

Or, When you feel your life’s too hard, just go have a talk with Claude
When I think about the challenges involved in understanding complex systems, I often think back to something that happened during my time at Tripadvisor. I was helping our Machine Learning team conduct an analysis for the Growth Marketing team to understand what customer behaviors were predictive of high LTV. We worked with a talented Ph.D. Data Scientist who trained a logistic regression model and printed out the coefficients as a first pass.
When we looked at the analysis with the Growth team, they were confused — logistic regression coefficients are tough to interpret because their scale isn’t linear, and the features that ended up being most predictive weren’t things that the Growth team could easily influence. We all stroked our chins for a minute and opened a ticket for some follow-up analysis, but as so often happens, both teams quickly moved on to their next bright idea. The Data Scientist had some high priority work to do on our search ranking algorithm, and for all practical purposes, the Growth team tossed the analysis into the trash heap.
I still think about that exercise — Did we give up too soon? What if the feedback loop had been tighter? What if both parties had kept digging? What would the second or the third pass have revealed?
Unlocking exploratory analysis at scale
The anecdote above describes an exploratory analysis that didn’t quite land. Exploratory analysis is distinct from descriptive analysis, which simply aims to describe what’s happening. Exploratory analysis seeks to gain a greater understanding of a system, rather than a well-defined question. Consider the following types of questions one might encounter in a business context:
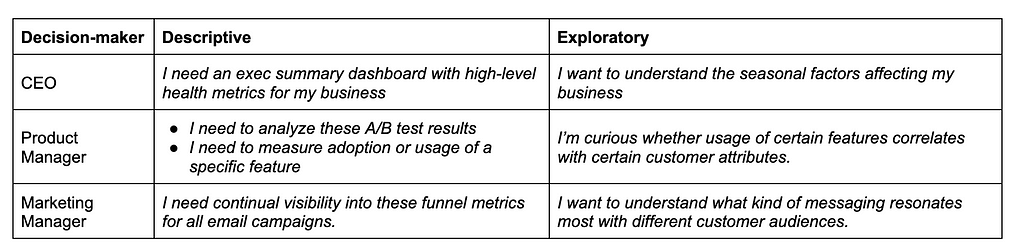
Notice how the exploratory questions are open-ended and aim to improve one’s understanding of a complex problem space. Exploratory analysis often requires more cycles and tighter partnership between the “domain expert” and the person actually conducting the analysis, who are seldom the same person. In the anecdote above, the partnership wasn’t tight enough, the feedback loops weren’t short enough, and we didn’t devote enough cycles.
These challenges are why many experts advocate for a “paired analysis” approach for data exploration. Similar to paired programming, paired analysis brings an analyst and decision maker together to conduct an exploration in real-time. Unfortunately, this type of tight partnership between analyst and decision maker rarely occurs in practice due to resource and time constraints.
Now think about the organization you work in — what if every decision maker had an experienced analyst to pair with them? What if they had that analyst’s undivided attention and could pepper them with follow-up questions at will? What if those analysts were able to easily switch contexts, following their partner’s stream of consciousness in a free association of ideas and hypotheses?
This is the opportunity that LLMs present in the analytics space — the promise that anyone can conduct exploratory analysis with the benefit of a technical analyst by their side.
Let’s take a look at how this might manifest in practice. The following case study and demos illustrate how a decision maker with domain expertise might effectively pair with an AI analyst who can query and visualize the data. We’ll compare the data exploration experiences of ChatGPT’s 4o model against a manual analysis using Tableau, which will also serve as an error check against potential hallucinations.
A note on data privacy: The video demos linked in the following section use purely synthetic data sets, intended to mimic realistic business patterns. To see general notes on privacy and security for AI Analysts, see Data privacy.
Case Study: Ecommerce Analytics
Picture this: you’re the busy executive of an e-commerce apparel website. You have your Exec Summary dashboard of pre-defined, high-level KPIs, but one morning you take a look and you see something concerning: month-over-month marketing revenue is down 45% but it’s not immediately clear why.
