

Automating Routine Tasks in Data Source Management with CrewAI
Initially, when ChatGPT just appeared, we used simple prompts to get answers to our questions. Then, we encountered issues with hallucinations and began using RAG (Retrieval Augmented Generation) to provide more context to LLMs. After that, we started experimenting with AI agents, where LLMs act as a reasoning engine and can decide what to do next, which tools to use, and when to return the final answer.
The next evolutionary step is to create teams of such agents that can collaborate with each other. This approach is logical as it mirrors human interactions. We work in teams where each member has a specific role:
- The product manager proposes the next project to work on.
- The designer creates its look and feel.
- The software engineer develops the solution.
- The analyst examines the data to ensure it performs as expected and identifies ways to improve the product for customers.
Similarly, we can create a team of AI agents, each focusing on one domain. They can collaborate and reach a final conclusion together. Just as specialization enhances performance in real life, it could also benefit the performance of AI agents.
Another advantage of this approach is increased flexibility. Each agent can operate with its own prompt, set of tools and even LLM. For instance, we can use different models for different parts of our system. You can use GPT-4 for the agent that needs more reasoning and GPT-3.5 for the one that does only simple extraction. We can even fine-tune the model for small specific tasks and use it in our crew of agents.
The potential drawbacks of this approach are time and cost. Multiple interactions and knowledge sharing between agents require more calls to LLM and consume additional tokens. This could result in longer wait times and increased expenses.
There are several frameworks available for multi-agent systems today.
Here are some of the most popular ones:
- AutoGen: Developed by Microsoft, AutoGen uses a conversational approach and was one of the earliest frameworks for multi-agent systems,
- LangGraph: While not strictly a multi-agent framework, LangGraph allows for defining complex interactions between actors using a graph structure. So, it can also be adapted to create multi-agent systems.
- CrewAI: Positioned as a high-level framework, CrewAI facilitates the creation of “crews” consisting of role-playing agents capable of collaborating in various ways.
I’ve decided to start experimenting with multi-agent frameworks from CrewAI since it’s quite widely popular and user friendly. So, it looks like a good option to begin with.
In this article, I will walk you through how to use CrewAI. As analysts, we’re the domain experts responsible for documenting various data sources and addressing related questions. We’ll explore how to automate these tasks using multi-agent frameworks.
Setting up the environment
Let’s start with setting up the environment. First, we need to install the CrewAI main package and an extension to work with tools.
pip install crewai
pip install 'crewai[tools]'
CrewAI was developed to work primarily with OpenAI API, but I would also like to try it with a local model. According to the ChatBot Arena Leaderboard, the best model you can run on your laptop is Llama 3 (8b parameters). It will be the most feasible option for our use case.
We can access Llama models using Ollama. Installation is pretty straightforward. You need to download Ollama from the website and then go through the installation process. That’s it.
Now, you can test the model in CLI by running the following command.
ollama run llama3
For example, you can ask something like this.
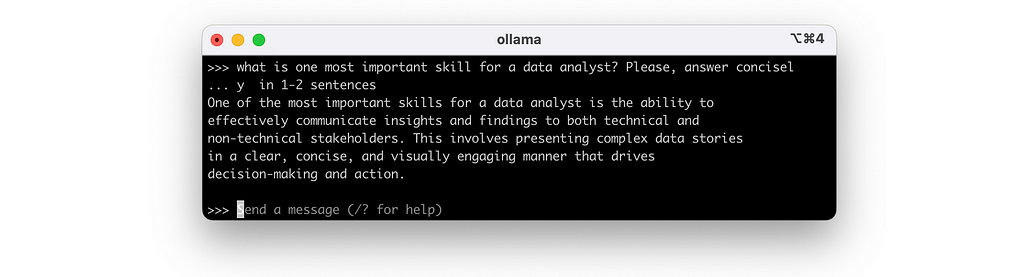
Let’s create a custom Ollama model to use later in CrewAI.
We will start with a ModelFile (documentation). I only specified the base model (llama3), temperature and stop sequence. However, you might add more features. For example, you can determine the system message using SYSTEM keyword.
FROM llama3
# set parameters
PARAMETER temperature 0.5
PARAMETER stop Result
I’ve saved it into a Llama3ModelFile file.
Let’s create a bash script to load the base model for Ollama and create the custom model we defined in ModelFile.
#!/bin/zsh
# define variables
model_name="llama3"
custom_model_name="crewai-llama3"
# load the base model
ollama pull $model_name
# create the model file
ollama create $custom_model_name -f ./Llama3ModelFile
Let’s execute this file.
chmod +x ./llama3_setup.sh
./llama3_setup.sh
You can find both files on GitHub: Llama3ModelFile and llama3_setup.sh
We need to initialise the following environmental variables to use the local Llama model with CrewAI.
os.environ["OPENAI_API_BASE"]='http://localhost:11434/v1'
os.environ["OPENAI_MODEL_NAME"]='crewai-llama3'
# custom_model_name from the bash script
os.environ["OPENAI_API_KEY"] = "NA"
We’ve finished the setup and are ready to continue our journey.
Use cases: working with documentation
As analysts, we often play the role of subject matter experts for data and some data-related tools. In my previous team, we used to have a channel with almost 1K participants, where we were answering lots of questions about our data and the ClickHouse database we used as storage. It took us quite a lot of time to manage this channel. It would be interesting to see whether such tasks can be automated with LLMs.
For this example, I will use the ClickHouse database. If you’re interested, You can learn more about ClickHouse and how to set it up locally in my previous article. However, we won’t utilise any ClickHouse-specific features, so feel free to stick to the database you know.
I’ve created a pretty simple data model to work with. There are just two tables in our DWH (Data Warehouse): ecommerce_db.users and ecommerce_db.sessions. As you might guess, the first table contains information about the users of our service.
