DATA SCIENCE, SQL, ETL
A comprehensive guide to creating pivot tables in SQL for enhanced data analysis

Preface
Structured Query Language (SQL) is an essential tool for data professionals such as data scientists and data analysts as it allows them to retrieve, manipulate, and analyze large datasets efficiently and effectively. It is a widely used tool in the industry, making it an important skill to have. In this article, I want to share how to create Pivot tables in SQL. This article follows up on my last article “Pandas!!! What I’ve Learned after my 1st On-site Technical Interview”, where I shared my learnings on Pandas.
Did you know that SQL can be used to analyze data?
In SQL, a Pivot table is a technique used to transform data from rows to columns.
Joan Casteel’s Oracle 12c: SQL book mentions that “a pivot table is a presentation of multidimensional data.” With a pivot table, a user can view different aggregations of different data dimensions. It is a powerful tool for data analysis, as it allows users to aggregate, summarize, and present data in a more intuitive and easy-to-read format.
For instance, an owner of an ice cream shop may want to analyze which flavor of ice cream has sold the best in the past week. A pivot table would be useful in this case, with two dimensions of data — ice cream flavor and day of the week. Revenue can be summed up as the aggregation for the analysis.
The ice cream shop owner can easily use a pivot table to compare sales by ice cream flavor and day of the week. The pivot table will transform the data, making it easier to spot patterns and trends. With this information, the owner can make data-driven decisions, such as increasing the supply of the most popular ice cream flavor or adjusting the prices based on demand.
Overall, pivot tables are an excellent tool for data analysis, allowing users to summarize and present multidimensional data in a more intuitive and meaningful way. They are widely used in industries such as finance, retail, and healthcare, where there is a need to analyze large amounts of complex data.

Overview
This article will be based on the analytic function in Oracle, typically the “PIVOT” function. It is organized to provide a comprehensive view of utilizing pivot tables in SQL in different situations. We will not only go through the most naive way to create a pivot table but also the easiest and most common way to do the job with the PIVOT function. Last but not least, I will also talk about some of the limitations of the PIVOT function.
FYI:
- I will use Oracle 11g, but the functions are the same in the newer Oracle 12c and above.
- The demonstration dataset is Microsoft’s Northwind dataset. The sales data for Northwind Traders, a fictitious specialty foods export/import company. The database is free of use and widely distributed for learning and demonstration purposes. Be sure to set up the database environment beforehand! I also attached the Northwind schema below:
REGION (RegionID, RDescription)
TERRITORIES ( TerritoryID, TDescription, RegionID@)
CATEGORIES (CategoryID, CategoryName, Description)
SUPPLIERS (SupplierID, CompanyName, ContactName, ContactTitle, Address, City, Region, PostalCode, Country, Phone)
CUSTOMERS (CustomerID, CompanyName, ContactName, ContactTitle, Address, City, Region, PostalCode, Country, Phone)
SHIPPERS (ShipperID, CompanyName, Phone)
PRODUCTS (ProductID, ProductName, SupplierID@, CategoryID@, QuantityPerUnit, UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued)
EMPLOYEES (EmployeeID, LastName, FirstName, Title, BirthDate, HireDate, Address, City, RegionID@, PostalCode, Country, HomePhone, Extension, ReportsTo@)
EMPLOYEETERRITORIES (EmployeeID@, TerritoryID@)
ORDERS (OrderID, CustomerID@, EmployeeID@, TerritoryID@, OrderDate, RequiredDate, ShippedDate, ShipVia@, Freight, ShipName, ShipAddress, ShipCity, ShipRegion, ShipPostalCode, ShipCountry)
ORDERDETAILS (OrderID@, ProductID@, UnitPrice, Quantity, Discount)
- If you are unfamiliar with SQL*Plus, check on Oracle’s SQL*Plus Quick Start before starting.
Without further ado, let’s get started!
Pivot Tables with “DECODE”

