The Perils of Chasing p99
Hidden correlations can mislead optimization strategies

p99, or the value below which 99% of observations fall, is widely used to track and optimize worst-case performance across industries. For example, the time taken for a page to load, fulfill a shopping order or deliver a shipment can all be optimized by tracking p99.
While p99 is undoubtedly valuable, it’s crucial to recognize that it ignores the top 1% of observations, which may have an unexpectedly large impact when they are correlated with other critical business metrics. Blindly chasing p99 without checking for such correlations can potentially undermine other business objectives.
In this article, we will analyze the limitations of p99 through an example with dummy data, understand when to rely on p99, and explore alternate metrics.
The Correlation Conundrum
Consider an e-commerce platform where a team is tasked with optimizing the shopping cart checkout experience. The team has received customer complaints that checking out is rather slow compared to other platforms. So, the team grabs the latest 1,000 checkouts and analyzes the time taken for checking out. (I created some dummy data for this, you are free to use it and tinker with it without restrictions)
import pandas as pd
import seaborn as sns
order_time = pd.read_csv('https://gist.githubusercontent.com/kkraoj/77bd8332e3155ed42a2a031ce63d8903/raw/458a67d3ebe5b649ec030b8cd21a8300d8952b2c/order_time.csv')
fig, ax = plt.subplots(figsize=(4,2))
sns.histplot(data = order_time, x = 'fulfillment_time_seconds', bins = 40, color = 'k', ax = ax)
print(f'p99 for fulfillment_time_seconds: {order_time.fulfillment_time_seconds.quantile(0.99):0.2f} s')
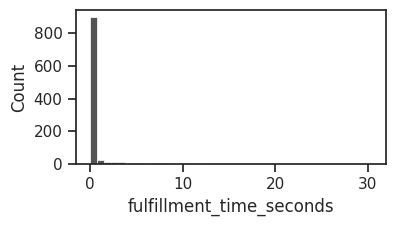
As expected, most shopping cart checkouts seem to be completing within a few seconds. And 99% of the checkouts happen within 12.1 seconds. In other words, the p99 is 12.1 seconds. There are a few long-tail cases that take as long as 30 seconds. Since they are so few, they may be outliers and should be safe to ignore, right?
Now, if we don’t pause and analyze the implication of the last sentence, it could be quite dangerous. Is it really safe to ignore the top 1%? Are we sure checkout times are not correlated with any other business metric?
Let’s say our e-commerce company also cares about gross merchandise value (GMV) and has an overall company-level objective to increase it. We should immediately check whether the time taken to checkout is correlated with GMV before we ignore the top 1%.
import matplotlib.pyplot as plt
from matplotlib.ticker import ScalarFormatter
order_value = pd.read_csv('https://gist.githubusercontent.com/kkraoj/df53cac7965e340356d6d8c0ce24cd2d/raw/8f4a30db82611a4a38a90098f924300fd56ec6ca/order_value.csv')
df = pd.merge(order_time, order_value, on='order_id')
fig, ax = plt.subplots(figsize=(4,4))
sns.scatterplot(data=df, x="fulfillment_time_seconds", y="order_value_usd", color = 'k')
plt.yscale('log')
ax.yaxis.set_major_formatter(ScalarFormatter())

Oh boy! Not only is the cart value correlated with checkout times, it increases exponentially for longer checkout times. What’s the penalty of ignoring the top 1% of checkout times?
pct_revenue_ignored = df2.loc[df1.fulfilment_time_seconds>df1.fulfilment_time_seconds.quantile(0.99), 'order_value_usd'].sum()/df2.order_value_usd.sum()*100
print(f'If we only focussed on p99, we would ignore {pct_revenue_ignored:0.0f}% of revenue')
## >>> If we only focussed on p99, we would ignore 27% of revenue
If we only focused on p99, we would ignore 27% of revenue (27 times greater than the 1% we thought we were ignoring). That is, p99 of checkout times is p73 of revenue. Focusing on p99 in this case inadvertently harms the business. It ignores the needs of our highest-value shoppers.
df.sort_values('fulfillment_time_seconds', inplace = True)
dfc = df.cumsum()/df.cumsum().max() # percent cumulative sum
fig, ax = plt.subplots(figsize=(4,4))
ax.plot(dfc.fulfillment_time_seconds.values, color = 'k')
ax2 = ax.twinx()
ax2.plot(dfc.order_value_usd.values, color = 'magenta')
ax.set_ylabel('cumulative fulfillment time')
ax.set_xlabel('orders sorted by fulfillment time')
ax2.set_ylabel('cumulative order value', color = 'magenta')
ax.axvline(0.99*1000, linestyle='--', color = 'k')
ax.annotate('99% of orders', xy = (970,0.05), ha = 'right')
ax.axhline(0.73, linestyle='--', color = 'magenta')
ax.annotate('73% of revenue', xy = (0,0.75), color = 'magenta')

Above, we see why there is a large mismatch between the percentiles of checkout times and GMV. The GMV curve rises sharply near the 99th percentile of orders, resulting in the top 1% of orders having an outsize impact on GMV.
This is not just an artifact of our dummy data. Such extreme correlations are unfortunately not uncommon. For example, the top 1% of Slack’s customers account for 50% of revenue. About 12% of UPS’s revenue comes from just 1 customer (Amazon).
A Balanced Approach
To avoid the pitfalls of optimizing for p99 alone, we can take a more holistic approach.
One solution is to track both p99 and p100 (the maximum value) simultaneously. This way, we won’t be prone to ignore high-value users.
Another solution is to use revenue-weighted p99 (or weighted by gross merchandise value, profit, or any other business metrics of interest), which assigns greater importance to observations with higher associated revenue. This metric ensures that optimization efforts prioritize the most valuable transactions or processes, rather than treating all observations equally.
Finally, when high correlations exist between the performance and business metrics, a more stringent p99.5 or p99.9 can mitigate the risk of ignoring high-value users.
Recap
It’s tempting to rely solely on metrics like p99 for optimization efforts. However, as we saw, ignoring the top 1% of observations can negatively impact a large percentage of other business outcomes. Tracking both p99 and p100 or using revenue-weighted p99 can provide a more comprehensive view and mitigate the risks of optimizing for p99 alone. At the very least, let’s remember to avoid narrowly focusing on some performance metric while losing sight of overall customer outcomes.
Written with the help of Perplexity (for definitions and background research, chat here) and ChatGPT (for spellcheck, chat here).
Perils of Chasing p99 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Perils of Chasing p99