

Extending Spark for improved performance in handling multiple search terms
During the process of deploying our intrusion detection system into production at CCCS, we observed that many of the SigmaHQ rules use very sizable lists of search patterns. These lists are used to test if a CommandLinecontains a given string or if the CommandLinestarts-with or ends-with a given substring.
We were particularly interested in investigating the rules involving “contains” conditions, as we suspected that these conditions might be time-consuming for Spark to evaluate. Here is an example of a typical Sigma rule:
detection:
selection_image:
- Image|contains:
- 'CVE-202'
- 'CVE202'
- Image|endswith:
- 'poc.exe'
- 'artifact.exe'
- 'artifact64.exe'
- 'artifact_protected.exe'
- 'artifact32.exe'
- 'artifact32big.exe'
- 'obfuscated.exe'
- 'obfusc.exe'
- 'meterpreter'
selection_commandline:
CommandLine|contains:
- 'inject.ps1'
- 'Invoke-CVE'
- 'pupy.ps1'
- 'payload.ps1'
- 'beacon.ps1'
- 'PowerView.ps1'
- 'bypass.ps1'
- 'obfuscated.ps1'
The complete Suspicious Program Names rule can be found here
https://github.com/SigmaHQ/sigma/blob/master/rules/windows/process_creation/proc_creation_win_susp_progname.yml
The rule illustrates the use of CommandLine|contains and of Image|endswith. Some Sigma rules have hundreds of search terms under a <field>|containscondition.
Applying Sigma Rules with Spark SQL
At CCCS, we translate Sigma rules into executable Spark SQL statements. To do so we have extended the SQL Sigma compiler with a custom backend. It translates the above rule into a statement like this:
select
map(
'Suspicious Program Names',
(
(
(
Imagepath LIKE '%\cve-202%'
OR Imagepath LIKE '%\cve202%'
)
OR (
Imagepath LIKE '%\poc.exe'
OR Imagepath LIKE '%\artifact.exe'
...
OR Imagepath LIKE '%obfusc.exe'
OR Imagepath LIKE '%\meterpreter'
)
)
OR (
CommandLine LIKE '%inject.ps1%'
OR CommandLine LIKE '%invoke-cve%'
OR CommandLine LIKE '%pupy.ps1%'
...
OR CommandLine LIKE '%encode.ps1%'
OR CommandLine LIKE '%powercat.ps1%'
)
)
) as sigma_rules_map
We run the above statement in a Spark Structured streaming job. In a single pass over the events Spark evaluates multiple (hundreds) of Sigma rules. The sigma_rules_map column holds the evaluation results of all these rules. Using this map we can determine which rule is a hit and which one is not.
As we can see, the rules often involve comparing event’s attribute, such as CommandLine, to multiple string patterns.
Some of these tests are exact matches, such as CommandLine = ‘something’. Others use startswithand are rendered as Imagepath LIKE ‘%\poc.exe’.
Equals, startswith, and endswith are executed very rapidly since these conditions are all anchored at a particular position in the event’s attribute.
However, tests like contains are rendered as CommandLine LIKE ‘%hound.ps1%’ which requires Spark to scan the entire attribute to find a possible starting position for the letter ‘h’ and then check if it is followed by the letter ‘o’, ‘u’ etc.
Internally, Spark uses a UTF8String which grabs the first character, scans the buffer, and if it finds a match, goes on to compare the remaining bytes using the matchAt function. Here is the implementation of the UTF8String.contains function.
public boolean contains(final UTF8String substring) {
if (substring.numBytes == 0) {
return true;
}
byte first = substring.getByte(0);
for (int i = 0; i <= numBytes - substring.numBytes; i++) {
if (getByte(i) == first && matchAt(substring, i)) {
return true;
}
}
return false;
}
The equals, startswith, and endswith conditions also use the matchAt function but contrary to contains these conditions know where to start the comparison and thus execute very rapidly.
To validate our assumption that contains condition is costly to execute we conducted a quick and simple experiment. We removed all the contains conditions for the Sigma rules to see how it would impact the overall execution time. The difference was significant and encouraged us to pursue the idea of implementing a custom Spark Catalyst function to handle contains operations involving large number of search terms.
The Aho-Corasick Algorithm
A bit of research led us to the Aho-Corasick algorithm which seemed to be a good fit for this use case. The Aho-Corasick algorithm builds a prefix tree (a trie) and can evaluate many contains expressions in a single pass over the text to be tested.