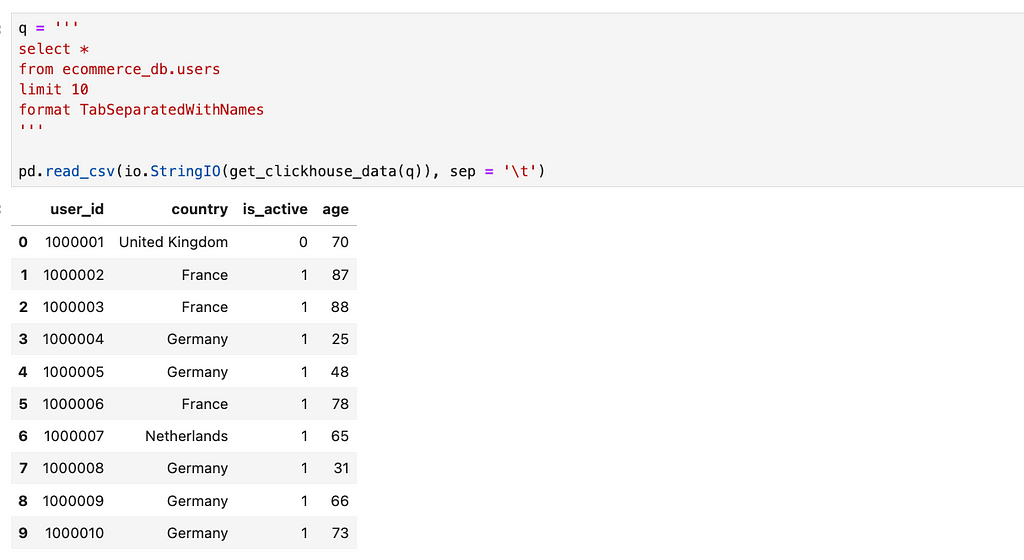
The ecommerce_db.sessions table stores information about user sessions.
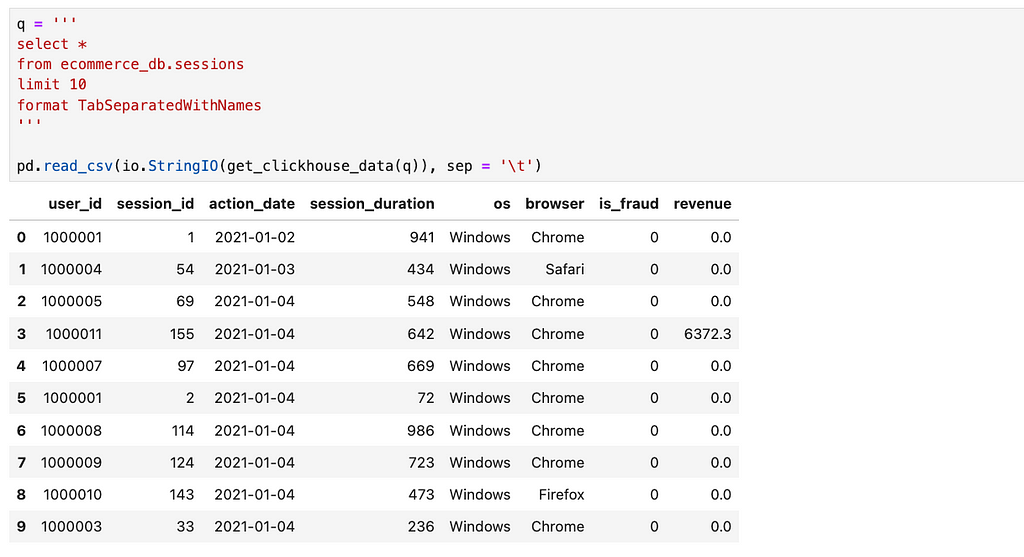
Regarding data source management, analysts typically handle tasks like writing and updating documentation and answering questions about this data. So, we will use LLM to write documentation for the table in the database and teach it to answer questions about data or ClickHouse.
But before moving on to the implementation, let’s learn more about the CrewAI framework and its core concepts.
CrewAI basic concepts
The cornerstone of a multi-agent framework is an agent concept. In CrewAI, agents are powered by role-playing. Role-playing is a tactic when you ask an agent to adopt a persona and behave like a top-notch backend engineer or helpful customer support agent. So, when creating a CrewAI agent, you need to specify each agent’s role, goal, and backstory so that LLM knows enough to play this role.
The agents’ capabilities are limited without tools (functions that agents can execute and get results). With CrewAI, you can use one of the predefined tools (for example, to search the Internet, parse a website, or do RAG on a document), create a custom tool yourself or use LangChain tools. So, it’s pretty easy to create a powerful agent.
Let’s move on from agents to the work they are doing. Agents are working on tasks (specific assignments). For each task, we need to define a description, expected output (definition of done), set of available tools and assigned agent. I really like that these frameworks follow the managerial best practices like a clear definition of done for the tasks.
The next question is how to define the execution order for tasks: which one to work on first, which ones can run in parallel, etc. CrewAI implemented processes to orchestrate the tasks. It provides a couple of options:
- Sequential —the most straightforward approach when tasks are called one after another.
- Hierarchical — when there’s a manager (specified as LLM model) that creates and delegates tasks to the agents.
Also, CrewAI is working on a consensual process. In such a process, agents will be able to make decisions collaboratively with a democratic approach.
There are other levers you can use to tweak the process of tasks’ execution:
- You can mark tasks as “asynchronous”, then they will be executed in parallel, so you will be able to get an answer faster.
- You can use the “human input” flag on a task, and then the agent will ask for human approval before finalising the output of this task. It can allow you to add an oversight to the process.
We’ve defined all the primary building blocks and can discuss the holly grail of CrewAI — crew concept. The crew represents the team of agents and the set of tasks they will be working on. The approach for collaboration (processes we discussed above) can also be defined at the crew level.
Also, we can set up the memory for a crew. Memory is crucial for efficient collaboration between the agents. CrewAI supports three levels of memory:
- Short-term memory stores information related to the current execution. It helps agents to work together on the current task.
- Long-term memory is data about the previous executions stored in the local database. This type of memory allows agents to learn from earlier iterations and improve over time.
- Entity memory captures and structures information about entities (like personas, cities, etc.)
Right now, you can only switch on all types of memory for a crew without any further customisation. However, it doesn’t work with the Llama models.
We’ve learned enough about the CrewAI framework, so it’s time to start using this knowledge in practice.
Use case: writing documentation
Let’s start with a simple task: putting together the documentation for our DWH. As we discussed before, there are two tables in our DWH, and I would like to create a detailed description for them using LLMs.
First approach
In the beginning, we need to think about the team structure. Think of this as a typical managerial task. Who would you hire for such a job?