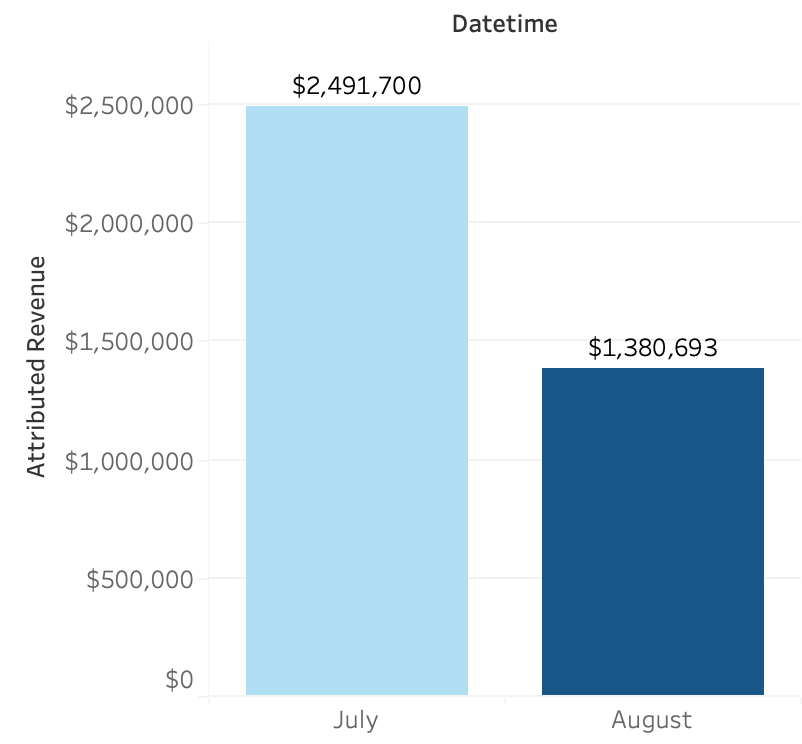
Your mind pulls you in a few different directions at once: What’s contributing to the revenue dip? Is it isolated to certain channels? Is the issue limited to certain message types?
But more than that, what can we do about it? What’s been working well recently? What’s not working? What seasonal trends do we see this time of year? How can we capitalize on those?
In order to answer these types of open-ended questions, you’ll need to conduct a moderately complex, multivariate analysis. This is the exact type of exercise an AI Analyst can help with.
Diagnostic Analysis
Let’s start by taking a closer look at that troubling dip in month-over-month revenue.
In our example, we’re looking at a huge decrease to overall revenue attributed to marketing activities. As an analyst, there are 2 parallel trains of thought to begin diagnosing the root cause:
Break overall revenue down into multiple input metrics:
- Total message sends: Did we send fewer messages?
- Open rate: Were people opening these messages? I.e., was there an issue with the message subjects?
- Click-through rate: Were recipients less likely to click through on a message? I.e., was there an issue with message content?
- Conversion rate: Were recipients less likely to purchase once clicking through? I.e., was there an issue with the landing experience?
Isolate these trends across different categorical dimensions
- Channels: Was this issue observed across all channels, or only a subset?
- Message types: Was this issue observed across all message types?
In this case, within a few prompts the LLM is able to identify a big difference in the type of messaging sent during these 2 time periods — namely the 50% sale that was run in July and not in August.
Ad Hoc Data Visualization
So the dip makes more sense now, but we can’t run a 50% off sale every month. What else can we do to make sure we’re making the most of our marketing touch points? Let’s take a look at our top-performing campaigns and see if there’s anything besides sales promotions that cracks the top 10.
Data visualization tools support a point-and-click interface to build data visualizations. Today, tools like ChatGPT and Julius AI can already faithfully replicate an iterative data visualization workflow.
These tools leverage python libraries to create and render both static data visualizations, as well as interactive charts, directly within that chat UI. The ability to tweak and iterate on these visualizations through natural language is quite smooth. With the introduction of code modules, image rendering, and interactive chart elements, the chat interface comes close to resembling the familiar “notebook” format popularized by jupyter notebooks.
