

New words. Old concepts. In the end, it’s about data fusion.
Entity resolution is a process. A knowledge graph is a technical artifact. And the combination of the two yields one of the most powerful data fusion tools we have in the domain of knowledge representation and reasoning. Recently, ERKGs have made their way into the data architecture narrative, especially for analytic organizations that want all data in a given domain connected in one place for investigation. This article is going to unpack the Entity Resolved Knowledge Graph, the ER, the KG, and some of the details about their implementation.
ER. Entity-resolution (aka identity resolution, data matching, or record linkage) is the computational process by which entities are de-duplicated and/or linked in a data set. This can be as simple as resolving two records in a database, one listed as Tom Riddle and one listed as T.M. Riddle. Or it can be as complex as a person using aliases (Lord Voldemort), different phone numbers, and multiple IP addresses to commit banking fraud.
KG. A knowledge graph is a form of knowledge representation that presents data visually as entities and the relationships between them. Entities could be people, companies, concepts, physical assets, geolocations, etc. Relationships could be information exchange, communication, travel, banking transactions, computational transactions, etc. Entities and relationships are stored in a graph database, pre-joined, and represented visually as nodes and edges. It looks something like this…
Thus…
ERKG. A knowledge graph that contains multiple datasets within which entities are connected and deduplicated. In other words, there are no duplicate entities (the nodes for Tom Riddle and T.M. Riddle have been resolved into a single node). Also, latent connections have been discovered between potentially related nodes within some acceptable probability threshold (e.g., Tom Riddle, Lord Voldemort, and Marvolo Riddle. At this point you are probably asking, “why would you ever create a knowledge graph from multiple data sources that isn’t entity-resolved?” The simple answer is, “you wouldn’t.” That said, the methods around how to resolve entities and the technologies available for graph representation make the creation of an ERKG a daunting task.
This is the first ERKG we ever made.
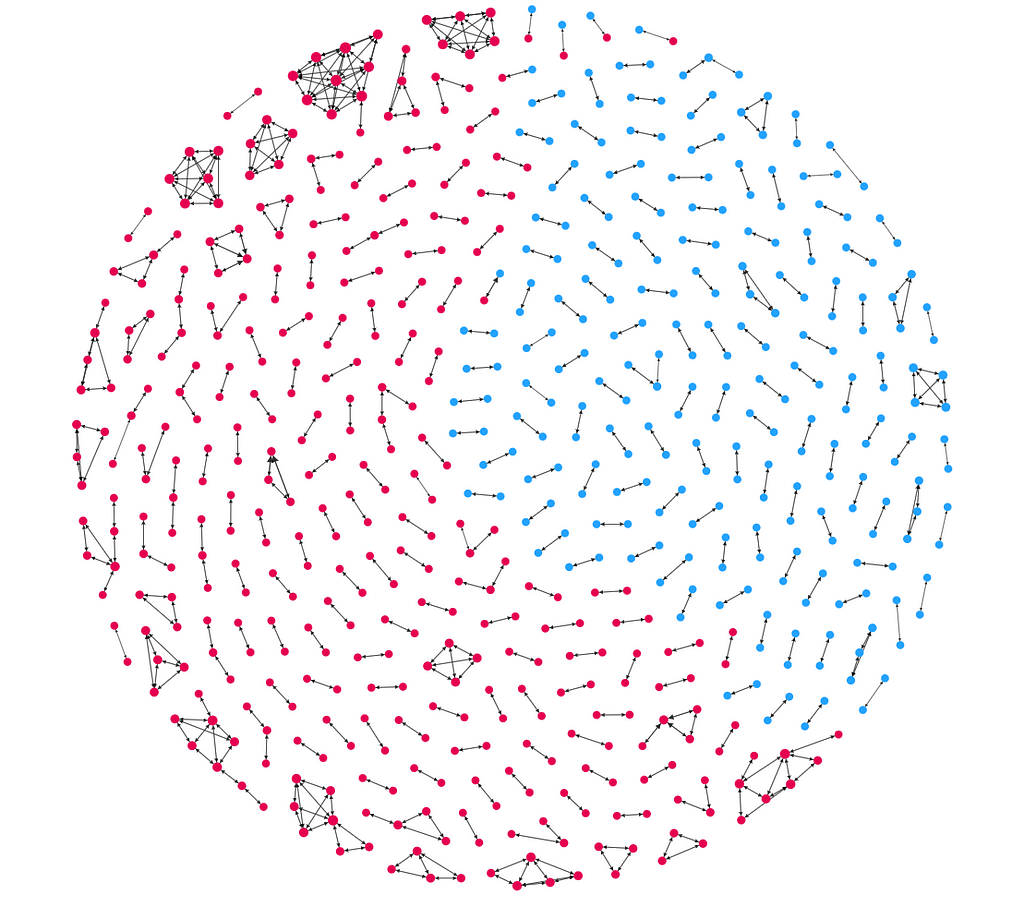
Back in 2016, we brought two datasets into a graph database: 1) individuals on the Office of Foreign Assets Control’s (OFAC) international sanctions list (blue), and 2) customers of a firm that shall remain nameless (pink). Obviously, the firm’s intent was to discover if any of its customers were internationally sanctioned individuals without doing a manual search of OFAC’s database. While the ER process this graph represents is probably overkill for the task, it is illustrative.