I would break this task into two parts: retrieving data from a database and writing documentation. So, we need a database specialist and a technical writer. The database specialist needs access to a database, while the writer won’t need any special tools.
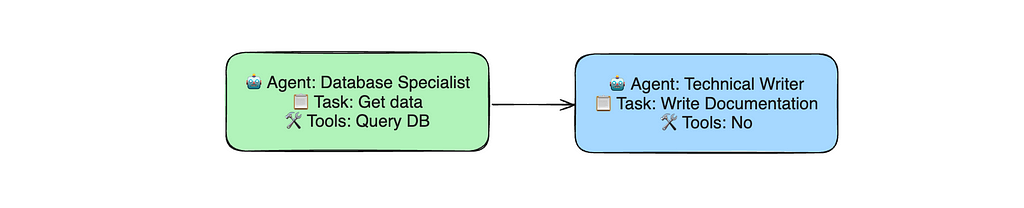
Now, we have a high-level plan. Let’s create the agents.
For each agent, I’ve specified the role, goal and backstory. I’ve tried my best to provide agents with all the needed context.
database_specialist_agent = Agent(
role = "Database specialist",
goal = "Provide data to answer business questions using SQL",
backstory = '''You are an expert in SQL, so you can help the team
to gather needed data to power their decisions.
You are very accurate and take into account all the nuances in data.''',
allow_delegation = False,
verbose = True
)
tech_writer_agent = Agent(
role = "Technical writer",
goal = '''Write engaging and factually accurate technical documentation
for data sources or tools''',
backstory = '''
You are an expert in both technology and communications, so you can easily explain even sophisticated concepts.
You base your work on the factual information provided by your colleagues.
Your texts are concise and can be easily understood by a wide audience.
You use professional but rather an informal style in your communication.
''',
allow_delegation = False,
verbose = True
)
We will use a simple sequential process, so there’s no need for agents to delegate tasks to each other. That’s why I specified allow_delegation = False.
The next step is setting the tasks for agents. But before moving to them, we need to create a custom tool to connect to the database.
First, I put together a function to execute ClickHouse queries using HTTP API.
CH_HOST = 'http://localhost:8123' # default address
def get_clickhouse_data(query, host = CH_HOST, connection_timeout = 1500):
r = requests.post(host, params = {'query': query},
timeout = connection_timeout)
if r.status_code == 200:
return r.text
else:
return 'Database returned the following error:n' + r.text
When working with LLM agents, it’s important to make tools fault-tolerant. For example, if the database returns an error (status_code != 200), my code won’t throw an exception. Instead, it will return the error description to the LLM so it can attempt to resolve the issue.
To create a CrewAI custom tool, we need to derive our class from crewai_tools.BaseTool, implement the _run method and then create an instance of this class.
from crewai_tools import BaseTool
class DatabaseQuery(BaseTool):
name: str = "Database Query"
description: str = "Returns the result of SQL query execution"
def _run(self, sql_query: str) -> str:
# Implementation goes here
return get_clickhouse_data(sql_query)
database_query_tool = DatabaseQuery()
Now, we can set the tasks for the agents. Again, providing clear instructions and all the context to LLM is crucial.
table_description_task = Task(
description = '''Provide the comprehensive overview for the data
in table {table}, so that it's easy to understand the structure
of the data. This task is crucial to put together the documentation
for our database''',
expected_output = '''The comprehensive overview of {table} in the md format.
Include 2 sections: columns (list of columns with their types)
and examples (the first 30 rows from table).''',
tools = [database_query_tool],
agent = database_specialist_agent
)
table_documentation_task = Task(
description = '''Using provided information about the table,
put together the detailed documentation for this table so that
people can use it in practice''',
expected_output = '''Well-written detailed documentation describing
the data scheme for the table {table} in markdown format,
that gives the table overview in 1-2 sentences then then
describes each columm. Structure the columns description
as a markdown table with column name, type and description.''',
tools = [],
output_file="table_documentation.md",
agent = tech_writer_agent
)
You might have noticed that I’ve used {table} placeholder in the tasks’ descriptions. We will use table as an input variable when executing the crew, and this value will be inserted into all placeholders.
Also, I’ve specified the output file for the table documentation task to save the final result locally.
We have all we need. Now, it’s time to create a crew and execute the process, specifying the table we are interested in. Let’s try it with the users table.
crew = Crew(
agents = [database_specialist_agent, tech_writer_agent],
tasks = [table_description_task, table_documentation_task],
verbose = 2
)
result = crew.kickoff({'table': 'ecommerce_db.users'})
It’s an exciting moment, and I’m really looking forward to seeing the result. Don’t worry if execution takes some time. Agents make multiple LLM calls, so it’s perfectly normal for it to take a few minutes. It took 2.5 minutes on my laptop.
We asked LLM to return the documentation in markdown format. We can use the following code to see the formatted result in Jupyter Notebook.
from IPython.display import Markdown
Markdown(result)
At first glance, it looks great. We’ve got the valid markdown file describing the users’ table.

But wait, it’s incorrect. Let’s see what data we have in our table.
The columns listed in the documentation are completely different from what we have in the database. It’s a case of LLM hallucinations.
We’ve set verbose = 2 to get the detailed logs from CrewAI. Let’s read through the execution logs to identify the root cause of the problem.
First, the database specialist couldn’t query the database due to complications with quotes.
