
Analogy from classical machine learning: LLM (Large Language Model) = optimizer; code = parameters; LangProp = PyTorch Lightning
You have probably used ChatGPT to write your emails, summarize documents, find out information, or help you debug your code. But can we take a step further and make ChatGPT drive a car?
This was the question we wanted to answer when I started my internship at Wayve in March last year. Wayve is an autonomous driving startup in London, applying end-to-end learning to the challenging problem of urban driving. At the time, the company was just about to launch its LLM research team, which has since successfully developed LINGO-1 and LINGO-2. AutoGPT had just come out, and Voyager had not come out yet. And yet, the disruption caused by LLMs was palpable. The question was, how can we use this new technology to driving, a domain where language isn’t the main modality?
In this blog post, I would like to give an overview of our paper LangProp, which we presented at the LLM Agents workshop at ICLR (the International Conference on Learning Representations) last month (May 2024).
- GitHub – shuishida/LangProp
- LangProp: A code optimization framework using Large Language Models applied to driving
Motivation: Let’s apply ML to code writing, literally.
The challenge of applying LLMs to driving comes in twofold: firstly, LLMs are, as the name says, very large models that require a lot of compute and can be slow to run, which makes them not-so-ideal for safety-critical real-time applications, such as autonomous driving; secondly, while language is good at high-level descriptions and serves as a sophisticated tool for logic, reasoning and planning, it doesn’t have the granularity and detail that is needed to describe observations and give spatial control actions.
We realised, however, that we don’t necessarily have to use LLMs for inferring driving actions. What we could do instead is to make LLMs write the code for driving itself.
If you have ever used ChatGPT to write code then this may sound like a terrible idea. The code that it writes seldom works out of the box, and often contains some errors. But what if we use LLMs to also detect bugs and automatically fix them, thereby iteratively improving the code quality?
We took this idea a step further — instead of just fixing bugs, we designed a training framework that allows us to improve the code that the LLM generates towards an objective function of your choice. You can “train” your code to improve on a training dataset and try to reduce the losses. The code improvements can be quantified by running it on a validation dataset.
Does this start to sound like Machine Learning? Because it essentially is! But are we fine-tuning the LLM? No — in fact, there is no neural network that is being fine-tuned. Instead, we are fine-tuning the code itself!
In LangProp, the “code” is the parameters of the model, and the LLM is the optimizer that guides the parameters to improve in the direction that reduces the loss. Why is this cool? Because by applying this thinking, we can now automate optimization of software themselves in a data-driven way! With deep learning, we witnessed the power of data-driven approaches to solving hard-to-describe problems. But so far, the application domain of machine learning has been constrained to models parametrized by numeric values. Now, they can deal with systems described in code, too.
If you have followed the history of Artificial Intelligence, this is an elegant way to unify the once popular approach of Symbolic AI with the more modern and successful Machine Learning approach. Symbolic AI was about having human experts describe a perfect model of the world in the form of logic and code. This had its limitations, as many complex tasks (e.g. object recognition) were beyond what human experts can feasibly describe with logic alone. Machine Learning, on the other hand, lets the data speak for itself and fits a model that best describes them in an automated way. This approach has been very successful in a wide range of disciplines, including pattern recognition, compression and function approximation. However, logic, reasoning, and long-term planning are fields where naively fitting a neural network on data often fails. This is because it is challenging to learn such complex operations in the modality of neural network parameter space. With LLMs and LangProp, we can finally apply the data-driven learning method to learn symbolic systems and automate their improvement.
Disclaimer
Before we dive in further, I feel that some disclaimers are in order.
- This work on LangProp was conducted as an internship project at Wayve, and does not directly reflect the company’s Research & Development priorities or strategies. The purpose of this blog post is to describe LangProp as a paper, and everything in this blog post is written in the capacity of myself as an individual.
- While we demonstrated LangProp primarily for the case of autonomous driving, we also would like to stress its limitations, such as (a) it requires perfect observation of the environment, (b) we only made it work in a simulated environment and it is far from real-world deployment, (c) the generated driving code is not perfect nor sophisticated, and has many issues to be suitable for real-world deployment. We see LangProp as a research prototype that showcases the potential of LLMs applied to data-driven software optimization, not as a product for deployment.
If you need further information on the limitations of LangProp, please check out the limitation section in the appendix of our paper.
With that said, let’s take a look at how LangProp works!
How does LangProp work?
