Implement the PCA algorithm from scratch with Python

Plenty of well-established Python packages (like scikit-learn) implement Machine Learning algorithms such as the Principal Component Analysis (PCA) algorithm. So, why bother learning how the algorithms work under the hood?
A deep understanding of the underlying mathematical concepts is crucial for making better decisions based on the algorithm’s output and avoiding treating the algorithm as a “black box”.
In this article, I show the intuition of the inner workings of the PCA algorithm, covering key concepts such as Dimensionality Reduction, eigenvectors, and eigenvalues, then we’ll implement a Python class to encapsulate these concepts and perform PCA analysis on a dataset.
Whether you are a machine learning beginner trying to build a solid understanding of the concepts or a practitioner interested in creating custom machine learning applications and need to understand how the algorithms work under the hood, that article is for you.
Table of Contents
1. Dimensionality Reduction
2. How Does Principal Component Analysis Work?
3. Implementation in Python
4. Evaluation and Interpretation
5. Conclusions and Next Steps
1. Dimensionality Reduction
Many real problems in machine learning involve datasets with thousands or even millions of features. Training such datasets can be computationally demanding, and interpreting the resulting solutions can be even more challenging.
As the number of features increases, the data points become more sparse, and distance metrics become less informative, since the distances between points are less pronounced making it difficult to distinguish what are close and distant points. That is known as the curse of dimensionality.
The more sparse data makes models harder to train and more prone to overfitting capturing noise rather than the underlying patterns. This leads to poor generalization to new, unseen data.
Dimensionality reduction is used in data science and machine learning to reduce the number of variables or features in a dataset while retaining as much of the original information as possible. This technique is useful for simplifying complex datasets, improving computational efficiency, and helping with data visualization.
2. How Does Principal Component Analysis Work?
One of the most used techniques to mitigate the curse of dimensionality is Principal Component Analysis (PCA). The PCA reduces the number of features in a dataset while keeping most of the useful information by finding the axes that account for the largest variance in the dataset. Those axes are called the principal components.
Since PCA aims to find a low-dimensional representation of a dataset while keeping a great share of the variance instead of performing predictions, It is considered an unsupervised learning algorithm.
But why does keeping the variance mean keeping important information?