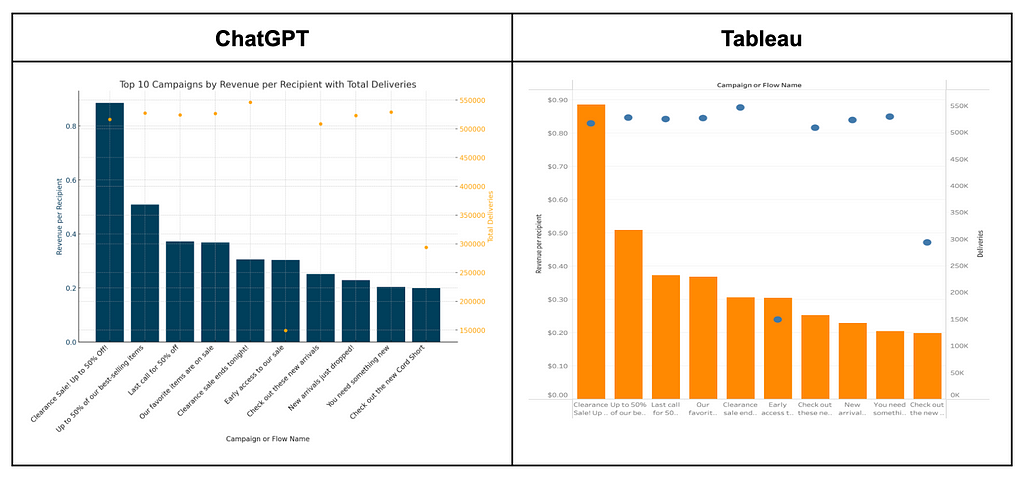
Within a few prompts you can often dial in a data visualization just as quickly as if you were a power user of a data visualization tool like Tableau. In this case, you didn’t even need to consult the help docs to learn how Tableau’s Dual Axis Charting works.
Here, we can see that “New Arrivals” messages deliver a strong revenue per recipient, even at large send volumes:
Seasonality & Forecasting
So “New Arrivals” seem to be resonating, but what types of new arrivals should we make sure to drop next month? We’re heading into September, and we want to understand how customer buying patterns change during this time of year. What product categories do we expect to increase? To decrease?
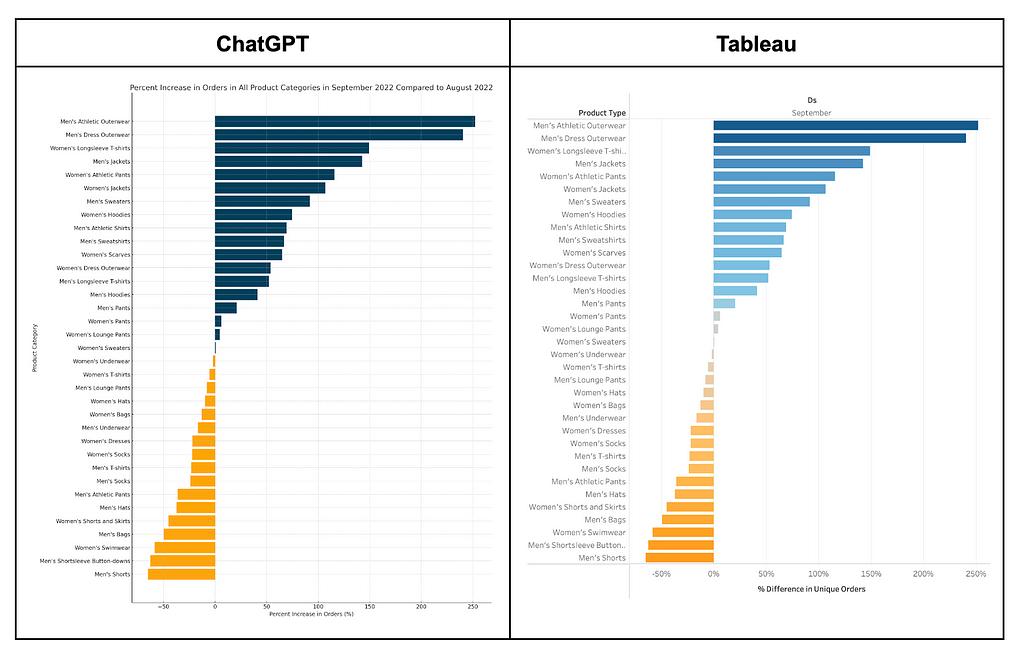
Again, within a few prompts we’ve got a clear, accurate data visualization, and we didn’t even need to figure out how to use Tableau’s tricky Quick Table Calculations feature!
Market Basket Analysis
Now that we know which product categories are likely to increase next month, we might want to dial in some of our cross-sell recommendations. So, if Men’s Athletic Outerwear is going to see the biggest increase, how can we see what other categories are most commonly purchased with those items?