The majority of resolved entities in the graph are between two and three individuals within the same dataset (blue to blue or pink to pink). These likely represent duplicate records (that Tom Riddle vs. T.M. Riddle problem we talked about earlier). In some cases, the deduplication is extreme, like in the pink clusters near the top of the image. Here we see that a single person is represented by 5–10 separate records in the customer dataset. So, at minimum, we see that the firm is in need of a deduplication process within its own customer data holdings.
Where it gets interesting is in the blue-to-pink relationships we see identified at the top of the image. This is what the firm was looking for: entity resolutions across datasets. Several of its customers are likely internationally sanctioned individuals.
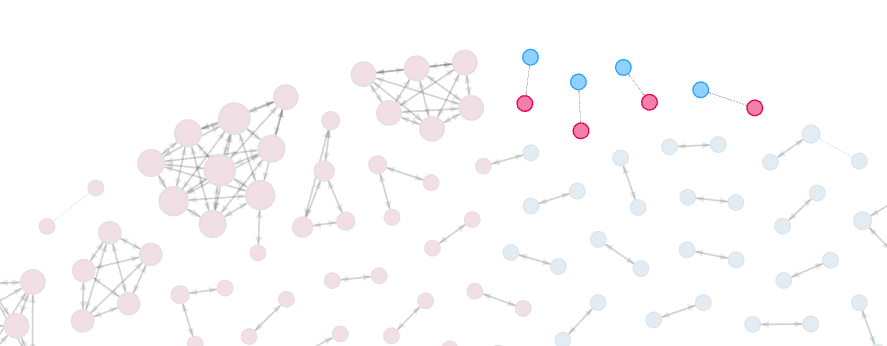
This example is pretty simple which may lead one to incorrectly conclude that building an ERKG is a simple undertaking. It is anything but simple. Especially if it needs to scale across several terabytes of data and multiple analyst users.
Lightweight natural language processing (NLP) algorithms (like fuzzy matching techniques) are simple enough to implement. These can easily handle the Tom Riddle vs. T.M. Riddle problem. But when one seeks to combine more than two datasets, possibly with multiple languages and international characters, the simple NLP process gets pretty spicy.
More advanced ER solutions are also required for more advanced analytical problem sets like anti-money laundering or banking fraud. Fuzzy matching is not enough to identify a perpetrator who is intentionally concealing his or her identity using multiple aliases, and attempting to evade sanctions or other regulations. For this, the ER process should include machine learning-based approaches and more sophisticated methods that take into account additional metadata beyond a name. It’s not all NLP.
There is also a great deal of debate around graph-based ER vs. ER at the dataset level. For the highest fidelity graph-based analysis, both are required. Resolving entities within and across datasets as those datasets are brought into a graph database 1) minimizes large-scale operations on the graph which are computationally expensive, and 2) ensures that the graph contains only resolved entities (no duplicates) at inception, which also provides huge cost savings for the overall graph architecture.
Once an entity-resolved knowledge graph exists, data science teams can then further explore additional ER through graph-based ER techniques. These techniques have the added benefit of leveraging graph topology (i.e., the inherent structure of the graph itself) as a feature on which to predict latent connections across the combined datasets.
The ERKG can be a powerful and visually intuitive analytical tool. It provides:
- Fusion of multiple datasets into a master graph database
- A domain-specific knowledge graph represented visually for analysts to explore
- The ability to specify a living graph schema that represents how data are connected and represented to analysts
- The visual representation of data deduplication and explicit connections within and across datasets
- Latent connections (predicted links) within and across datasets with the ability to control the probability threshold of the prediction
The ERKG then becomes the analytic canvas on which to paint a vibrantly interconnected exploration of a given domain represented through multiple datasets. It’s a data fusion solution, and a highly human-intuitive one at that.
Entity-Resolved Knowledge Graphs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Entity-Resolved Knowledge Graphs