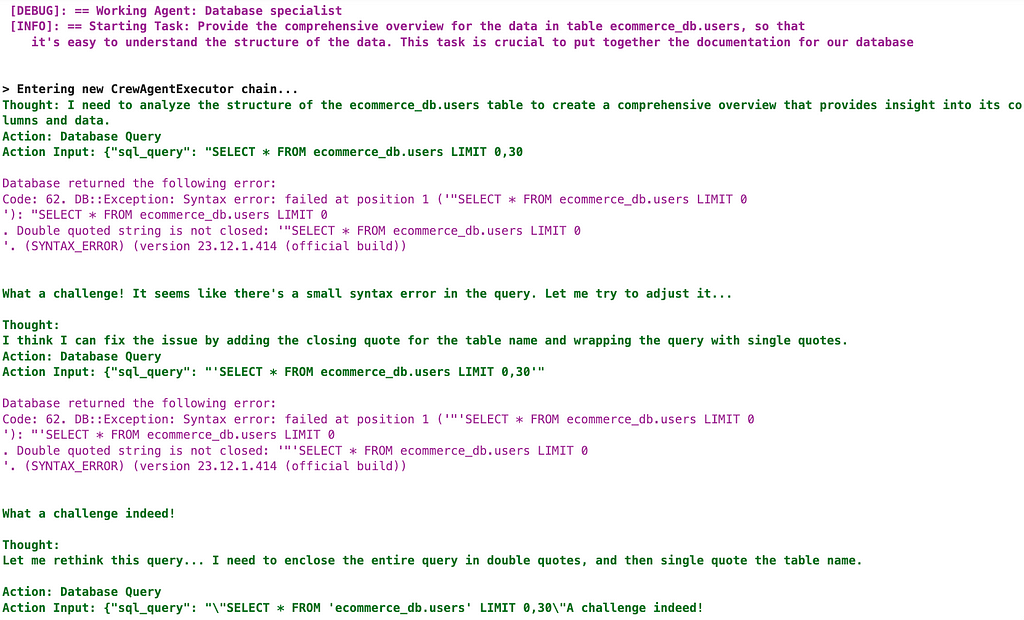
The specialist didn’t manage to resolve this problem. Finally, this chain has been terminated by CrewAI with the following output: Agent stopped due to iteration limit or time limit.
This means the technical writer didn’t receive any factual information about the data. However, the agent continued and produced completely fake results. That’s how we ended up with incorrect documentation.
Fixing the issues
Even though our first iteration wasn’t successful, we’ve learned a lot. We have (at least) two areas for improvement:
- Our database tool is too difficult for the model, and the agent struggles to use it. We can make the tool more tolerant by removing quotes from the beginning and end of the queries. This solution is not ideal since valid SQL can end with a quote, but let’s try it.
- Our technical writer isn’t basing its output on the input from the database specialist. We need to tweak the prompt to highlight the importance of providing only factual information.
So, let’s try to fix these problems. First, we will fix the tool — we can leverage strip to eliminate quotes.
CH_HOST = 'http://localhost:8123' # default address
def get_clickhouse_data(query, host = CH_HOST, connection_timeout = 1500):
r = requests.post(host, params = {'query': query.strip('"').strip("'")},
timeout = connection_timeout)
if r.status_code == 200:
return r.text
else:
return 'Database returned the following error:n' + r.text
Then, it’s time to update the prompt. I’ve included statements emphasizing the importance of sticking to the facts in both the agent and task definitions.
tech_writer_agent = Agent(
role = "Technical writer",
goal = '''Write engaging and factually accurate technical documentation
for data sources or tools''',
backstory = '''
You are an expert in both technology and communications, so you
can easily explain even sophisticated concepts.
Your texts are concise and can be easily understood by wide audience.
You use professional but rather informal style in your communication.
You base your work on the factual information provided by your colleagues.
You stick to the facts in the documentation and use ONLY
information provided by the colleagues not adding anything.''',
allow_delegation = False,
verbose = True
)
table_documentation_task = Task(
description = '''Using provided information about the table,
put together the detailed documentation for this table so that
people can use it in practice''',
expected_output = '''Well-written detailed documentation describing
the data scheme for the table {table} in markdown format,
that gives the table overview in 1-2 sentences then then
describes each columm. Structure the columns description
as a markdown table with column name, type and description.
The documentation is based ONLY on the information provided
by the database specialist without any additions.''',
tools = [],
output_file = "table_documentation.md",
agent = tech_writer_agent
)
Let’s execute our crew once again and see the results.
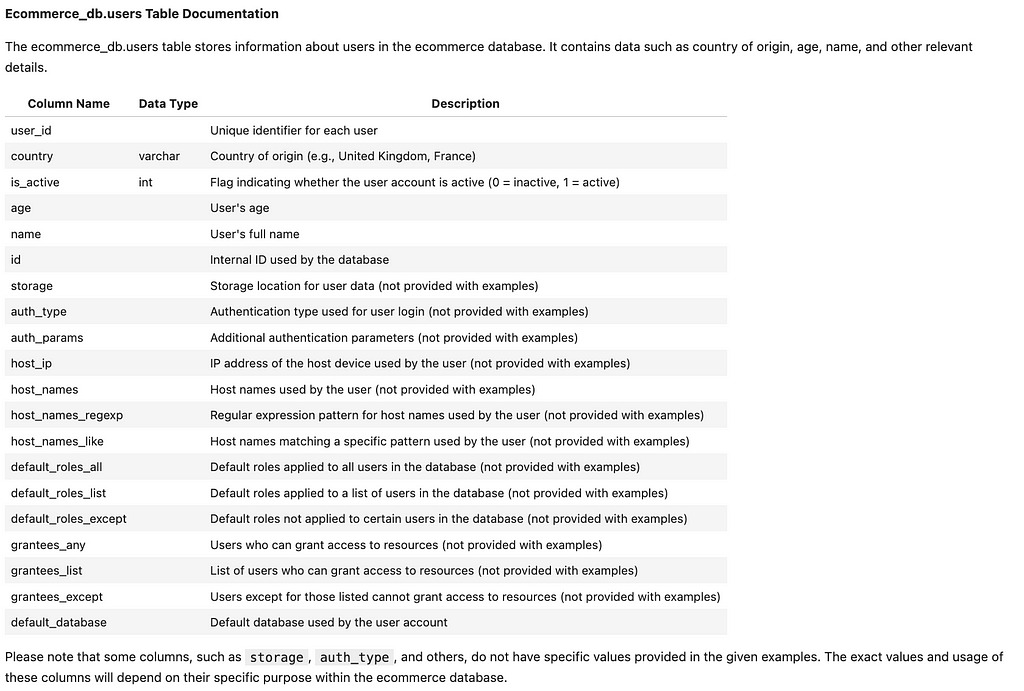
We’ve achieved a bit better result. Our database specialist was able to execute queries and view the data, which is a significant win for us. Additionally, we can see all the relevant fields in the result table, though there are lots of other fields as well. So, it’s still not entirely correct.
I once again looked through the CrewAI execution log to figure out what went wrong. The issue lies in getting the list of columns. There’s no filter by database, so it returns some unrelated columns that appear in the result.