Here is how to use the Aho-Corasick Java implementation from Robert Bor available on github here https://github.com/robert-bor/aho-corasick
// create the trie
val triBuilder = Trie.builder()
triBuilder.addKeyword("test1")
triBuilder.addKeyword("test2")
trie = triBuilder.build()
// apply the trie to some text
aTextColumn = "some text to scan for either test1 or test2"
found = trie.containsMatch(aTextColumn)
Designing a aho_corasick_in Spark Function
Our function will need two things: the column to be tested and the search patterns to look for. We will implement a function with the following signature:
boolean aho_corasick_in(string text, array<string> searches)
We modified our CCCS Sigma compiler to produce SQL statements which use the aho_corasick_infunction rather than producing multiple ORed LIKE predicates. In the output below, you will notice the use of the aho_corasick_in function. We pass in the field to be tested and an array of strings to search for. Here is the output of our custom compiler handling multiple contains conditions:
select
map(
'Suspicious Program Names',
(
(
(
Imagepath LIKE '%\cve-202%'
OR Imagepath LIKE '%\cve202%'
)
OR (
Imagepath LIKE '%\poc.exe'
OR Imagepath LIKE '%\artifact.exe'
...
OR Imagepath LIKE '%\meterpreter'
)
)
OR (
aho_corasick_in(
CommandLine,
ARRAY(
'inject.ps1',
'invoke-cve',
...
'hound.ps1',
'encode.ps1',
'powercat.ps1'
)
)
)
)
) as sigma_rules_map
Notice how the aho_corasick_in function receives two arguments: the first is a column, and the second is a string array. Let’s now actually implement the aho_corasick_infunction.
Implementing the Catalyst Function
We did not find much documentation on how to implement Catalyst functions, so instead, we used the source code of existing functions as a reference. We took the regexp(str, regexp) function as an example because it pre-compiles it’s regexp pattern and then uses it when processing rows. This is similar to pre-building a Aho-Corasick trie and then applying it to every row.
Our custom catalyst expression takes two arguments. It’s thus a BinaryExpression which has two fields which Spark named left and right. Our AhoCorasickIn constructor assigns the text column argument to left field and the searches string array to right field.
The other thing we do during the initialization of AhoCorasickIn is to evaluate the cacheTrie field. The evaluation tests if the searches argument is a foldable expression, i.e., a constant expression. If so, it evaluates it and expects it to be a string array, which it uses to call createTrie(searches).
The createTrie function iterates over the searches and adds them to the trieBuilder and finally builds an Aho-Corasick Trie.
case class AhoCorasickIn(text: Expression, searches: Expression)
extends BinaryExpression
with CodegenFallback
with ImplicitCastInputTypes
with NullIntolerant
with Predicate {
override def prettyName: String = "aho_corasick_in"
// Assign text to left field
override def left: Expression = text
// Assign searches to right field
override def right: Expression = searches
override def inputTypes: Seq[DataType] = Seq(StringType, ArrayType(StringType))
// Cache foldable searches expression when AhoCorasickIn is constructed
private lazy val cacheTrie: Trie = right match {
case p: Expression if p.foldable => {
val searches = p.eval().asInstanceOf[ArrayData]
createTrie(searches)
}
case _ => null
}
protected def createTrie(searches: ArrayData): Trie = {
val triBuilder = Trie.builder()
searches.foreach(StringType, (i, s) => triBuilder.addKeyword(s.toString()))
triBuilder.build()
}
protected def getTrie(searches: ArrayData) = if (cacheTrie == null) createTrie(searches) else cacheTrie
override protected def nullSafeEval(text: Any, searches: Any): Any = {
val trie = getTrie(searches.asInstanceOf[ArrayData])
trie.containsMatch(text.asInstanceOf[UTF8String].toString())
}
override protected def withNewChildrenInternal(
newLeft: Expression, newRight: Expression): AhoCorasickIn =
copy(text = newLeft, searches = newRight)
}
The nullSafeEval method is the heart of the AhoCorasickIn. Spark calls the eval function for every row in the dataset. In nullSafeEval, we retrieve the cacheTrie and use it to test the text string argument.