This is commonly called “market basket analysis” and the data transformations needed to conduct it are a little complex. In fact, doing a market basket analysis in excel is effectively impossible without the use of clunky add-ons. But with LLMs, all you need to do is pause for a moment and ask your question clearly:
“Hey GPT, for orders that contained an item from men’s athletic outerwear, what product types are most often purchased by the same customer in the same cart?”
How will business processes evolve to incorporate AI?
The demos above illustrate some examples of how LLMs might support better data-driven decision-making at scale. Major players have identified this opportunity and the ecosystem is rapidly evolving to incorporate LLMs into analytics workflows. Consider the following:
- When OpenAI released its “code interpreter” beta last year, it quickly renamed the feature to “Advanced Data Analysis” to align with how early adopters were using the feature.
- With GPT4o, OpenAI now supports rendering interactive charts, including the ability to change color coding, render tooltips on hover, sort / filter charts, and select chart columns and apply calculations.
- Tools like Julius.ai are emerging to specifically address key analytics use-cases, providing access to multiple models where appropriate. Julius provides access to models from both OpenAI and Anthropic.
- Providers are making it easier and easier to share data, expanding from static file uploads to Google Sheet connectors and more advanced API options.
- Tools like Voiceflow are emerging to support AI app development with a focus on retrieval augmented generation (RAG) use-cases (like data analysis). This is making it easier and easier for 3rd party developers to connect custom data sets to a variety of LLMs across providers.
With this in mind, let’s take a moment and imagine how BI analytics might evolve over the next 12–24 months. Here are some predictions:
Human analysts will continue to be critical in asking the right questions, interpreting ambiguous data, and iteratively refining hypotheses.
The major advantages of LLMs for analytics are its ability to…
- Convert natural language to code (Python, R, SQL)
- Intelligently clean data sets
- Visualize data effectively
Domain expertise is still required to interpret trends and iterate on hypotheses. Humans will do less querying and data viz construction, but continue to be essential in advancing exploratory analyses.
Skills in this area will become more important than technical skills in querying and data visualization. Decision makers who develop strong data literacy and critical thinking skills will vastly expand their ability to explore and understand complex systems with the aid of LLMs.
The biggest hurdle to enterprise adoption of AI Analysts at scale will be concerns around data privacy. These concerns will be successfully addressed in a variety of ways.
Despite robust privacy policies from the major LLM providers, data sharing will be a major source of anxiety. However, there are a number of ways to address this that are already being explored. LLM providers have begun experimenting with dedicated instances with enhanced privacy and security measures. Other solutions may include encryption / decryption when sharing data via an API, as well as sharing dummy data and using an LLM only for code generation.
Expect to see increased vertical alignment between LLM providers and cloud database providers (Gemini / BigQuery, OpenAI / Microsoft Azure, Amazon Olympus / AWS) to help address this issue.
Once data privacy and security concerns are addressed, early adopters will initially encounter challenges with speed, error handling, and minor hallucinations. These challenges will be overcome through the combined efforts of LLM providers, organizations, and individuals.
The major LLM providers are improving speed and accuracy at a high velocity. Expect this to continue, with analytics use-cases benefitting from specialization and selective context (memory, tool access, and narrow instructions).
Organizations will be motivated to invest in LLM-based analytics as deeper integrations emerge and costs drop.
Individuals will be able to learn effective prompt-writing much more quickly than SQL, Python / R, and data viz tools.
BI teams will focus less on servicing analytics requests, and more on building and supporting the underlying data architecture. Thorough data set documentation will become critical for all BI data sets going forward.
Once LLMs reach a certain level of organizational trust, analytics will be largely self-serve.
The “data dictionary” has long been a secondary concern for BI organizations, but going forward these will become table stakes for any organization hoping to leverage AI Analysts.
With the ability of LLMs to perform complex data transformations on the fly, fewer aggregate tables will be necessary. Those used by LLMs will be closer to a “silver” level than a “gold” level in medallion architecture.
A clear example of this is the market basket analysis examined later in this article. Traditional market basket analysis involves creating a net new data set via complex transformations. With an LLM, a “raw” table can be used and those transformations can be executed “just in time,” only on products or categories the end user is interested in.
The counterpoint here is that raw data sets are larger and will therefore incur higher costs, as they require a higher volume of tokens to be sent as input. This is an important tradeoff and hinges on the cost model for leverage LLM APIs.
