task of applying the right logic to raw data to transform it into information that enables all kinds of intelligent use cases.
To apply the right logic is actually the main task of applications. Applications are the systems that implement the logic that drives the business (use cases) — I continue to refer to it as an application and implicitly also mean services that are small enough to fit into the microservices architecture. The applications are usually built by application developers (software engineers if you like). But to meet our current definition of data engineering, the data engineers must now implement business logic. The whole mess starts with this wrong approach.
I have written an article about that topic, where I stress that “Data Engineering is Software Engineering…”. Unfortunately, we already have millions of brittle data pipelines that have been implemented by data engineers. These pipelines sometimes — or regrettably, even oftentimes — do not have the same software quality that you would expect from an application. But the bigger problem is the fact that these pipelines often contain uncoordinated and therefore incorrect and sometimes even hidden business logic.
However, the solution is not that all data engineers should now be turned into application developers. Data engineers still need to be qualified software engineers, but they should by no means turn into application developers. Instead, I advocate a redefinition of data engineering as “all about the movement, manipulation, and management of data”. This definition comes from the book “What Is Data Engineering? by Lewis Gavin (O’Reilly, 2019)”. However, and this is a clear difference to current practices, we should limit manipulation to purely technical ones.
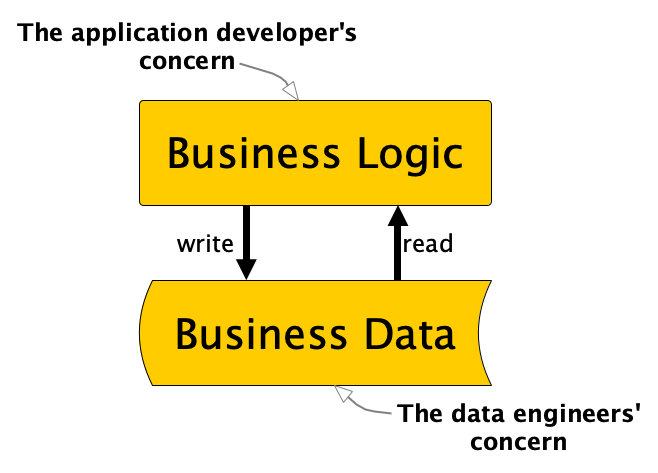
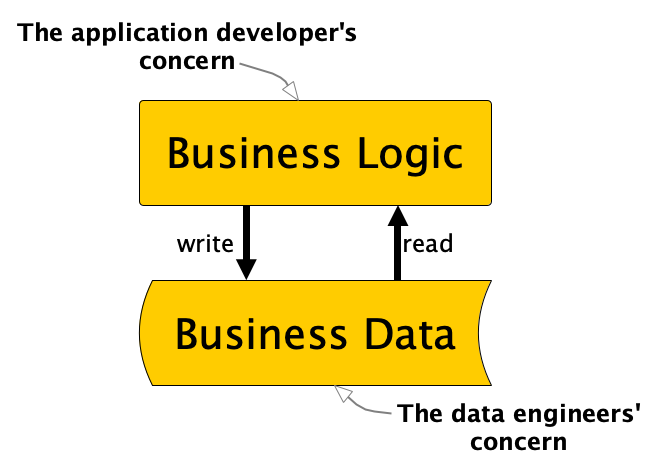
We should no longer allow the development and use of business logic outside of applications.
To be very clear, data engineering should not implement business logic. The trend in modern application development is actually to keep stateless application logic separate from state management. We do not put application logic in the database and we do not put persistent state (or data) in the application. In the functional programming community they joke “We believe in the separation of church and state”. If you now think, “Where is the joke?”, then this might help. But now without any jokes: “We should believe in the separation of business logic and business data”. Accordingly, I believe we should explicitly leave data concerns to the data engineer and logic concerns to the application developer.
What are “technical manipulations” that still are allowed for the data engineer, you might ask. I would define this as any manipulation to data that does not change or add new business information. We can still partition, bucket, reformat, normalize, index, technically aggregate, etc., but as soon as real business logic is necessary, we should address it to the application developers in the business domain responsible for the respective data set.
Why Data Engineering Got Sidetracked
Why have we moved away from this simple and obvious principle?
I think this shift can be attributed to the rapid evolution of databases into multifunctional systems. Initially, databases served as simple, durable storage solutions for business data. They provided very helpful abstractions to offload functionality to persist data from the real business logic in the applications. However, vendors quickly enhanced these systems by embedding software development functionality in their database products to attract application developers. This integration transformed databases from mere data repositories into comprehensive platforms, incorporating sophisticated programming languages and tools for full-fledged software development. Consequently, databases evolved into powerful transformation engines, enabling data specialists to implement business logic outside traditional applications. The demand for this shift was further amplified by the advent of large-scale data warehouses, designed to consolidate scattered data storage — a problem that became more pronounced with the rise of microservices architecture. This technological progression made it practical and efficient to combine business logic with business data within the database.