…we bring back Symbolic AI and Evolutionary Algorithms
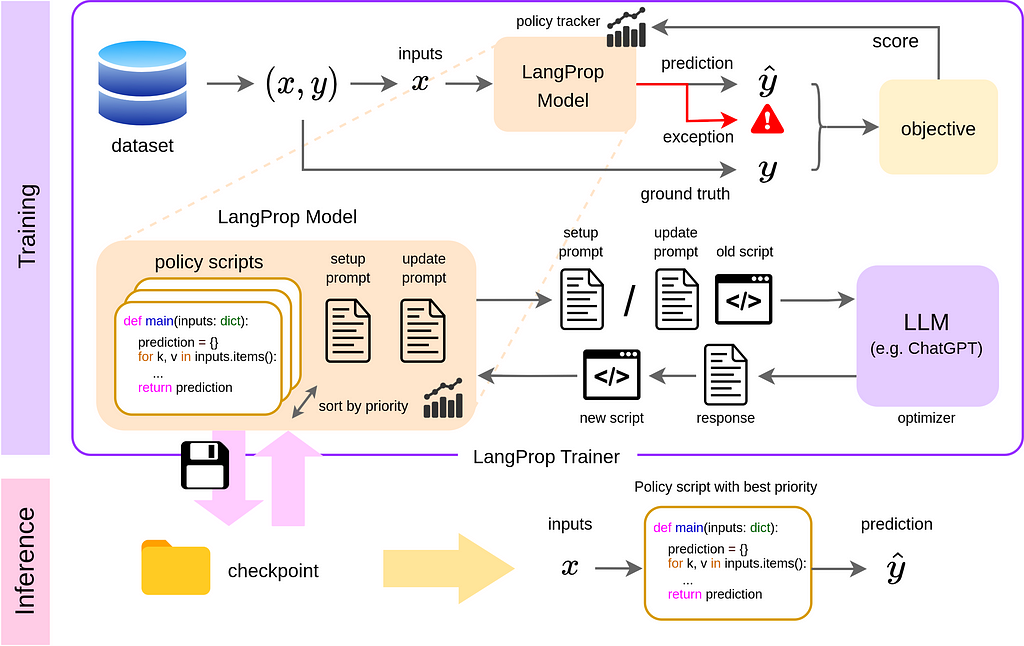
LangProp is designed like PyTorch Lightning — a LangProp module keeps track of the parameters (collection of scripts) that are trained and used for inference. In the training mode, a policy tracker keeps a record of the inputs, outputs, and any exceptions during the forward pass. The performance of the code is evaluated by an objective function. Based on the scores, the policy tracker re-ranks the scripts that currently exist, and passes the top k scripts to the LLM for refinement. At inference time, making a prediction is as simple as calling the code with the best score.
The LangProp trainer takes a LangProp module to be trained, a training dataset, and a validation dataset. The dataset can be any iterable object, including a PyTorch Dataset object, which makes applying LangProp to existing tasks easier. Once the training is finished, we can save a checkpoint, which is the collection of refined code along with some statistics for ranking the code.
The mechanism we use to choose the best code and improve them is similar to evolutionary algorithms, in which samples are initially chosen randomly, but then the ones that are high-performing are kept and perturbed to spawn a new generation of fitter samples.
Applying LangProp to driving
Now let’s try using LangProp to drive in CARLA!
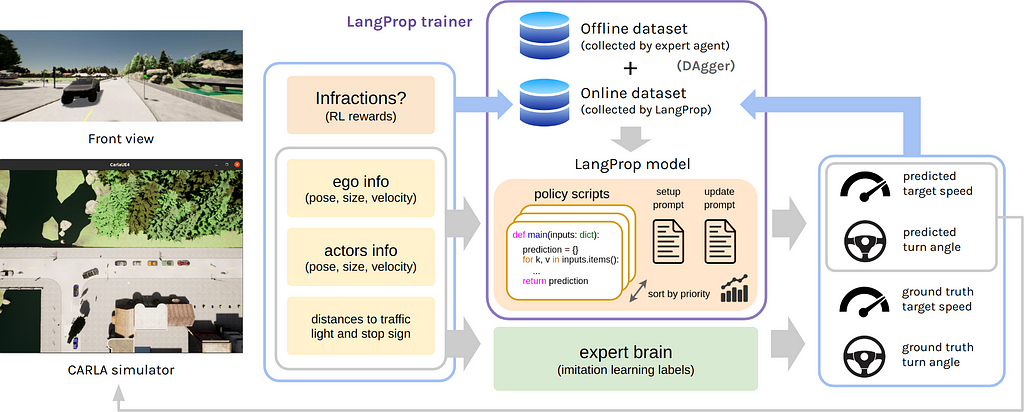
CARLA is an open-sourced driving simulator used for autonomous driving research. There is a leaderboard challenge to benchmark your self-driving car agent. We tested LangProp on the standard routes and towns in this challenge.