Voice will become the dominant input for LLM interactions, including for analytics use-cases.
Voice technology has never really taken off via voice assistants like Siri and Alexa. However, with the release GPT 4o and it’s capabilities in real-time conversational speech, expect voice interaction to tip into mainstream adoption.
Interactive visualizations will become the dominant output for analytics use-cases.
It’s well-established that human brains are much more efficient and processing visual information than any other medium. Expect the user-experience for exploratory analysis to follow a voice / viz pattern, with a human asking questions and an AI analyst visualizing information wherever possible.
The most efficient LLM analytics systems will leverage multiple models from a single provider, intelligently using the least sophisticated model necessary for a given task, thereby saving on token costs.
With LLM providers continually releasing new models, a token-based pricing structure has emerged that applies multipliers based on the sophistication of the model used. I.e., a response from GPT4o will cost more than a response from GPT3.5. In order to reduce costs, AI-based applications will need to optimize their usage across different models. Due to the costs associated with sending large volumes of data, expect organizations to limit data sharing to a single provider.
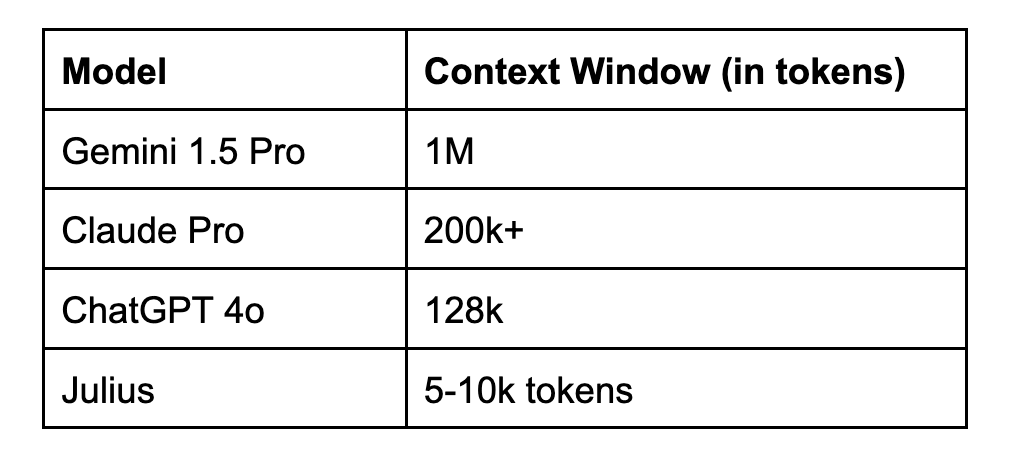
Expanded context windows will allow users to conduct long-form analyses, sustaining context across days or weeks as new data becomes available and hypotheses shift
The size of an LLM’s context window determines how much information can be passed as an input. This can be especially high for a RAG (retrieval augmented generation) use-case like data analysis. Larger context windows allow for greater information to be passed, and for longer conversational exchanges to occur.
Right now, Google’s Gemini 1.5 model has the largest available context window of any LLM:
Setting up an AI analyst in 2024
If you’re interested in experimenting with an LLM for analytics use-cases, some initial configuration will be necessary. Read the following section for some tips on how to get the best performance possible and avoid some common pitfalls
Initial configuration
Data sets and data dictionary
First and foremost, you’ll need to provide the LLM with access to your data. At the risk of stating the obvious, the data sets you share need to have the data necessary to answer the questions you want to ask the LLM. More than that, there needs to be a clear, well-written data dictionary for all fields within the data set so that the LLM has a strong understanding of each metric and dimension. The data sets and data dictionaries used in the above demos can be viewed here:
Data connections
There are a variety of ways to share data with an LLM, depending on which model you’re using:
- File upload: The easiest way to do this today is to upload a static file within the UI of the web app. ChatGPT, Claude, and Julius.ai all support file upload within the web UI.
- Google Sheets: ChatGPT and Julius.ai support data imports from Google sheets natively.
- API: For more advanced use-cases, or AI-driven apps, you can share data sets via API. Consult your provider’s developer docs for more details.
Data privacy
Right now, unless you’re installing an open-source LLM like Meta’s Llama and running it locally, you must send data to the LLM via one of the methods above. This introduces some clear security and data privacy concerns.