The crudest way to pivot a table is to utilize the function: DECODE(). DECODE() function is like an if else statement. It compares the input with each value and produces an output.
DECODE(input, value1, return1, value2, return2, …, default)
- input/value: “input” is compared with all the “values”.
- return: if input = value, then “return” is the output.
- default (optional): if input != all of the values, then “default” is the output.
When we know how DECODE() works, it is time to make our first pivot table.
1st Version: Pivot table without total column and row
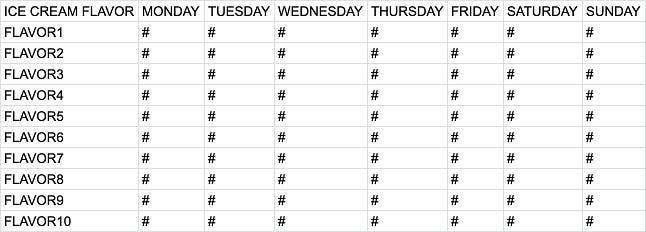
With DECODE(), we can map out a pseudocode of a pivot table for the ice cream shop owner. When the “day of the week” matches each weekday, DECODE() returns the day’s revenue; if it does not match, 0 is returned instead.
SELECT ice cream flavor,
SUM(DECODE(day of the week, 'Monday', revenue, 0)) AS MONDAY, SUM(DECODE(day of the week, 'Tuesday', revenue, 0)) AS TUESDAY,
SUM(DECODE(day of the week, 'Wednesday', revenue, 0)) AS WEDNESDAY,
SUM(DECODE(day of the week, 'Thursday', revenue, 0)) AS THURSDAY,
SUM(DECODE(day of the week, 'Friday', revenue, 0)) AS FRIDAY,
SUM(DECODE(day of the week, 'Saturday', revenue, 0)) AS SATURDAY,
SUM(DECODE(day of the week, 'Sunday', revenue, 0)) AS SUNDAY
FROM ice cream shop dataset
WHERE date between last Monday and last Sunday;
2nd Version: Pivot table with total column and row
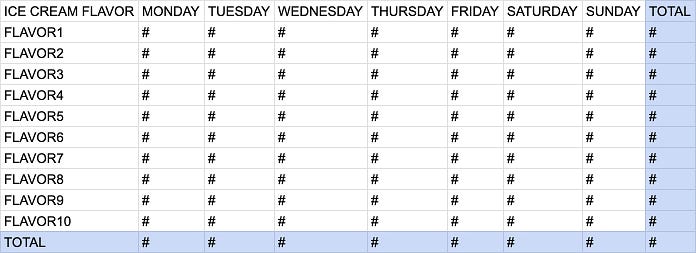
Great job! Now the ice cream shop owner wants to know more about what happened with last week’s sales. You could upgrade your pivot table by adding a total column and total row.
This could be accomplished using the GROUPING SETS Expression in a GROUP BY statement. A GROUPING SETS Expression defines criteria for multiple GROUP BY aggregations.
GROUPING SETS (attribute1, …, ())
- attribute: a single element or a list of elements to GROUP BY
- (): an empty group, which will become the pivot table’s TOTAL row
SELECT NVL(ice cream flavor, 'TOTAL') "ICE CREAM FLAVOR",
SUM(DECODE(day of the week, 'Monday', revenue, 0)) AS MONDAY, SUM(DECODE(day of the week, 'Tuesday', revenue, 0)) AS TUESDAY,
SUM(DECODE(day of the week, 'Wednesday', revenue, 0)) AS WEDNESDAY,
SUM(DECODE(day of the week, 'Thursday', revenue, 0)) AS THURSDAY,
SUM(DECODE(day of the week, 'Friday', revenue, 0)) AS FRIDAY,
SUM(DECODE(day of the week, 'Saturday', revenue, 0)) AS SATURDAY,
SUM(DECODE(day of the week, 'Sunday', revenue, 0)) AS SUNDAY,
SUM(revenue) AS TOTAL
FROM ice cream shop dataset
WHERE date between last Monday and last Sunday
GROUP BY GROUPING SETS (ice cream flavor, ());
Note: NVL() replaces the null row created by () with ‘TOTAL.’ If you are unfamiliar with NVL(), it is simply a function to replace null values.
Another way of calculating the TOTAL column is to add all the revenue from MONDAY to SUNDAY:
SUM(DECODE(day of the week, 'Monday', revenue, 0))
+ SUM(DECODE(day of the week, 'Tuesday', revenue, 0))
+ SUM(DECODE(day of the week, 'Wednesday', revenue, 0))
+ SUM(DECODE(day of the week, 'Thursday', revenue, 0))
+ SUM(DECODE(day of the week, 'Friday', revenue, 0))
+ SUM(DECODE(day of the week, 'Saturday', revenue, 0))
+ SUM(DECODE(day of the week, 'Sunday', revenue, 0)) AS TOTAL
3rd Version: Pivot table with total column and row and other totals
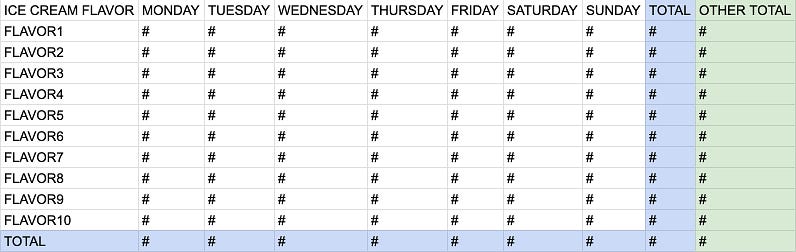
Say that the ice cream owner wanted one more column on the pivot table you provided: the total number of purchases of each flavor of ice cream. No problem! You can add another “TOTAL” column with the same concept!
SELECT NVL(ice cream flavor, 'TOTAL') "ICE CREAM FLAVOR",
SUM(DECODE(day of the week, 'Monday', revenue, 0)) AS MONDAY, SUM(DECODE(day of the week, 'Tuesday', revenue, 0)) AS TUESDAY,
SUM(DECODE(day of the week, 'Wednesday', revenue, 0)) AS WEDNESDAY,
SUM(DECODE(day of the week, 'Thursday', revenue, 0)) AS THURSDAY,
SUM(DECODE(day of the week, 'Friday', revenue, 0)) AS FRIDAY,
SUM(DECODE(day of the week, 'Saturday', revenue, 0)) AS SATURDAY,
SUM(DECODE(day of the week, 'Sunday', revenue, 0)) AS SUNDAY,
SUM(revenue) AS TOTAL,
SUM(purchase ID) "OTHER TOTAL"
FROM ice cream shop dataset
WHERE date between last Monday and last Sunday
GROUP BY GROUPING SETS (ice cream flavor, ());
Now that you know how to do a pivot table with DECODE(), let’s try three exercises with the Northwind dataset!
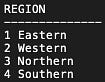
Q1. Let’s say we want to find out how many employees in each of their origin countries serve in each region.
To break up this question, first, we can query all distinct regions in the REGION table. Also, check what countries the employees are from.
SELECT DISTINCT REGIONID||' '||RDescription AS REGION
FROM REGION
ORDER BY 1;
SELECT DISTINCT Country
FROM EMPLOYEES
ORDER BY 1;