The good thing about formulating LangProp as a Machine Learning framework is that, now we can apply not just classic supervised learning but also imitation learning and reinforcement learning techniques.
Specifically, we start our training on an offline dataset (driving demonstrations from an expert that contains state and action pairs), and then perform online rollouts. During online rollout, we employ DAgger [1], which is a dataset aggregation technique where samples collected by online rollouts are labelled with expert labels and aggregated with the current dataset.
The input to the model (the code) is a Python dictionary of the state of the environment, including the poses and velocities of the vehicle and surrounding actors, and the distances to the traffic light / stop sign. The output is the driving action, which is the speed and steering angle at which the vehicle should drive.
Whenever there is an infraction, e.g. ignoring a traffic light or stop sign, collision with another vehicle, pedestrian or cyclist, or being stationary for too long, there is a penality to the performance scores. The training objective is to maximize the combined score of imitation learning scores (how well can the agent match the ground truth action labels) and the reinforcement learning scores (reducing the infraction penalty).
LangProp driving agent in action
Now watch the LangProp agent drive!
We saw during training that, the initial driving policy that ChatGPT generates is very faulty. In particular, it often learns a naive policy that copies the previous velocity. This is a well-known phenomenon called causal confusion [2] in the field of imitation learning. If we just train with behavioral cloning on the offline dataset, such naive but simple policies obtain a high score compared to other more complex policies. This is why we need to use techniques such as DAgger and reinforcement learning to make sure that the policy performs in online rollout.
After an iteration or two, the model stops copying the previous velocity and starts moving forward, but is either overly cautious (i.e. stops whenever there is an actor nearby, even if they are not in collision course), or reckless (driving forward until it collides into an actor). After a couple more iterations, the model learns to keep a distance from the vehicle in front and even calculates this distance dynamically based on the relative velocities of the vehicles. It also predicts whether other actors (e.g. J-walking pedestrians) are on collision course with the vehicle by looking at the velocity and position vectors.
In the experiments in our paper, we show that the LangProp driving agent outperforms many of the previously implemented driving agents. We compare against both a PPO expert agent (Carla-Roach [3], TCP [4]) and researcher-implemented expert agents (TransFuser [5], InterFuser [6], TF++ [7]), and LangProp outperformed all expert agents except for TF++. All the expert agents were published after the GPT 3.5 training cutoff of September 2021, so this result is both surprising and exciting!
Closing remark
Thank you for joining me on the ride! While in this work we primarily explored the application of LangProp to autonomous driving in CARLA, we also showed that LangProp can be easily applied to more general problems, such as the typical RL environment of CartPole-v1. LangProp works best in environments or problems where feedback on the performance can be obtained in the form of text or code, giving the model a richer semantic signal that is more than just numerical scores.
There are endless possible applications of LangProp-like training to iteratively improve software based on data, and we are excited to see what will happen in this space!
If you liked our work, please consider building on top of it and citing our paper:
@inproceedings{
ishida2024langprop,
title={LangProp: A code optimization framework using Large Language Models applied to driving},
author={Shu Ishida and Gianluca Corrado and George Fedoseev and Hudson Yeo and Lloyd Russell and Jamie Shotton and Joao F. Henriques and Anthony Hu},
booktitle={ICLR 2024 Workshop on Large Language Model (LLM) Agents},
year={2024},
url={https://openreview.net/forum?id=JQJJ9PkdYC}
}
References
[1] Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. “A reduction of imitation learning and structured prediction to no-regret online learning.” In Proceedings of the fourteenth international conference on artificial intelligence and statistics, JMLR Workshop and Conference Proceedings, 2011.
[2] Pim De Haan, Dinesh Jayaraman, and Sergey Levine. “Causal confusion in imitation learning”. Advances in Neural Information Processing Systems, 2019.
[3] Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, and Luc Van Gool. “End-to-end urban driving by imitating a reinforcement learning coach.” In Proceedings of the IEEE/CVF international Conference on Computer Vision, pp. 15222–15232, 2021.
[4] Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. “Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline.” Advances in Neural Information Processing Systems, 35:6119–6132, 2022.
[5] Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. “Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
[6] Hao Shao, Letian Wang, Ruobing Chen, Hongsheng Li, and Yu Liu. “Safety-enhanced autonomous driving using interpretable sensor fusion transformer.” In Conference on Robot Learning, pp. 726–737. PMLR, 2023.
[7] Jaeger, Bernhard, Kashyap Chitta, and Andreas Geiger. “Hidden biases of end-to-end driving models.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
Making LLMs Write Better and Better Code for Self-Driving Using LangProp was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Making LLMs Write Better and Better Code for Self-Driving Using LangProp
Go Here to Read this Fast! Making LLMs Write Better and Better Code for Self-Driving Using LangProp