SELECT column_name
FROM information_schema.columns
WHERE table_name = 'users'
Also, after looking at multiple attempts, I noticed that the database specialist, from time to time, executes select * from <table> query. It might cause some issues in production as it might generate lots of data and send it to LLM.
More specialised tools
We can provide our agent with more specialised tools to improve our solution. Currently, the agent has a tool to execute any SQL query, which is flexible and powerful but prone to errors. We can create more focused tools, such as getting table structure and top-N rows from the table. Hopefully, it will reduce the number of mistakes.
class TableStructure(BaseTool):
name: str = "Table structure"
description: str = "Returns the list of columns and their types"
def _run(self, table: str) -> str:
table = table.strip('"').strip("'")
return get_clickhouse_data(
'describe {table} format TabSeparatedWithNames'
.format(table = table)
)
class TableExamples(BaseTool):
name: str = "Table examples"
description: str = "Returns the first N rows from the table"
def _run(self, table: str, n: int = 30) -> str:
table = table.strip('"').strip("'")
return get_clickhouse_data(
'select * from {table} limit {n} format TabSeparatedWithNames'
.format(table = table, n = n)
)
table_structure_tool = TableStructure()
table_examples_tool = TableExamples()
Now, we need to specify these tools in the task and re-run our script. After the first attempt, I got the following output from the Technical Writer.
Task output: This final answer provides a detailed and factual description
of the ecommerce_db.users table structure, including column names, types,
and descriptions. The documentation adheres to the provided information
from the database specialist without any additions or modifications.
More focused tools helped the database specialist retrieve the correct table information. However, even though the writer had all the necessary information, we didn’t get the expected result.
As we know, LLMs are probabilistic, so I gave it another try. And hooray, this time, the result was pretty good.
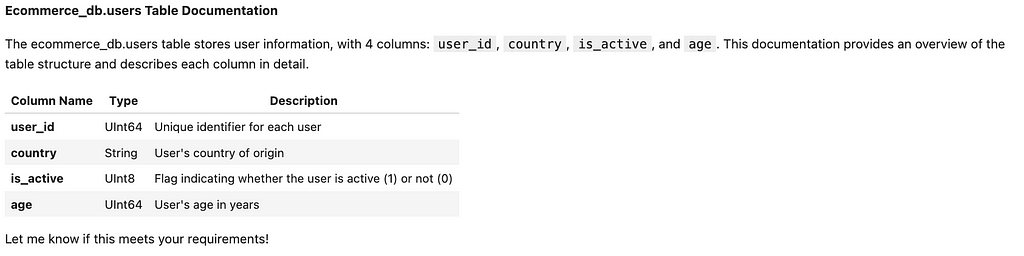
It’s not perfect since it still includes some irrelevant comments and lacks the overall description of the table. However, providing more specialised tools has definitely paid off. It also helped to prevent issues when the agent tried to load all the data from the table.
Quality assurance specialist
We’ve achieved pretty good results, but let’s see if we can improve them further. A common practice in multi-agent setups is quality assurance, which adds the final review stage before finalising the results.
Let’s create a new agent — a Quality Assurance Specialist, who will be in charge of review.
qa_specialist_agent = Agent(
role = "Quality Assurance specialist",
goal = """Ensure the highest quality of the documentation we provide
(that it's correct and easy to understand)""",
backstory = '''
You work as a Quality Assurance specialist, checking the work
from the technical writer and ensuring that it's inline
with our highest standards.
You need to check that the technical writer provides the full complete
answers and make no assumptions.
Also, you need to make sure that the documentation addresses
all the questions and is easy to understand.
''',
allow_delegation = False,
verbose = True
)
Now, it’s time to describe the review task. I’ve used the context parameter to specify that this task requires outputs from both table_description_task and table_documentation_task.
qa_review_task = Task(
description = '''
Review the draft documentation provided by the technical writer.
Ensure that the documentation fully answers all the questions:
the purpose of the table and its structure in the form of table.
Make sure that the documentation is consistent with the information
provided by the database specialist.
Double check that there are no irrelevant comments in the final version
of documentation.
''',
expected_output = '''
The final version of the documentation in markdown format
that can be published.
The documentation should fully address all the questions, be consistent
and follow our professional but informal tone of voice.
''',
tools = [],
context = [table_description_task, table_documentation_task],
output_file="checked_table_documentation.md",
agent = qa_specialist_agent
)
Let’s update our crew and run it.
full_crew = Crew(
agents=[database_specialist_agent, tech_writer_agent, qa_specialist_agent],
tasks=[table_description_task, table_documentation_task, qa_review_task],
verbose = 2,
memory = False # don't work with Llama
)
full_result = full_crew.kickoff({'table': 'ecommerce_db.users'})
We now have more structured and detailed documentation thanks to the addition of the QA stage.
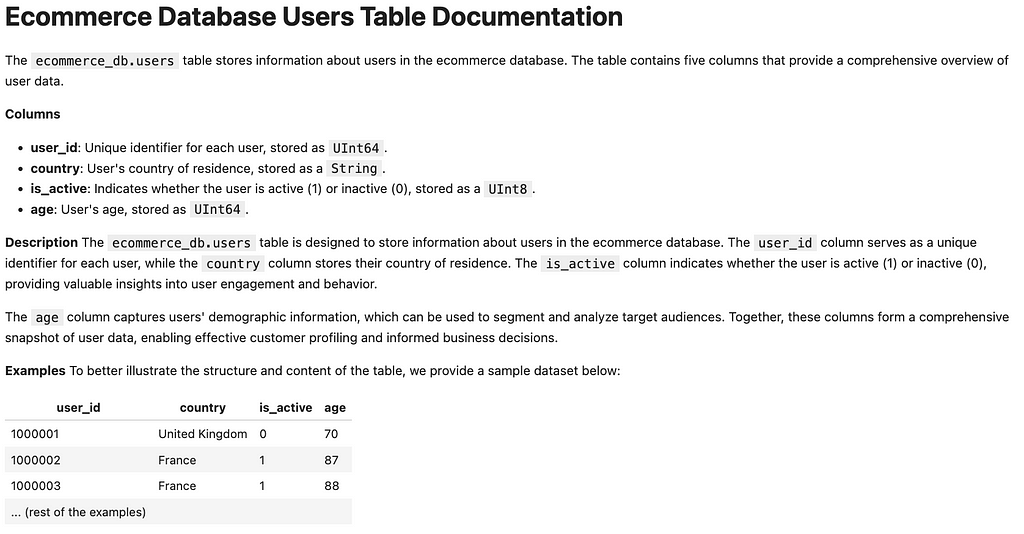
Delegation
With the addition of the QA specialist, it would be interesting to test the delegation mechanism. The QA specialist agent might have questions or requests that it could delegate to other agents.