Imagine you are analyzing a dataset about crimes in a city. The data have numerous features including “crime against person – with injuries” and “crime against person — without injuries”. Certainly, the places with high rates of the first example must also have high rates of the second example.
In other words, the two features of the example are very correlated, so it is possible to reduce the dimensions of that dataset by diminishing the redundancies in the data (the presence or absence of injuries in the victim).
The PCA algorithm is nothing more than a sophisticated way of doing that.
Now, let’s break down how the PCA algorithm works under the hood in the following steps:
Step 1: Centering the data
PCA is affected by the scale of the data, so the first thing to do is to subtract the mean of each feature of the dataset, thus ensuring that all the features have a mean equal to 0.
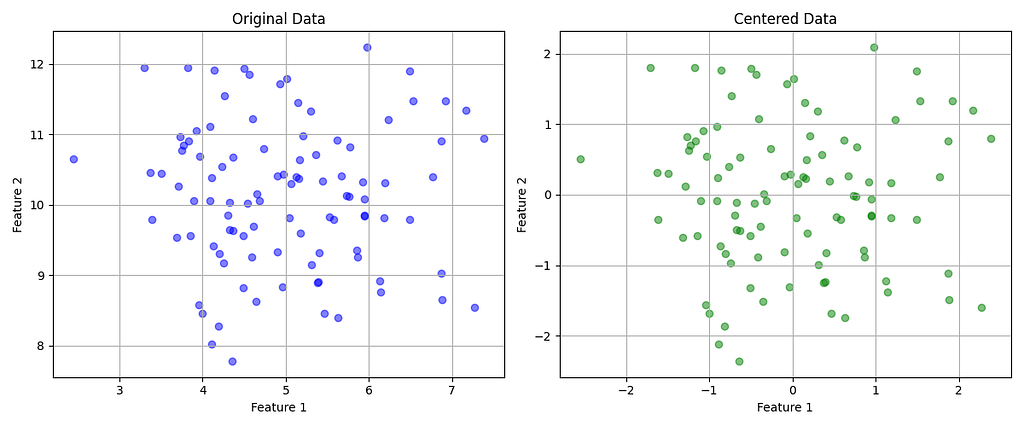
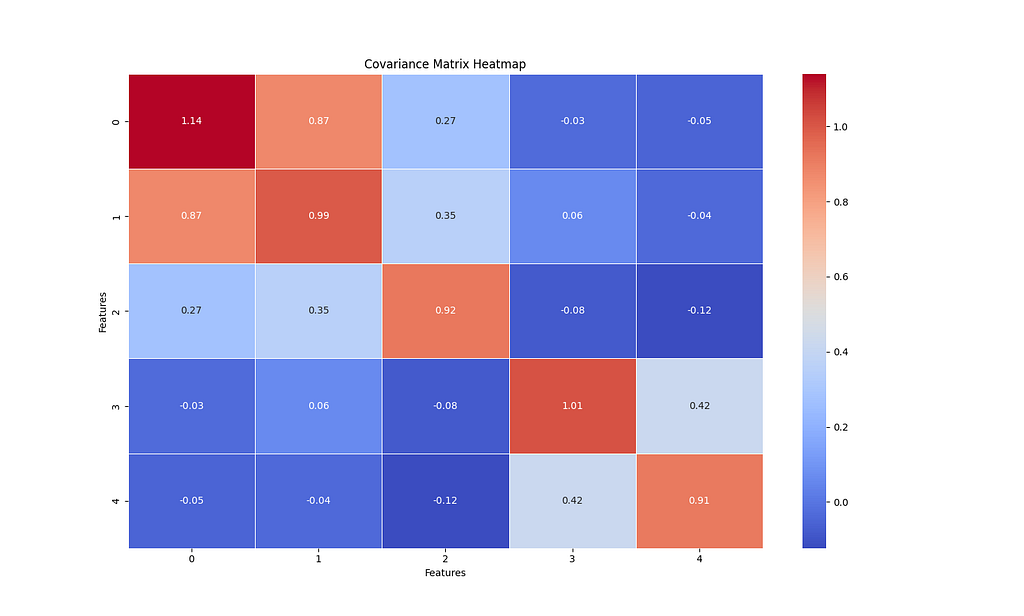
Step 2: Calculating the covariance matrix
Now, we have to calculate the covariance matrix to capture how each pair of features in the data varies together. If the dataset has n features, the resulting covariance matrix will have n x n shape.
In the image below, features more correlated have colors closer to red. Of course, each feature will be highly correlated with itself.
Step 3: Eigenvalue Decomposition
Next, we have to perform the eigenvalue decomposition of the covariance matrix. In case you don’t remember, given the covariance matrix Σ (a square matrix), eigenvalue decomposition is the process of finding a set of scalars (eigenvalues) and vectors (eigenvectors) such that:

Where:
- Σ is the n×n covariance matrix.
- v is a non-zero vector called the eigenvector.
- λ is a scalar called the eigenvalue associated with the eigenvector v.
Eigenvectors indicate the directions of maximum variance in the data (the principal components), while eigenvalues quantify the variance captured by each principal component.
If a matrix A can be decomposed into eigenvalues and eigenvectors, it can be represented as:
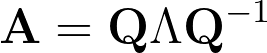
Where:
- Q is a matrix whose columns are the eigenvectors of A.
- Λ is a diagonal matrix whose diagonal elements are the eigenvalues of A.
That way, we can use the same steps to find the eigenvalues and eigenvectors of the covariance matrix.

In the image above, we can see that the first eigenvector points to the direction with the most variance of the data, and the second eigenvector points to the direction with the second most variance.
Step 4: Selecting the Principal Components
As said earlier, the eigenvalues quantify the data’s variance in the direction of its corresponding eigenvector. Thus, we sort the eigenvalues in descending order and keep only the top n required principal components.
The image below illustrates the proportion of variance captured by each principal component in a PCA with two dimensions.