We will have to make a 2 * 4 pivot table for this question.
Next, we can make a pivot table using DECODE(). A sample answer and output are outlined below:

SELECT NVL(Country, 'TOTAL') AS COUNTRY,
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '1 eastern', 1, 0)) "1 EASTERN",
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '2 western', 1, 0)) "2 WESTERN",
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '3 northern', 1, 0)) "3 NORTHERN",
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '4 southern', 1, 0)) "4 SOUTHERN",
SUM(EmployeeID) AS TOTAL
FROM EMPLOYEES
JOIN REGION USING (REGIONID)
GROUP BY GROUPING SETS (Country, ());

--Q1
SELECT Country,
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '1 eastern', 1, 0)) "1 EASTERN",
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '2 western', 1, 0)) "2 WESTERN",
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '3 northern', 1, 0)) "3 NORTHERN",
SUM(DECODE(LOWER(REGIONID||' '||RDescription), '4 southern', 1, 0)) "4 SOUTHERN",
SUM() AS TOTAL
FROM EMPLOYEES
JOIN REGION USING (REGIONID)
GROUP BY Country;
Q2. For each month in 2010, show the revenue of orders processed by each employee. Also, round to the nearest dollar and display the total revenue made and the total number of orders.
--Q2
COLUMN EMPLOYEE FORMAT A18
SELECT NVL(EmployeeID||' '||FirstName||' '||LastName, 'TOTAL') AS EMPLOYEE,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 1, (UnitPrice * Quantity - Discount), 0)), '$990') AS JAN,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 2, (UnitPrice * Quantity - Discount), 0)), '$990') AS FEB,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 3, (UnitPrice * Quantity - Discount), 0)), '$990') AS MAR,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 4, (UnitPrice * Quantity - Discount), 0)), '$990') AS APR,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 5, (UnitPrice * Quantity - Discount), 0)), '$990') AS MAY,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 6, (UnitPrice * Quantity - Discount), 0)), '$990') AS JUN,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 7, (UnitPrice * Quantity - Discount), 0)), '$99,990') AS JUL,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 8, (UnitPrice * Quantity - Discount), 0)), '$99,990') AS AUG,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 9, (UnitPrice * Quantity - Discount), 0)), '$99,990') AS SEP,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 10, (UnitPrice * Quantity - Discount), 0)), '$99,990') AS OCT,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 11, (UnitPrice * Quantity - Discount), 0)), '$99,990') AS NOV,
TO_CHAR(SUM(DECODE(EXTRACT(MONTH FROM OrderDate), 12, (UnitPrice * Quantity - Discount), 0)), '$99,990') AS DEC,
TO_CHAR(SUM((UnitPrice * Quantity - Discount)), '$999,990') AS TOTAL
FROM ORDERS
JOIN ORDERDETAILS USING (OrderID)
JOIN EMPLOYEES USING (EmployeeID)
WHERE EXTRACT(YEAR FROM OrderDate) = 2010
GROUP BY GROUPING SETS (EmployeeID||' '||FirstName||' '||LastName, ())
ORDER BY 1;
Note: Notice the FORMAT command and TO_CHAR() function are for formatting purposes. If you want to learn more, please check out the Format Models and Formatting SQL*Plus Reports section on Oracle’s website.
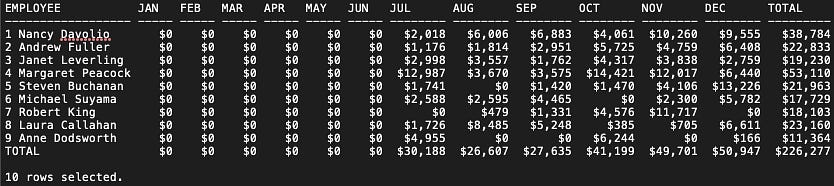
Pivot Tables with “PIVOT”