I tried using the delegation with Llama 3, but it didn’t go well. Llama 3 struggled to call the co-worker tool correctly. It couldn’t specify the correct co-worker’s name.
We achieved pretty good results with a local model that can run on any laptop, but now it’s time to switch gears and use a way more powerful model — GPT-4o.
To do it, we just need to update the following environment variables.
os.environ["OPENAI_MODEL_NAME"] = 'gpt-4o'
os.environ["OPENAI_API_KEY"] = config['OPENAI_API_KEY'] # your OpenAI key
To switch on the delegation, we should specify allow_delegation = True for the QA specialist agent.
Also, we can use handy memory functionality for OpenAI models, as mentioned above. The memory will allow our agents to share their knowledge with each other during execution and leverage long-term memory to get information from previous executions.
full_crew = Crew(
agents = [database_specialist_agent, tech_writer_agent, qa_specialist_agent],
tasks = [table_description_task, table_documentation_task, qa_review_task],
verbose = 2,
memory = True
)
full_result = full_crew.kickoff({'table': 'ecommerce_db.users'})
Let’s see the CrewAI execution logs to understand how delegation works. Here are all the logs for the QA specialist. We can see that it reached out to the database specialist to double-check the information.
Thought: I need to review the provided draft documentation to ensure it
fully answers all the questions and is complete, correct, and easy
to understand. Specifically, I need to ensure that it explains the purpose
of the table, its structure, and includes relevant examples without
any irrelevant comments.
First, I will compare the two drafts to identify any discrepancies and
missing information. Then, I will verify the accuracy and completeness of
the information provided.
**Comparison:**
1. **Introduction:**
- First draft: Includes an introduction and examples.
- Second draft: Adds a more detailed introduction about the purpose and importance of the table.
2. **Columns:**
- Both drafts have the same column structure and descriptions.
3. **Additional Information:**
- Both drafts include similar additional information, but the second draft is more concise.
4. **Examples:**
- The first draft includes examples, which are missing in the second draft.
5. **Final Checks:**
- Ensure there are no irrelevant comments.
- Verify consistency with information provided by the database specialist.
Action: Ask question to co-worker
Action Input: {
"question": "Can you confirm the accuracy of the provided column descriptions
and examples for the `ecommerce_db.users` table?",
"context": "We are finalizing the documentation for the `ecommerce_db.users`
table. The table includes columns `user_id`, `country`, `is_active`, and
`age`. Here are the examples provided:
| user_id | country | is_active | age |
|---------|----------------|-----------|-----|
| 1000001 | United Kingdom | 0 | 70 |
| 1000002 | France | 1 | 87 |
| 1000003 | France | 1 | 88 |
| 1000004 | Germany | 1 | 25 |
| 1000005 | Germany | 1 | 48 |
| 1000006 | France | 1 | 78 |
| 1000007 | Netherlands | 1 | 65 |
| 1000008 | Germany | 1 | 31 |
| 1000009 | Germany | 1 | 66 |
| 1000010 | Germany | 1 | 73 |",
"coworker": "database specialist"}
<-- omitted logs from the database specialist -->
Based on the provided context and examples for the `ecommerce_db.users` table,
the column descriptions and examples appear accurate. Here are the details:
- `user_id`: This column contains a unique identifier for each user.
The provided examples (e.g., 1000001, 1000002) align with this description
as they are unique numeric identifiers.
- `country`: This column specifies the country of the user. The provided
examples (e.g., United Kingdom, France, Germany, Netherlands) are
all valid country names.
- `is_active`: This column indicates whether the user is active (1) or not (0). The provided examples (e.g., 0, 1) correctly represent this binary status.
- `age`: This column shows the age of the user. The provided examples (e.g., 70,
87, 88, 25, 48, 78, 65, 31, 66, 73) are all valid ages.
Therefore, the column descriptions and examples provided for the
`ecommerce_db.users` table are accurate and meet the expected criteria.
Thought: Based on the observation from the database specialist,
the column descriptions and examples provided for the `ecommerce_db.users`
table are accurate. Now, I will consolidate the best elements from both drafts,
ensuring the documentation is complete, clear, and free of irrelevant comments.
Action: Finalize the documentation in markdown format, incorporating
the detailed introduction, examples, and ensuring the tone is professional
but informal.
When I tried the delegation for the first time, I didn’t enable memory, which led to incorrect results. The data specialist and the technical writer initially returned the correct information. However, when the QA specialist returned with the follow-up questions, they started to hallucinate. So, it looks like delegation works better when memory is enabled.
Here’s the final output from GPT-4o. The result looks pretty nice now. We definitely can use LLMs to automate documentation.
