

A brief review of the image foundation model pre-training objectives
We crave large models, don’t we?
The GPT series has proved its ability to revolutionize the NLP world, and everyone is excited to see the same transformation in the computer vision domain. The most popular image foundation models in recent years include SegmentAnything, DINOv2, and many others. The natural question is, what are the key differences between the pre-training stage of these foundation models?
Instead of answering this question directly, we will gently review the image foundation model pre-training objectives using Masked Image Modeling in this blog article. We will also discuss a paper (to be) published in ICML’24, applying the Autoregression Modeling to foundation model pre-training.
What is model pre-training in LLM?
Model pre-training is a terminology used in general large models (LLM, image foundation models) to describe the stage where no label is given to the model, but training the model purely using a self-supervised manner.
Common pre-training techniques mostly originated from LLMs. For example, the BERT model used Masked Language Modeling, which inspired Masked Image Modeling such as BEiT, MAE-ViT, and SimMM. The GPT series used Autoregressive Language Modeling, and a recently accepted ICML publication extended this idea to Autoregressive Image Modeling.
So, what are Masked Language Modeling and Autoregressive Language Modeling?
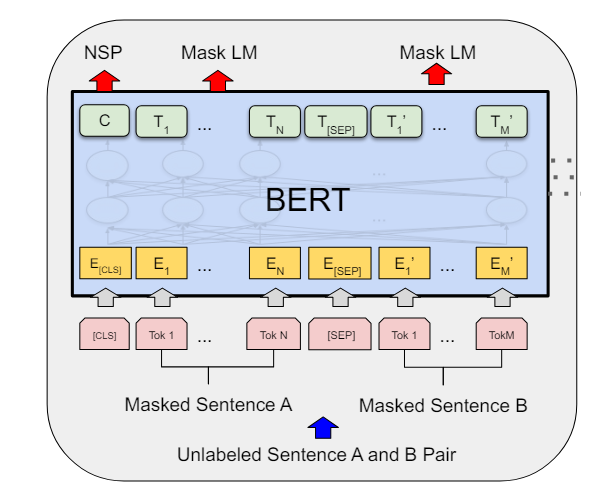
The Masked Language Modeling was first proposed in the BERT paper in 2018. The approach was described as “simply masking some percentage of the input tokens randomly and then predicting those masked tokens.” It’s a bi-directional representation approach, as the model will try to predict back and forth at the masked token.
The Autoregressive Language Modeling was famously known from the GPT3 paper. It has a clearer definition in the XLNet paper as follows, and we can see the model is unidirectional. The reason the GPT series uses a unidirectional language model is that the architecture is decoder-based, which only needs self-attention on the prompt and the completion:

Pre-training in Image Domain
When moving into the image domain, the immediate question is how we form the image “token sequence.” The natural thinking is just to use the ViT architecture, breaking an image into a grid of image patches (visual tokens).
BEiT. Published as an arXiv preprint in 2022, the idea of BEiT is straightforward. After tokenizing an image into a sequence of 14*14 visual tokens, 40% of the tokens are randomly masked, replaced by learnable embeddings, and fed into the transformer. The pre-training objective is to maximize the log-likelihood of the correct visual tokens, and no decoder is needed for this stage. The pipeline is shown in the figure below.
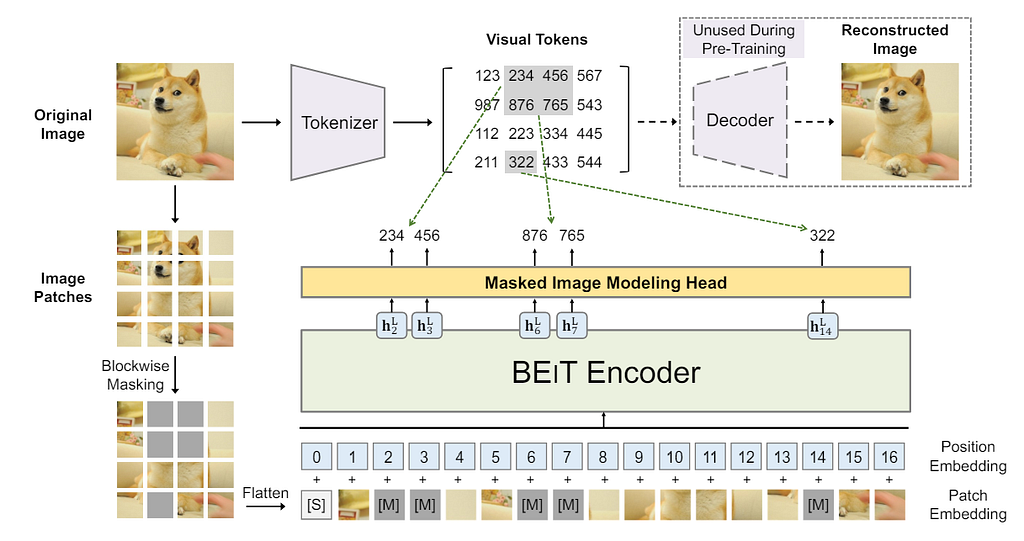
In the original paper, the authors also provided a theoretical link between the BEiT and the Variational Autoencoder. So the natural question is, can an Autoencoder be used for pre-training purposes?
MAE-ViT. This paper answered the question above by designing a masked autoencoder architecture. Using the same ViT formulation and random masking, the authors proposed to “discard” the masked patches during training and only use unmasked patches in the visual token sequence as input to the encoder. The mask tokens will be used for reconstruction during the decoding stage at the pre-training. The decoder could be flexible, ranging from 1–12 transformer blocks with dimensionality between 128 and 1024. More detailed architectural information could be found in the original paper.