Evaluating the Performance
To compare the performance of the aho_corasick_in function we wrote a small benchmarking script. We compared the performance of doing multiple LIKE operations versus a single aho_corasick_in call.
select
*
from (
select
text like '%' || uuid() || '%' OR
text like '%' || uuid() || '%' OR
text like '%' || uuid() || '%' OR
...
as result
from (
select
uuid()||uuid()||uuid()... as text
from
range(0, 1000000, 1, 32)
)
)
where
result = TRUE
Same experiment using aho_corasick_in:
select
*
from (
select
aho_corasick_in(text, array(uuid(), uuid(),...) as result
from (
select
uuid()||uuid()||uuid()... as text
from
range(0, 1000000, 1, 32)
)
)
where
result = TRUE
We ran these two experiments (like vs aho_corasick_in) with a text column of 200 characters and varied the number of search terms. Here is a logarithmic plot comparing both queries.
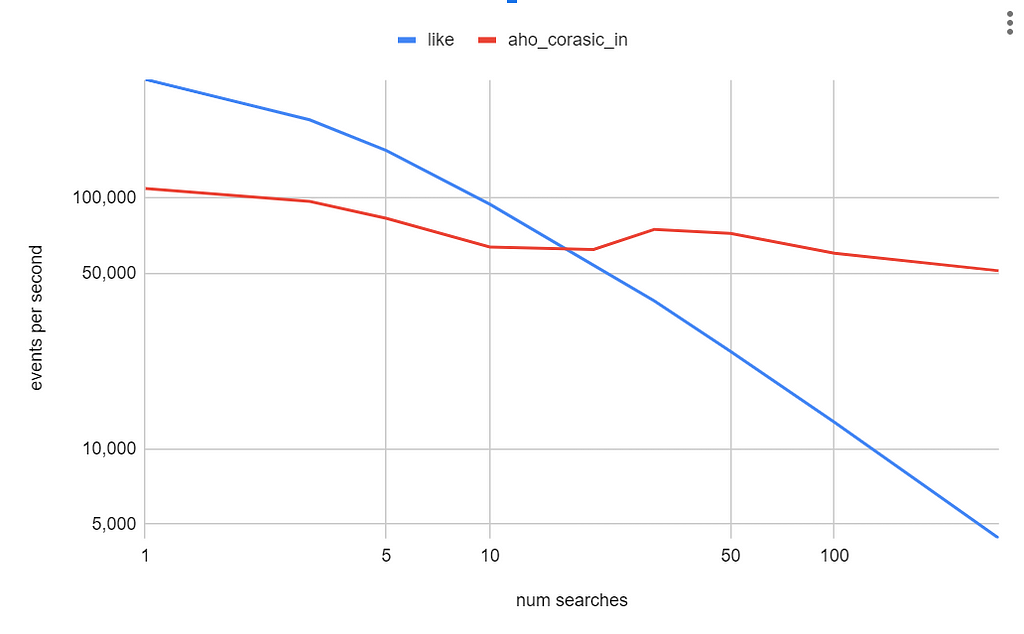
This plot shows how performance degrades as we add more search terms to the “LIKE” query, while the query using aho_corasick_in function remains relatively constant as the number of search terms increases. At 100 search terms, the aho_corasick_in function runs five times faster than multiple LIKE statements.
We find that using Aho-Corasick is only beneficial past 20 searches. This can be explained by the initial cost of building the trie. However, as the number of search terms increases, that up-front cost pays off. This contrasts with the LIKE expressions, where the more LIKE expressions we add, the more costly the query becomes.
Next, we set the number of search terms to 20 and varied the length of the text string. We observed that both the LIKE and aho_corasick_in function take about the same time across various string lengths. In both experiments the execution time is dependent on the length of the text string.