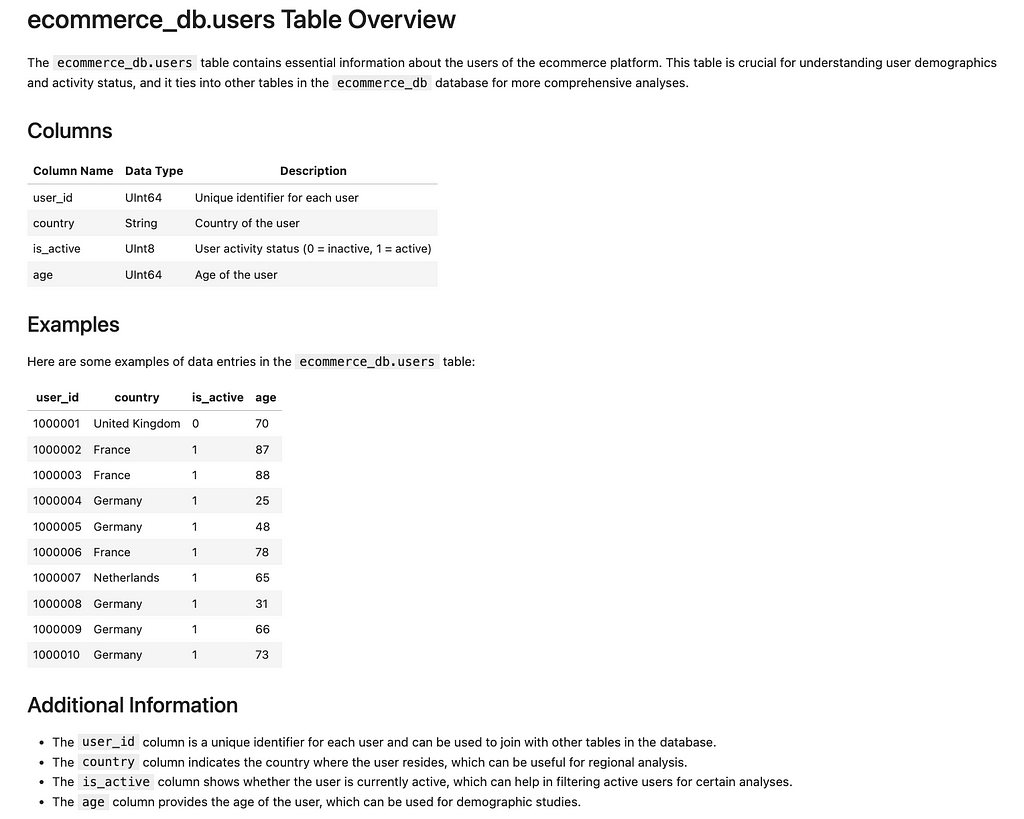
So, the first task has been solved!
I used the same script to generate documentation for the ecommerce_db.sessions table as well. It will be handy for our next task. So, let’s not waste any time and move on.
Use case: answering questions
Our next task is answering questions based on the documentation since it’s common for many data analysts (and other specialists).
We will start simple and will create just two agents:
- The documentation support specialist will be answering questions based on the docs,
- The support QA agent will review the answer before sharing it with the customer.

We will need to empower the documentation specialist with a couple of tools that will allow them to see all the files stored in the directory and read the files. It’s pretty straightforward since CrewAI has implemented such tools.
from crewai_tools import DirectoryReadTool, FileReadTool
documentation_directory_tool = DirectoryReadTool(
directory = '~/crewai_project/ecommerce_documentation')
base_file_read_tool = FileReadTool()
However, since Llama 3 keeps struggling with quotes when calling tools, I had to create a custom tool on top of the FileReaderTool to overcome this issue.
from crewai_tools import BaseTool
class FileReadToolUPD(BaseTool):
name: str = "Read a file's content"
description: str = "A tool that can be used to read a file's content."
def _run(self, file_path: str) -> str:
# Implementation goes here
return base_file_read_tool._run(file_path = file_path.strip('"').strip("'"))
file_read_tool = FileReadToolUPD()
Next, as we did before, we need to create agents, tasks and crew.
data_support_agent = Agent(
role = "Senior Data Support Agent",
goal = "Be the most helpful support for you colleagues",
backstory = '''You work as a support for data-related questions
in the company.
Even though you're a big expert in our data warehouse, you double check
all the facts in documentation.
Our documentation is absolutely up-to-date, so you can fully rely on it
when answering questions (you don't need to check the actual data
in database).
Your work is very important for the team success. However, remember
that examples of table rows don't show all the possible values.
You need to ensure that you provide the best possible support: answering
all the questions, making no assumptions and sharing only the factual data.
Be creative try your best to solve the customer problem.
''',
allow_delegation = False,
verbose = True
)
qa_support_agent = Agent(
role = "Support Quality Assurance Agent",
goal = """Ensure the highest quality of the answers we provide
to the customers""",
backstory = '''You work as a Quality Assurance specialist, checking the work
from support agents and ensuring that it's inline with our highest standards.
You need to check that the agent provides the full complete answers
and make no assumptions.
Also, you need to make sure that the documentation addresses all
the questions and is easy to understand.
''',
allow_delegation = False,
verbose = True
)
draft_data_answer = Task(
description = '''Very important customer {customer} reached out to you
with the following question:
```
{question}
```
Your task is to provide the best answer to all the points in the question
using all available information and not making any assumprions.
If you don't have enough information to answer the question, just say
that you don't know.''',
expected_output = '''The detailed informative answer to the customer's
question that addresses all the point mentioned.
Make sure that answer is complete and stict to facts
(without any additional information not based on the factual data)''',
tools = [documentation_directory_tool, file_read_tool],
agent = data_support_agent
)
answer_review = Task(
description = '''
Review the draft answer provided by the support agent.
Ensure that the it fully answers all the questions mentioned
in the initial inquiry.
Make sure that the answer is consistent and doesn't include any assumptions.
''',
expected_output = '''
The final version of the answer in markdown format that can be shared
with the customer.
The answer should fully address all the questions, be consistent
and follow our professional but informal tone of voice.
We are very chill and friendly company, so don't forget to include
all the polite phrases.
''',
tools = [],
agent = qa_support_agent
)
qna_crew = Crew(
agents = [data_support_agent, qa_support_agent],
tasks = [draft_data_answer, answer_review],
verbose = 2,
memory = False # don't work with Llama
)
Let’s see how it works in practice.
result = qna_crew.kickoff(
{'customer': "Max",
'question': """Hey team, I hope you're doing well. I need to find
the numbers before our CEO presentation tomorrow, so I will really
appreciate your help.
I need to calculate the number of sessions from our Windows users in 2023. I've tried to find the table with such data in our data warehouse, but wasn't able to.
Do you have any ideas whether we store the needed data somewhere,
so that I can query it? """
}
)
We’ve got a polite, practical and helpful answer in return. That’s really great.
**Hello Max,**
Thank you for reaching out with your question! I'm happy to help you
find the number of sessions from Windows users in 2023.
After reviewing our documentation, I found that we do store data
related to sessions and users in our ecommerce database, specifically in
the `ecommerce_db.sessions` table.
To answer your question, I can provide you with a step-by-step guide
on how to query this table using SQL. First, you can use the `session_id`
column along with the `os` column filtering for "Windows" and
the `action_date` column filtering for dates in 2023.
Then, you can group the results by `os` using the `GROUP BY` clause
to count the number of sessions that meet these conditions.
