Using Monosemanticity to understand the concepts a Large Language Model learned
With the increasing use of Large Language Models (LLMs), the need for understanding their reasoning and behavior increases as well. In this article, I want to present to you an approach that sheds some light on the concepts an LLM represents internally. In this approach, a representation is extracted that allows one to understand a model’s activation in terms of discrete concepts being used for a given input. This is called Monosemanticity, indicating that these concepts have just a single (mono) meaning (semantic).
In this article, I will first describe the main idea behind Monosemanticity. For that, I will explain sparse autoencoders, which are a core mechanism within the approach, and show how they are used to structure an LLM’s activation in an interpretable way. Then I will retrace some demonstrations the authors of the Monosemanticity approach proposed to explain the insights of their approach, which closely follows their original publication.
Sparse autoencoders

We have to start by taking a look at sparse autoencoders. First of all, an autoencoder is a neural net that is trained to reproduce a given input, i.e. it is supposed to produce exactly the vector it was given. Now you wonder, what’s the point? The important detail is, that the autoencoder has intermediate layers that are smaller than the input and output. Passing information through these layers necessarily leads to a loss of information and hence the model is not able to just learn the element by heart and reproduce it fully. It has to pass the information through a bottleneck and hence needs to come up with a dense representation of the input that still allows it to reproduce it as well as possible. The first half of the model we call the encoder (from input to bottleneck) and the second half we call the decoder (from bottleneck to output). After having trained the model, you may throw away the decoder. The encoder now transforms a given input into a representation that keeps important information but has a different structure than the input and potentially removes unneeded parts of the data.
To make an autoencoder sparse, its objective is extended. Besides reconstructing the input as well as possible, the model is also encouraged to activate as few neurons as possible. Instead of using all the neurons a little, it should focus on using just a few of them but with a high activation. This also allows to have more neurons in total, making the bottleneck disappear in the model’s architecture. However, the fact that activating too many neurons is punished still keeps the idea of compressing the data as much as possible. The neurons that are activated are then expected to represent important concepts that describe the data in a meaningful way. We call them features from now on.
In the original Monosemanticity publication, such a sparse autoencoder is trained on an intermediate layer in the middle of the Claude 3 Sonnet model (an LLM published by Anthropic that can be said to play in the same league as the GPT models from OpenAI). That is, you can take some tokens (i.e. text snippets), forward them to the first half of the Claude 3 Sonnett model, and forward that activation to the sparse autoencoder. You will then get an activation of the features that represent the input. However, we don’t really know what these features mean so far. To find out, let’s imagine we feed the following texts to the model:
- The cat is chasing the dog.
- My cat is lying on the couch all day long.
- I don’t have a cat.
If there is one feature that activates for all three of the sentences, you may guess that this feature represents the idea of a cat. There may be other features though, that just activate for single sentences but not for the others. For sentence one, you would expect the feature for dog to be activated, and to represent the meaning of sentence three, you would expect a feature that represents some form of negation or “not having something”.
Different features

From the aforementioned example, we saw that features can describe quite different things. There may be features that represent concrete objects or entities (such as cats, the Eiffel Tower, or Benedict Cumberbatch), but there may also be features dedicated to more abstract concepts like sadness, gender, revolution, lying, things that can melt or the german letter ß (yes, we indeed have an additional letter just for ourselves). As the model also saw programming code during its training, it also includes many features that are related to programming languages, representing contexts such as code errors or computational functions. You can explore the features of the Claude 3 model here.
If the model is capable of speaking multiple languages, the features are found to be multilingual. That means, a feature that corresponds to, say, the concept of sorrow, would be activated in relevant sentences in each language. In a likewise fashion, the features are also multimodal, if the model is able to work with different input modalities. The Benedict Cumberbatch feature would then activate for the name, but also for pictures or verbal mentions of Benedict Cumberbatch.
Influence on behavior

So far we have seen that certain features are activated when the model produces a certain output. From a model’s perspective, the direction of causality is the other way round though. If the feature for the Golden Gate Bridge is activated, this causes the model to produce an answer that is related to this feature’s concept. In the following, this is demonstrated by artificially increasing the activation of a feature within the model’s inference.

On the left, we see the answers to two questions in the normal setup, and on the right we see, how these answers change if the activation of the features Golden Gate Bridge (first row) and brain sciences (second row) are increased. It is quite intuitive, that activating these features makes the model produce texts that include the concepts of the Golden Gate Bridge and brain sciences. In the usual case, the features are activated from the model’s input and its prompt, but with the approach we saw here, one can also activate some features in a more deliberate and explicit way. You could think of always activating the politeness feature to steer the model’s answers in the desired way. Without the notion of features, you would do that by adding instructions to the prompt such as “always be polite in your answers”, but with the feature concept, this could be done more explicitly. On the other hand, you can also think of deactivating features explicitly to avoid the model telling you how to build an atomic bomb or conduct tax fraud.
Taking a deeper look: Specificity, Sensitivity and Completeness