If you want to analyze data sets that include PII (personally identifiable information) such as customer_ids, consider whether an aggregated data set might be sufficient for your needs. If you determine that a pre-aggregated data set won’t be sufficient, make sure to encrypt these fields before uploading so that no PII is exposed.
Also consider whether you are sharing any confidential information about your organization. In the event of a data leak, you don’t want to be responsible for having exposed sensitive information to a 3rd party.
You can review the privacy policies of the models mentioned in the article here:
- OpenAI: https://openai.com/policies/privacy-policy/
- Anthropic: https://support.anthropic.com/en/collections/4078534-privacy-legal
- Julius: https://julius.ai/docs/privacy-policy
Custom instructions
If you’re creating a custom GPT, you can supply the GPT with a set of custom instructions to guide its behavior. For other models that don’t support custom instances like Claude or Gemini, you can start your conversation with a long-form prompt that contains this guidance. The custom instructions supplied to the customGPT used in the demo above can be found here: Ecommerce BI Analyst Custom Instructions
In my experience, the following guidance is useful to include for an AI analyst:
- Identity: Inform the LLM of its identity. Example: “You are an expert Business Intelligence Analyst who will be fielding questions about an ecommerce apparel retailer.”
- Data sets: If you plan to use the same data sets consistently, it’s worth providing the LLM with some additional content on the nature of the data set. This supplements the data dictionary and clarifies the LLMs understanding of the data. Example: “This data set contains data on all purchases recorded for the ecommerce apparel retailer over the course of 2 months — July and August 2022. Each row represents one purchase event and contains data on the product purchased, as well as the customer who made the purchase.”
- Data visualization best practices: The charts rendered by LLMs can require some fine-tuning for human legibility. This will probably improve over time, but for now I’ve found it useful to “hardcode” some data visualization best practices into the custom instructions. Example: “Always ensure that axis labels are legible through some combination of the following: Reducing the number of labels shown (i.e., every other label, or every 3rd label is shown, etc.), reformatting the orientation of the labels, or adding additional padding.”
- Calculated fields: In order to eliminate any ambiguity in the calculation of derived metrics, it’s useful to supply the LLM with explicit guidance re: how to calculate them. Example: “Click-through Rate” = the sum of “Unique Clicks” divided by the sum of “Unique Opens”
- General Guidance: As you experiment with the LLM, take note of any undesirable or unexpected behavior and consider adding explicit guidance to the custom instructions. Example: “When a question contains the words “show me”, always attempt to answer with a data visualization.”
It is sometimes necessary to “prime” the instance of your GPT in order to ensure it has read and understood these instructions. In this case, simply ask it some questions regarding the contents of your custom instructions to confirm it has grasped them.
Things to watch out for
Processing times: GPT may sometimes take quite a while to generate a response. The demos above were edited for length and clarity. Depending on the overall load the system is handling, you may need to be patient as the LLM analyzes the data.
Error messages: As you first start to experiment with using LLMs for analysis, you may encounter frequent error messages as you dial in your custom instructions and refine your prompts. Often an LLM will retry automatically when it encounters an error and successfully course-correct. Other times, it may simply fail. When this occurs, you may need to examine the code that’s being employed and do your own troubleshooting.
Trust, but verify: For more complex analyses, spot check the model’s output to confirm it’s on the right track. Until LLMs evolve a bit more, you may want to run the python code locally in a Jupyter notebook to understand the model’s approach.
Hallucinations: I’ve found hallucinations to be far less likely in conversations referencing a knowledge base (data set) that has an objective truth. However, occasionally I’ve observed LLMs misstating the definition of a computed metric, or otherwise misspeaking about the nature of elements of the analysis.
Conclusion
LLMs are poised to profoundly disrupt the analytics space by automating querying and visualization workflows. Over the next 2–3 years, organizations that incorporate LLMs into their analytics workflows and re-orient BI teams around supporting this new technology will have a major leg up in strategic decision-making. The potential value here is enough to surmount initial challenges around data privacy and user experience.
In the words of the immortal Al Swearengen, “Everything changes; don’t be afraid.”
Unless otherwise noted, all images are by the author
How LLMs Will Democratize Exploratory Data Analysis was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How LLMs Will Democratize Exploratory Data Analysis
Go Here to Read this Fast! How LLMs Will Democratize Exploratory Data Analysis