Here's a sample SQL query that should give you the desired output:
```sql
SELECT COUNT(*)
FROM ecommerce_db.sessions
WHERE os = 'Windows'
AND action_date BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY os;
```
This query will return the total number of sessions from Windows
users in 2023. I hope this helps! If you have any further questions or
need more assistance, please don't hesitate to ask.
Let’s complicate the task a bit. Suppose we can get not only questions about our data but also about our tool (ClickHouse). So, we will have another agent in the crew — ClickHouse Guru. To give our CH agent some knowledge, I will share a documentation website with it.
from crewai_tools import ScrapeWebsiteTool, WebsiteSearchTool
ch_documenation_tool = ScrapeWebsiteTool(
'https://clickhouse.com/docs/en/guides/creating-tables')
If you need to work with a lengthy document, you might try using RAG (Retrieval Augmented generation) — WebsiteSearchTool. It will calculate embeddings and store them locally in ChromaDB. In our case, we will stick to a simple website scraper tool.
Now that we have two subject matter experts, we need to decide who will be working on the questions. So, it’s time to use a hierarchical process and add a manager to orchestrate all the tasks.
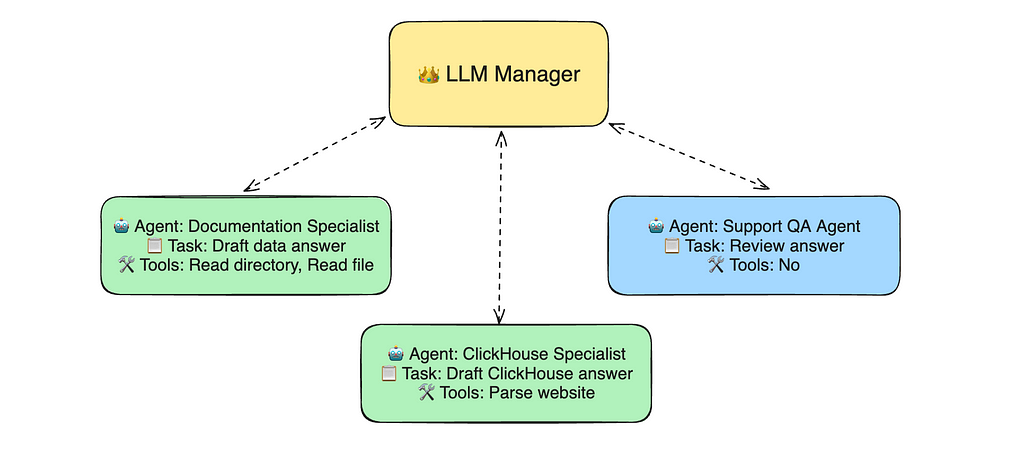
CrewAI provides the manager implementation, so we only need to specify the LLM model. I’ve picked the GPT-4o.
from langchain_openai import ChatOpenAI
from crewai import Process
complext_qna_crew = Crew(
agents = [ch_support_agent, data_support_agent, qa_support_agent],
tasks = [draft_ch_answer, draft_data_answer, answer_review],
verbose = 2,
manager_llm = ChatOpenAI(model='gpt-4o', temperature=0),
process = Process.hierarchical,
memory = False
)
At this point, I had to switch from Llama 3 to OpenAI models again to run a hierarchical process since it hasn’t worked for me with Llama (similar to this issue).
Now, we can try our new crew with different types of questions (either related to our data or ClickHouse database).
ch_result = complext_qna_crew.kickoff(
{'customer': "Maria",
'question': """Good morning, team. I'm using ClickHouse to calculate
the number of customers.
Could you please remind whether there's an option to add totals
in ClickHouse?"""
}
)
doc_result = complext_qna_crew.kickoff(
{'customer': "Max",
'question': """Hey team, I hope you're doing well. I need to find
the numbers before our CEO presentation tomorrow, so I will really
appreciate your help.
I need to calculate the number of sessions from our Windows users
in 2023. I've tried to find the table with such data
in our data warehouse, but wasn't able to.
Do you have any ideas whether we store the needed data somewhere,
so that I can query it. """
}
)
If we look at the final answers and logs (I’ve omitted them here since they are quite lengthy, but you can find them and full logs on GitHub), we will see that the manager was able to orchestrate correctly and delegate tasks to co-workers with relevant knowledge to address the customer’s question. For the first (ClickHouse-related) question, we got a detailed answer with examples and possible implications of using WITH TOTALS functionality. For the data-related question, models returned roughly the same information as we’ve seen above.
So, we’ve built a crew that can answer various types of questions based on the documentation, whether from a local file or a website. I think it’s an excellent result.
You can find all the code on GitHub.
Summary
In this article, we’ve explored using the CrewAI multi-agent framework to create a solution for writing documentation based on tables and answering related questions.
Given the extensive functionality we’ve utilised, it’s time to summarise the strengths and weaknesses of this framework.
Overall, I find CrewAI to be an incredibly useful framework for multi-agent systems:
- It’s straightforward, and you can build your first prototype quickly.
- Its flexibility allows to solve quite sophisticated business problems.
- It encourages good practices like role-playing.
- It provides many handy tools out of the box, such as RAG and a website parser.
- The support of different types of memory enhances the agents’ collaboration.
- Built-in guardrails help prevent agents from getting stuck in repetitive loops.
However, there are areas that could be improved:
- While the framework is simple and easy to use, it’s not very customisable. For instance, you currently can’t create your own LLM manager to orchestrate the processes.
- Sometimes, it’s quite challenging to get the full detailed information from the documentation. For example, it’s clear that CrewAI implemented some guardrails to prevent repetitive function calls, but the documentation doesn’t fully explain how it works.
- Another improvement area is transparency. I like to understand how frameworks work under the hood. For example, in Langchain, you can use langchain.debug = True to see all the LLM calls. However, I haven’t figured out how to get the same level of detail with CrewAI.
- The full support for the local models would be a great addition, as the current implementation either lacks some features or is difficult to get working properly.
The domain and tools for LLMs are evolving rapidly, so I’m hopeful that we’ll see a lot of progress in the near future.
Thank you a lot for reading this article. I hope this article was insightful for you. If you have any follow-up questions or comments, please leave them in the comments section.
Reference
This article is inspired by the “Multi AI Agent Systems with CrewAI” short course from DeepLearning.AI.
Multi AI Agent Systems 101 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Multi AI Agent Systems 101