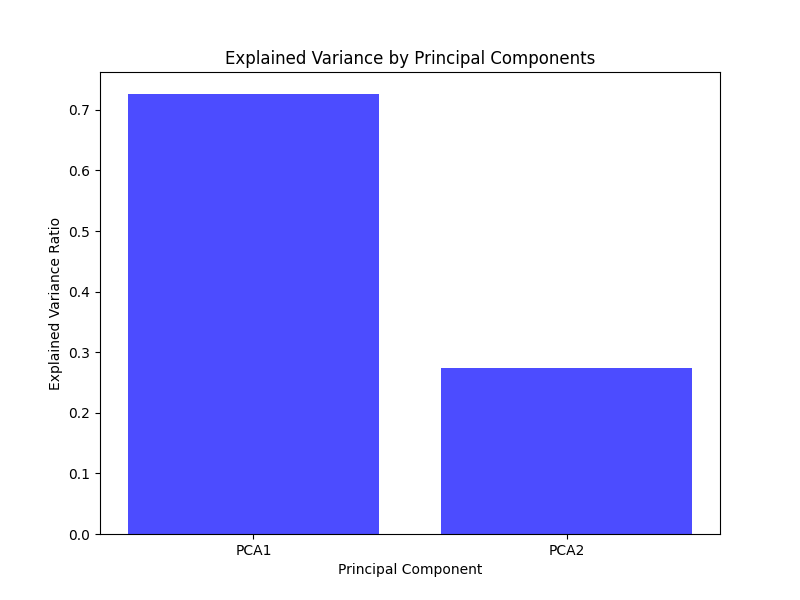
Step 5: Project the Data
Finally, we have to project the original data onto the dimensions represented by the selected principal components. To do that, we have to multiply the dataset, after being centered, by the matrix of eigenvectors found in the decomposition of the covariance matrix.
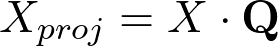
3. Implementation in Python
Now that we deeply understand the key concepts of Principal Component Analysis, it’s time to create some code.
First, we have to set the environment importing the numpy package for mathematical calculations and matplotlib for visualization:
import numpy as np
import matplotlib.pyplot as plt
Next, we will encapsulate all the concepts covered in the previous section in a Python class with the following methods:
- init method
Constructor method to initialize the algorithm’s parameters: the number of components desired, a matrix to store the components vectors, and an array to store the explained variance of each selected dimension.
- fit method
In the fit method, the first four steps presented in the previous section are implemented with code. Also, the explained variances of each component are calculated.
- Transform method
The transform method performs the last step presented in the previous section: project the data onto the selected dimensions.
- Plot explained variance
The last method is a helper function to plot the explained variance of each selected principal component as a bar plot.
Here is the full code:
class PCA:
def __init__(self, n_components):
self.n_components = n_components
self.components = None
self.mean = None
self.explained_variance = None
def fit(self, X):
# Step 1: Standardize the data (subtract the mean)
self.mean = np.mean(X, axis=0)
X_centered = X - self.mean
# Step 2: Compute the covariance matrix
cov_matrix = np.cov(X_centered, rowvar=False)
# Step 3: Compute the eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# Step 4: Sort the eigenvalues and corresponding eigenvectors
sorted_indices = np.argsort(eigenvalues)[::-1]
eigenvalues = eigenvalues[sorted_indices]
eigenvectors = eigenvectors[:, sorted_indices]
# Step 5: Select the top n_components
self.components = eigenvectors[:, :self.n_components]
# Calculate explained variance
total_variance = np.sum(eigenvalues)
self.explained_variance = eigenvalues[:self.n_components] / total_variance
def transform(self, X):
# Step 6: Project the data onto the selected components
X_centered = X - self.mean
return np.dot(X_centered, self.components)
def plot_explained_variance(self):
# Create labels for each principal component
labels = [f'PCA{i+1}' for i in range(self.n_components)]
# Create a bar plot for explained variance
plt.figure(figsize=(8, 6))
plt.bar(range(1, self.n_components + 1), self.explained_variance, alpha=0.7, align='center', color='blue', tick_label=labels)
plt.xlabel('Principal Component')
plt.ylabel('Explained Variance Ratio')
plt.title('Explained Variance by Principal Components')
plt.show()
4. Evaluation and interpretation
Now it’s time to use the class we just implemented on a simulated dataset created using the numpy package. The dataset has 10 features and 100 samples.
# create simulated data for analysis
np.random.seed(42)
# Generate a low-dimensional signal
low_dim_data = np.random.randn(100, 4)
# Create a random projection matrix to project into higher dimensions
projection_matrix = np.random.randn(4, 10)
# Project the low-dimensional data to higher dimensions
high_dim_data = np.dot(low_dim_data, projection_matrix)
# Add some noise to the high-dimensional data
noise = np.random.normal(loc=0, scale=0.5, size=(100, 10))
data_with_noise = high_dim_data + noise
X = data_with_noise
Before performing the PCA, one question remains: how do we choose the correct or optimal number of dimensions? Generally, we have to look for the number of components that add up to at least 95% of the explained variance of the dataset.