Now that you know how to make a pivot table with DECODE(), we can move on to the PIVOT() clause introduced to Oracle in its 11g version.
SELECT *
FROM ( query)
PIVOT (aggr FOR column IN (value1, value2, …)
);
- aggr: function such as SUM, COUNT, MIN, MAX, or AVG
- value: A list of values for column to pivot into headings in the cross-tabulation query results
Let’s get back to the ice cream shop example. Here is how we can make it with the PIVOT() clause:
1st Version: Pivot table without total column and row
SELECT *
FROM (
SELECT day of the week, ice cream flavor, revenue
FROM ice cream shop dataset
WHERE date between last Monday and last Sunday
)
PIVOT (
SUM(revenue)
FOR day of the week IN ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday')
);
2nd Version: Pivot table with total column and row
If you want to add a total column to your pivot table, doing it with the NVL() function is a great way.
SELECT *
FROM (
SELECT NVL(ice cream flavor, 'TOTAL') AS ice cream flavor,
NVL(day of the week, -1) AS DOW,
SUM(revenue) AS REV
FROM ice cream shop dataset
WHERE date between last Monday and last Sunday
GROUP BY CUBE (ice cream flavor, day of the week)
)
PIVOT (
SUM(REV)
FOR DOW IN ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday', -1 AS TOTAL)
);
3rd Version: Pivot table with total column and row and other totals
When other totals come into the scene, there is only one way to solve the problem. That is by using the JOIN() clause:
SELECT ice cream flavor, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday, TOTAL, OTHER TOTAL
FROM (
SELECT NVL(ice cream flavor, 'TOTAL') AS ice cream flavor,
NVL(day of the week, -1) AS DOW,
SUM(revenue) AS REV
FROM ice cream shop dataset
WHERE date between last Monday and last Sunday
GROUP BY CUBE (ice cream flavor, day of the week)
)
PIVOT (
SUM(REV)
FOR DOW IN ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday', -1 AS TOTAL)
)
JOIN (
SELECT NVL(ice cream flavor, 'TOTAL') AS ice cream flavor,
SUM(purchase ID) "OTHER TOTAL"
FROM ice cream shop dataset
WHERE date between last Monday and last Sunday
GROUP BY ROLLUP (ice cream flavor)
) USING (ice cream flavor);
Note: In the pseudocode above, We utilize the CUBE and ROLLUP Extension in GROUP BY. A small explanation will do the job.
- CUBE(A, B, C): (A, B, C), (A, B), (A, C), (B, C), (A), (B), (C), ()
- ROLLUP(A, B, C): (A, B, C), (A, B), (A), ()
Once we know how the PIVOT() clause work, can you practice it with the Northwind dataset we have in part 1?
Q1. Let’s say we want to find out how many employees in each of their origin countries serve in each region.
--Q1
--Try it out!
Q2. For each month in 2010, show the revenue of orders processed by each employee. Also, round to the nearest dollar and display the total revenue made and the total number of orders.
--Q2
--Try it out!
Epilogue
In this guide, we’ve explored the powerful capabilities of pivot tables in SQL, focusing on both the DECODE() and PIVOT() functions. We began with an introduction to pivot tables and their significance in transforming rows into columns for enhanced data analysis. We then walked through the process of creating pivot tables using DECODE() and examined the more streamlined PIVOT() function introduced in Oracle 11g, which simplifies pivot table creation. By applying these techniques, we’ve demonstrated how to efficiently analyze multidimensional data with practical examples, such as the ice cream shop dataset.

Recap and Takeaways
- Pivot tables with DECODE(): A fundamental approach using the DECODE() function to manually pivot data.
- Pivot tables with PIVOT(): Utilizing the PIVOT() function for a more efficient and readable pivot table creation.
Feel free to share your answers in the comments. I love to learn about data and reflect on (write about) what I’ve learned in practical applications. If you enjoyed this article, please give it a clap to show your support. You can contact me via LinkedIn and Twitter if you have more to discuss. Also, feel free to follow me on Medium for more data science articles to come!
Come play along in the data science playground!
How to Pivot Tables in SQL was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Pivot Tables in SQL