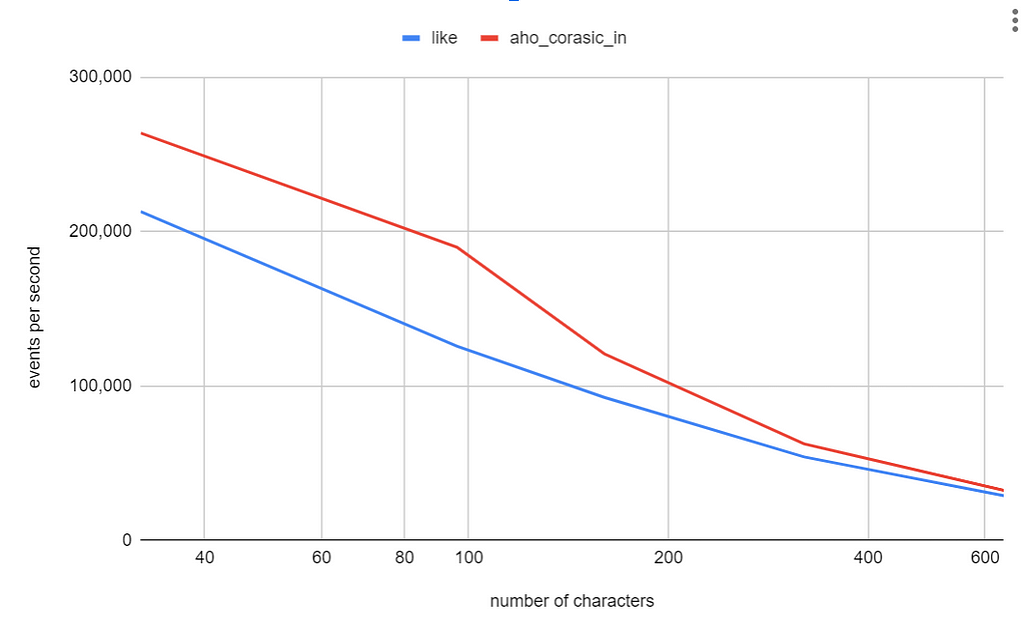
It’s important to note that the cost incurred to build the trie will depend on the number of Spark tasks in the query execution plan. Spark instantiates expressions (i.e.: instantiates new AhoCorasickIn objects) for every task in the execution plan. In other words, if your query uses 200 tasks, the AhoCorasickIn constructor will be called 200 times.
To summarize, the strategy to use will depend on the number of terms. We built this optimization into our Sigma compiler. Under a given threshold (say 20 terms) it renders LIKE statements and above this threshold it renders a query that uses the aho_corasick_in function.
Of course this threshold will be dependent on your actual data and on the number of tasks in your Spark execution plan.
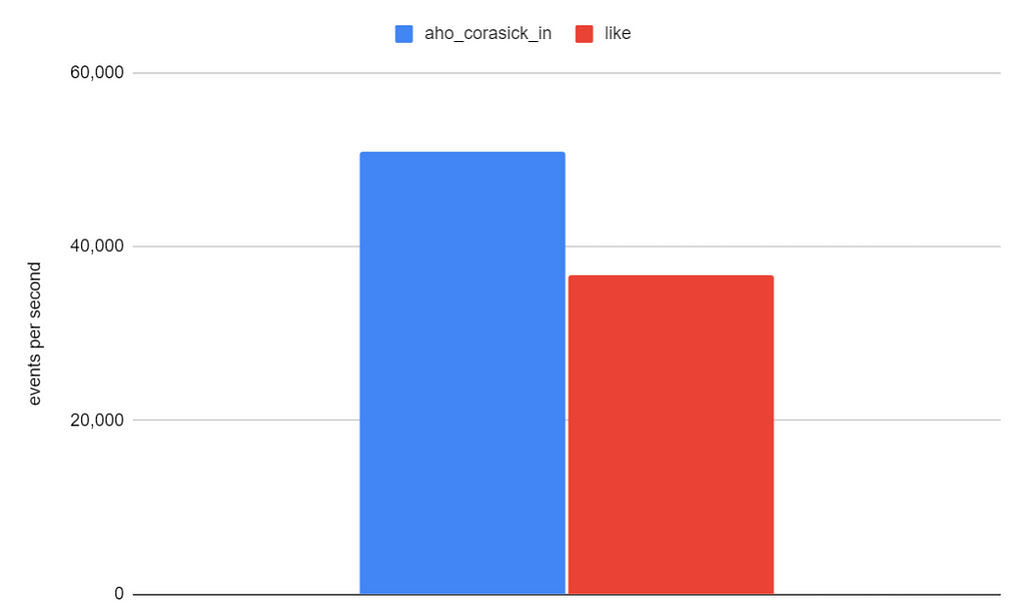
Our initial results, conducted on production data and real SigmaHQ rules, show that applying the aho_corasick_in function increases our processing rate (events per second) by a factor of 1.4x.
Conclusion
In this article, we demonstrated how to implement a native Spark function. This Catalyst expression leverages the Aho-Corasick algorithm, which can test many search terms simultaneously. However, as with any approach, there are trade-offs. Using Aho-Corasick requires building a trie (prefix tree), which can degrade performance when only a few search terms are used. Our compiler uses a threshold (number of search terms) to choose the optimal strategy, ensuring the most efficient query execution.
Optimizing Sigma Rules in Spark with the Aho-Corasick Algorithm was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Optimizing Sigma Rules in Spark with the Aho-Corasick Algorithm
Go Here to Read this Fast! Optimizing Sigma Rules in Spark with the Aho-Corasick Algorithm