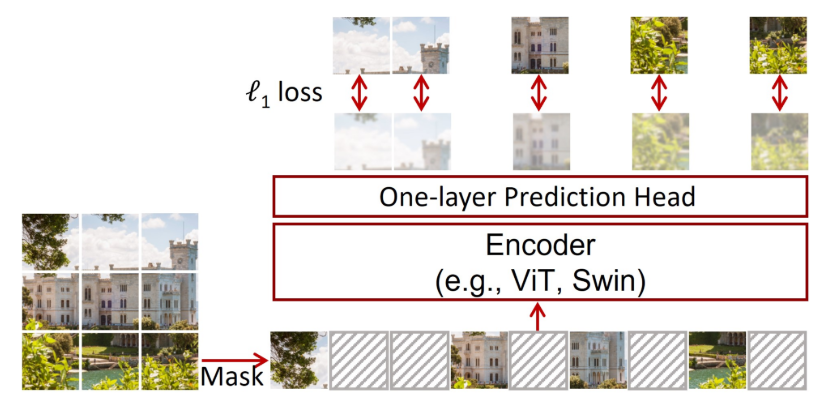
SimMIM. Slightly different from BEiT and MAE-ViT, the paper proposes using a flexible backbone such as Swin Transformer for encoding purposes. The proposed prediction head is extremely lightweight—a single linear layer of a 2-layer MLP to regress the masked pixels.
AIM. A recent paper accepted by ICML’24 proposed using the Autoregressive model (or causal model) for pre-training purposes. Instead of using a masked sequence, the model takes the full sequence to a causal transformer, using prefixed self-attention with causal masks.

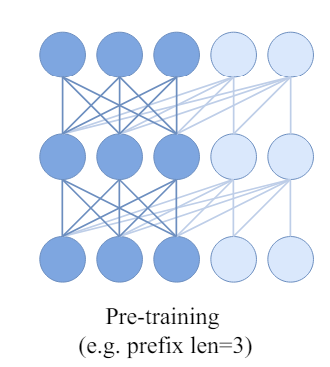
What is prefixed causal attention? There are detailed tutorials on causal attention masking on Kaggle, and here, it is masking out “future” tokens on self-attention. However, in this paper, the authors claim that the discrepancy between the causal mask and downstream bidirectional self-attention would lead to a performance issue. The solution is to use partial causal masking or prefixed causal attention. In the prefix sequence, bidirectional self-attention is used, and causal attention is applied for the rest of the sequence.
What is the advantage of Autoregressive Image Masking? The answer lies in the scaling, of both the model and data sizes. The paper claims that the model scale directly correlates with the pre-training loss and the downstream task performance (the following left subplot). The uncurated pre-training data scale is also directly linked to the downstream task performance (the following right subplot).
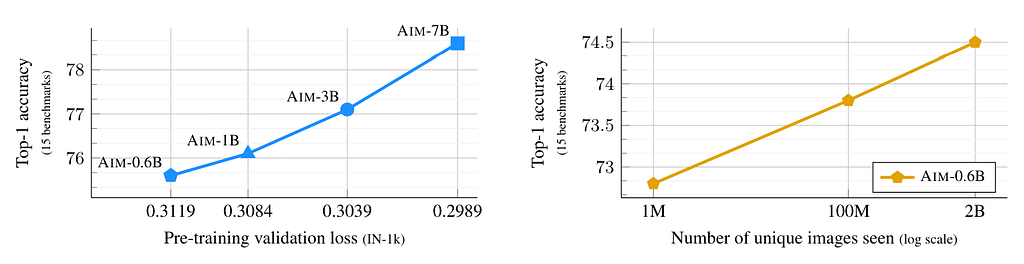
Compared to a 50% masking ratio, the AIM achieved an astonishing 8% performance increase over Masked Image Modeling.

So, what is the big takeaway here? The AIM paper discussed different trade-offs between the state-of-the-art pre-training methods, and we won’t repeat them here. A shallower but more intuitive lesson is that there is likely still much work left to improve the vision foundation models using existing experience from the LLM domain, especially on scalability. Hopefully, we’ll see those improvements in the coming years.
References
- El-Nouby et al., Scalable Pre-training of Large Autoregressive Image Models. ICML 2024. Github: https://github.com/apple/ml-aim
- Xie et al., SimMIM: a Simple Framework for Masked Image Modeling. CVPR 2022. Github: https://github.com/microsoft/SimMIM
- Bao et al., BEiT: BERT Pre-Training of Image Transformers. arXiv preprint 2022. Github: https://github.com/microsoft/unilm/tree/master/beit
- He et al., Masked autoencoders are scalable vision learners. CVPR 2022. HuggingFace Official: https://huggingface.co/docs/transformers/en/model_doc/vit_mae
- Caron et al., Emerging Properties in Self-Supervised Vision Transformers. ICCV 2021. Github: https://github.com/facebookresearch/dino?tab=readme-ov-file
- Liu et al., Swin transformer: Hierarchical vision transformer using shifted windows. ICCV 2021. Github: https://github.com/microsoft/Swin-Transformer
- Brown et al., Language Models are Few-Shot Learners. NeurIPS 2020. Github: https://github.com/openai/gpt-3
- Yang et al., Xlnet: Generalized autoregressive pretraining for language understanding. NeurIPS 2019. Github: https://github.com/zihangdai/xlnet
- Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint 2018. HuggingFace Official: https://huggingface.co/docs/transformers/en/model_doc/bert
From Masked Image Modeling to Autoregressive Image Modeling was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Masked Image Modeling to Autoregressive Image Modeling
Go Here to Read this Fast! From Masked Image Modeling to Autoregressive Image Modeling