To do that, let’s take a look at how each principal component contributes to the total variance of the dataset:
# Apply PCA
pca = PCA(n_components=10)
pca.fit(X)
X_transformed = pca.transform(X)
print("Explained Variance:n", pca.explained_variance)
>> Explained Variance (%):
[55.406, 25.223, 11.137, 5.298, 0.641, 0.626, 0.511, 0.441, 0.401, 0.317]
Next, let’s plot the cumulative sum of the variance and check at which number of dimensions we achieve the optimal value of 95% of the total variance.
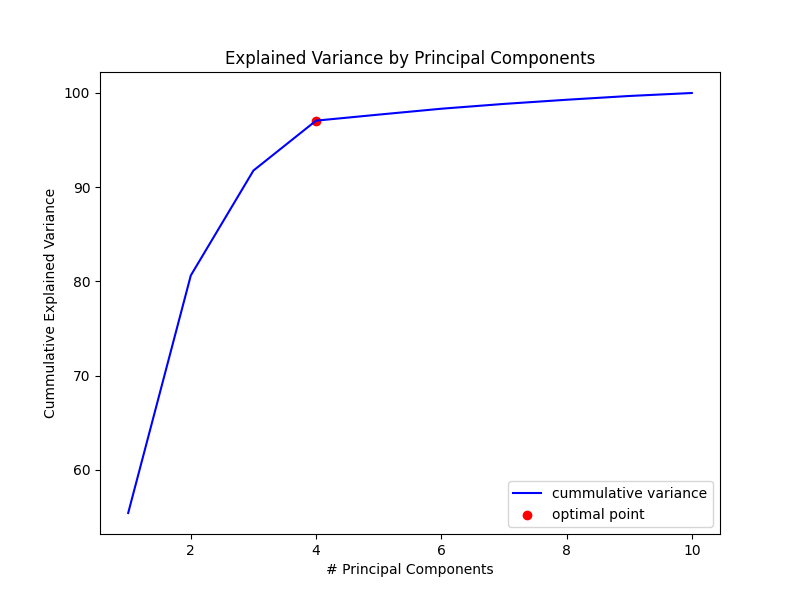
As shown in the graph above, the optimal number of dimensions for the dataset is 4, totaling 97.064% of the explained variance. In other words, we transformed a dataset with 10 features into one with only 3 dimensions while keeping more than 97% of the original information.
That means that most of the original 10 features were very correlated and the algorithm transformed that high-dimensional data into uncorrelated principal components.
5. Conclusions and Next Steps
We created a PCA class using only the numpy package that successfully reduced the dimensionality of a dataset from 10 features to just 4 while preserving approximately 97% of the data’s variance.
Also, we explored a method to obtain an optimal number of principal components of the PCA analysis that can be customized depending on the problem we are facing (we may be interested in retaining only 90% of the variance, for example).
That shows the potential of the PCA analysis to deal with the curse of dimensionality explained earlier. Additionally, I’d like to leave a few points for further exploration:
- Perform classification or regression tasks using other machine learning algorithms on the reduced dataset using the PCA algorithm and compare the performance of models trained on the original dataset versus the PCA-transformed dataset to assess the impact of dimensionality reduction.
- Use PCA for data visualization to make high-dimensional data more interpretable and to uncover patterns that were not evident in the original feature space.
- Consider exploring other dimensionality reduction techniques, such as t-Distributed Stochastic Neighbor Embedding (t-SNE) and Linear Discriminant Analysis (LDA).
Complete code available here.
ML-and-Ai-from-scratch/PCA at main · Marcussena/ML-and-Ai-from-scratch
Please feel free to use and improve the code, comment, make suggestions, and connect with me on LinkedIn, X, and Github.
References
[1] Willmott, Paul. (2019). Machine Learning: An Applied Mathematics Introduction. Panda Ohana Publishing.
[2] Géron, A. (2017). Hands-On Machine Learning. O’Reilly Media Inc.
[3] Grus, Joel. (2015). Data Science from Scratch. O’Reilly Media Inc.
[4] Datagy.io. How to Perform PCA in Python. Retrieved June 2, 2024, from https://datagy.io/python-pca/.
Principal Component Analysis Made Easy: A Step-by-Step Tutorial was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Principal Component Analysis Made Easy: A Step-by-Step Tutorial
Go Here to Read this Fast! Principal Component Analysis Made Easy: A Step-by-Step Tutorial