In the end, not all software engineers succumbed to the temptation of bundling their application logic within the database, preserving hope for a cleaner separation. As data continued to grow in volume and complexity, big data tools like Hadoop and its successors emerged, even replacing traditional databases in some areas. This shift presented an opportunity to move business logic out of the database and back to application developers. However, the notion that data engineering encompasses more than just data movement and management had already taken root. We had developed numerous tools to support business intelligence, advanced analytics, and complex transformation pipelines, allowing the implementation of sophisticated business logic.
These tools have become integral components of the modern data stack (MDS), establishing data engineering as its own discipline. The MDS comprises a comprehensive suit of tools for data mangling and transformation, but these tools remain largely unfamiliar to the typical application developer or software engineer. Despite the potential to “turn the database inside out” and relocate business logic back to the application layer, we failed to fully embrace this opportunity. The unfortunate practice of implementing business logic remains with data engineers to this day.
How Data Engineering Can be Redefined
Let’s more precisely define what “all about the movement, manipulation, and management of data” involves.
Data engineers can and should provide the most mature tools and platforms to be used by application developers to handle data. This is also the main idea with the “self-serving data platform” in the data mesh. However, the responsibility of defining and maintaining the business logic remains within the business domains. These people far better know the business and what business transformation logic should be applied to data.
Okay, so what about these nice ideas like data warehouse systems and more general the overall “data engineering lifecycle” as defined by Joe Reis and Matt Housley?

“Data pipelines” are really just agents between applications, but if business logic is to be implemented in the pipelines, these systems should be considered their own applications in the enterprise. Applications that should be maintained by application developers in the business domains and not by data engineers.
The nice and clear flow of data from source (“Generation” as they named it in their reference) to serving for consumers is actually idealistically reduced. The output from “Reverse ETL” is data that again serves as input for downstream applications. And not only “Reverse ETL” but also “Analytics” and “Machine Learning” create output to be consumed by analytical and operational downstream applications. The journey of data through the organization does not end with the training or application of an ML model or the creation of a business analysis. The results of these applications need to be further processed within the company and therefore be integrated into the overall business process flow (indicated by the blue boxes and arrows). This view blurs the rigid distinction still practiced between the operational and analytical planes, the elimination of which I have described as a core target of data mesh.
So what is the real task of the data engineer? We should evolve the enterprise architecture to enable application developers to take back the business logic into their applications, while allowing seamless exchange and sharing of data between these applications. Data engineers effectively build the “Data Infrastructure” and all the tooling that integrate business logic through a data mesh of interconnected business applications. This is by far more complicated than just providing a collection of different database types, a data warehouse or a data lake, whether on-premises or in the cloud. It comprises the implementation of tools and infrastructure, the definition and application of governance and data sharing principles (including modeling) that ultimately enables the universal data supply in the enterprise. However, the implementation of business logic should definitely be outside the scope of data engineering.
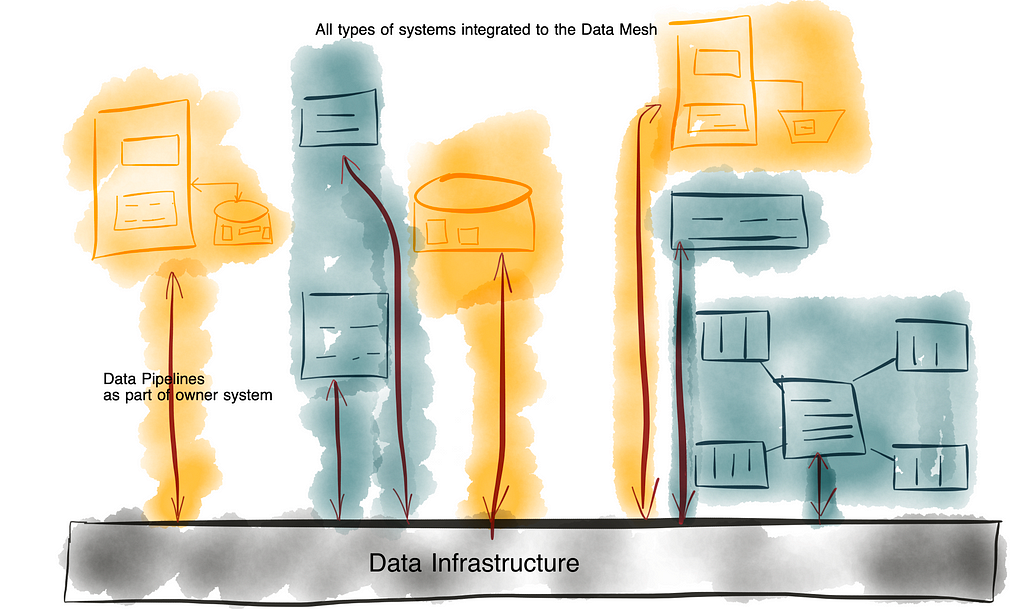
This redefined data engineering practice is in line with the adapted data mesh approach that I proposed in this three-part series:
- Challenges and Solutions in Data Mesh – Part 1
- Challenges and Solutions in Data Mesh — Part 2
- Challenges and Solutions in Data Mesh — Part 3
Data Engineering, Redefined was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Data Engineering, Redefined