Now that we have understood how the features are extracted, we can follow some of the author’s experiments that show us which features and concepts the model actually learned.
First, we want to know how specific the features are, i.e. how well they stick to their exact concept. We may ask, does the feature that represents Benedict Cumberbatch indeed activate only for Benedict Cumberbatch and not for other actors? To shed some light on this question, the authors used an LLM to rate texts regarding their relevance to a given concept. In the following example, it was assessed how much a text relates to the concept of brain science on a scale from 0 (completely irrelevant) to 3 (very relevant). In the next figure, we see these ratings as the colors (blue for 0, red for 3) and we see the activation level on the x-axis. The more we go to the right, the more the feature is activated.
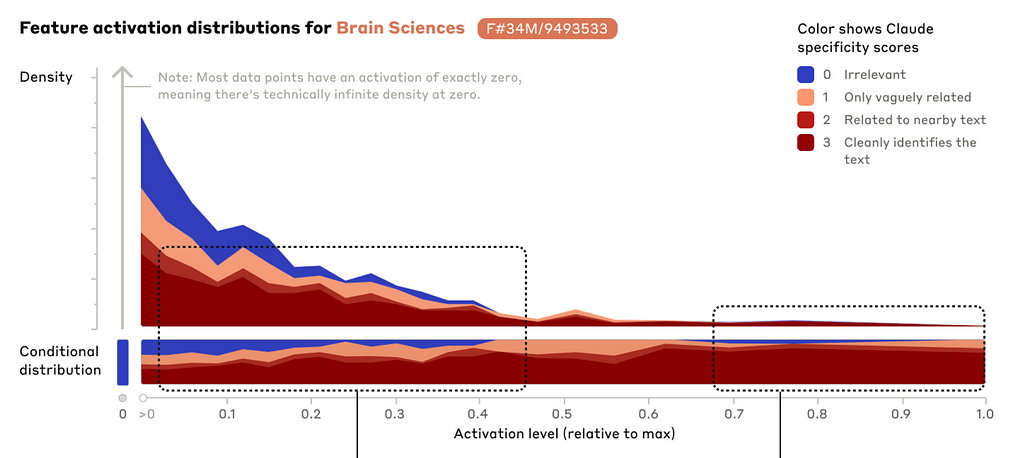
We see a clear correlation between the activation (x-axis) and the relevance (color). The higher the activation, the more often the text is considered highly relevant to the topic of brain sciences. The other way round, for texts that are of little or no relevance to the topic of brain sciences, the feature only activates marginally (if at all). That means, that the feature is quite specific for the topic of brain science and does not activate that much for related topics such as psychology or medicine.
Sensitivity
The other side of the coin to specificity is sensitivity. We just saw an example, of how a feature activates only for its topic and not for related topics (at least not so much), which is the specificity. Sensitivity now asks the question “but does it activate for every mention of the topic?” In general, you can easily have the one without the other. A feature may only activate for the topic of brain science (high specificity), but it may miss the topic in many sentences (low sensitivity).
The authors spend less effort on the investigation of sensitivity. However, there is a demonstration that is quite easy to understand: The feature for the Golden Gate Bridge activates for sentences on that topic in many different languages, even without the explicit mention of the English term “Golden Gate Bridge”. More fine-grained analyses are quite difficult here because it is not always clear what a feature is supposed to represent in detail. Say you have a feature that you think represents Benedict Cumberbatch. Now you find out, that it is very specific (reacting to Benedict Cumberbatch only), but only reacts to some — not all — pictures. How can you know, if the feature is just insensitive, or if it is rather a feature for a more fine-grained subconcept such as Sherlock from the BBC series (played by Benedict Cumberbatch)?
Completeness
In addition to the features’ activation for their concepts (specificity and sensitivity), you may wonder if the model has features for all important concepts. It is quite difficult to decide which concepts it should have though. Do you really need a feature for Benedict Cumberbatch? Are “sadness” and “feeling sad” two different features? Is “misbehaving” a feature on its own, or can it be represented by the combination of the features for “behaving” and “negation”?
To catch a glance at the feature completeness, the authors selected some categories of concepts that have a limited number such as the elements in the periodic table. In the following figure, we see all the elements on the x-axis and we see whether a corresponding feature has been found for three different sizes of the autoencoder model (from 1 million to 34 million parameters).

It is not surprising, that the biggest autoencoder has features for more different elements of the periodic table than the smaller ones. However, it also doesn’t catch all of them. We don’t know though, if this really means, that the model does not have a clear concept of, say, Bohrium, or if it just did not survive within the autoencoder.
Limitations
While we saw some demonstrations of the features representing the concepts the model learned, we have to emphasize that these were in fact qualitative demonstrations and not quantitative evaluations. All the examples were great to get an idea of what the model actually learned and to demonstrate the usefulness of the Monosemanticity approach. However, a formal evaluation that assesses all the features in a systematic way is needed, to really backen the insights gained from such investigations. That is easy to say and hard to conduct, as it is not clear, how such an evaluation could look like. Future research is needed to find ways to underpin such demonstrations with quantitative and systematic data.
Summary

We just saw an approach that allows to gain some insights into the concepts a Large Language Model may leverage to arrive at its answers. A number of demonstrations showed how the features extracted with a sparse autoencoder can be interpreted in a quite intuitive way. This promises a new way to understand Large Language Models. If you know that the model has a feature for the concept of lying, you could expect it do to so, and having a concept of politeness (vs. not having it) can influence its answers quite a lot. For a given input, the features can also be used to understand the model’s thought traces. When asking a model to tell a story, the activation of the feature happy end may explain how it comes to a certain ending, and when the model does your tax declaration, you may want to know if the concept of fraud is activated or not.
As we see, there is quite some potential to understand LLMs in more detail. A more formal and systematical evaluation of the features is needed though, to back the promises this format of analysis introduces.
Sources
This article is based on this publication, where the Monosemanticity approach is applied to an LLM:
There is also a previous work that introduces the core ideas in a more basic model:
For the Claude 3 model that has been analyzed, see here:
The features can be explored here:
Like this article? Follow me to be notified of my future posts.
Take a look under the hood was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Take a look under the hood