What can data scientists learn should they choose to accept this mission?

Earlier this year, Gunnar Morling launched the One Billon Row Challenge, which has since gained a lot of popularity. Although the original challenge was meant to be done using Java, the amazing open-source community has since shared impressive solutions in different programming languages. I noticed that not many people had tried using Julia (or at least not publicly shared results), so decided to share my own humble attempt via this article.
A question that often came to my mind was what value does this challenge bring to a data scientist? Can we learn something more other than just doing a fun exercise? After all, the goal of the challenge is to “simply” parse a large dummy data file, calculate basic statistics (min, max and mean), and output the data in a specific format. This might not be a realistic situation for most if not all projects that data scientists usually work on.
Well, one aspect of the problem has to do with the size of the data versus the available RAM. When working locally (laptop or a desktop), for most people, it will be difficult to load the data all at once into memory. Dealing with larger than memory data sets therefore becomes an essential skill, which might come in handy when prototyping big data pipelines or performing big data analysis/visualization tasks. The rules of the original challenge also state that use of external libraries/packages should be avoided. This forces you to think of novel solutions and provides a fascinating opportunity to learn the nuances of the language itself.
In rest of the article, I will share results from both the approaches — using base Julia and also with external packages. This way, we get to compare the pros and cons of each. All experiments have been performed on a desktop equipped with AMD Ryzen 9 5900X (12 cores, 24 threads), 32 GB RAM and Samsung NVMe SSD. Julia 1.10.2 is running on Linux (Elementary OS 7.1 Horus). All relevant code is available here. Do note that the performance in this case is also tied to the hardware, so results may vary in case you decide to run the scripts on your own system.
Prerequisites
A recent release of Julia such as 1.10 is recommended. For those wanting to use a notebook, the repository shared above also contains a Pluto file, for which Pluto.jl needs to be installed. The input data file for the challenge is unique for everyone and needs to be generated using this Python script. Keep in mind that the file is about 15 GB in size.
python3 create_measurements.py 1000000000
Additionally, we will be running benchmarks using the BenchmarkTools.jl package. Note that this does not impact the challenge, it’s only meant to collect proper statistics to measure and quantify the performance of the Julia code.
Using base Julia
The structure of the input data file measurements.txt is as follows (only the first five lines are shown):
attipūdi;-49.2
Bas Limbé;-43.8
Oas;5.6
Nesebar;35.9
Saint George’s;-6.6
The file contains a billion lines (also known as rows or records). Each line has a station name followed by the ; separator and then the recorded temperature. The number of unique stations can be up to 10,000. This implies that the same station appears on multiple lines. We therefore need to collect all the temperatures for all distinct stations in the file, and then calculate the required statistics. Easy, right?
Let’s start slow but simple
My first attempt was to simply parse the file one line at a time, and then collect the results in a dictionary where every station name is a key and the temperatures are added to a vector of Float64 to be used as the value mapped to the key. I expected this to be slow, but our aim here is to get a number for the baseline performance.
Once the dictionary is ready, we can calculate the necessary statistics:
The output of all the data processing needs to be displayed in a certain format. This is achieved by the following function:
Since this implementation is expected to take long, we can run a simple test by timing @time the following only once:
@time get_stations_dict_v2("measurements.txt") |> calculate_output_v3 |> print_output_v1
<output omitted for brevity> 526.056399 seconds (3.00 G allocations: 302.881 GiB, 3.68% gc time)
Our poor man’s implementation takes about 526 seconds, so ~ 9 minutes. It’s definitely slow, but not that bad at all!
Taking it up a notch — Enter multithreading!
Instead of reading the input file one line at a time, we can try to split it into chunks, and then process all the chunks in parallel. Julia makes it quite easy to implement a parallel for loop. However, we need to take some precautions while doing so.
Before we get to the loop, we first need to figure out how to split the file into chunks. This can be achieved using memory mapping to read the file. Then we need to determine the start and end positions of each chunk. It’s important to note that each line in the input data file ends with a new-line character, which has 0x0a as the byte representation. So each chunk should end at that character to ensure that we don’t make any errors while parsing the file.
The following function takes the number of chunksnum_chunksas an input argument, then returns an array with each element as the memory mapped chunk.
Since we are parsing station and temperature data from different chunks, we also need to combine them in the end. Each chunk will first be processed into a dictionary as shown before. Then, we combine all chunks as follows:
Now we know how to split the file into chunks, and how we can combine the parsed dictionaries from the chunks at the end. However, the desired speedup can only be obtained if we are also able to process the chunks in parallel. This can be done in a for loop. Note that Julia should be started with multiple threads julia -t 12 for this solution to have any impact.
Additionally, we now want to run a proper statistical benchmark. This means that the challenge should be executed a certain number of times, and we should then be able to visualize the distribution of the results. Thankfully, all of this can be easily done with BenchmarkTools.jl. We cap the maximum number of samples to 10, maximum time for the total run to be 20 minutes and enable garbage collection (will free up memory) to execute between samples. All of this can be brought together in a single script. Note that the input arguments are now the name of the file fname and the number of chunks num_chunks.
Benchmark results along with the inputs used are shown below. Note that we have used 12 threads here.
julia> Threads.nthreads()
12
julia> ARGS = ["measurements.txt", "48"]
2-element Vector{String}:
"measurements.txt"
"48"
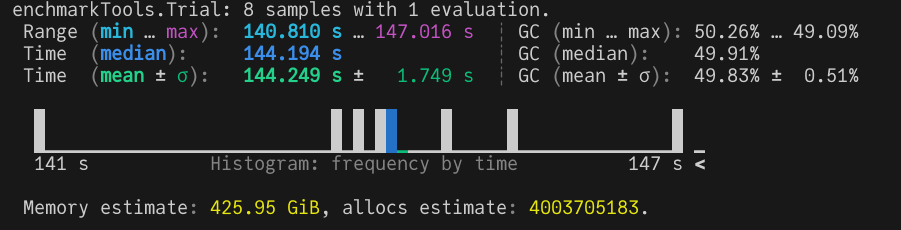
Multi-threading provides a big performance boost, we are now down to roughly over 2 minutes. Let’s see what else we can improve.
Avoiding storing all temperature data
Until now, our approach has been to store all the temperatures, and then determine the required statistics (min, mean and max) at the very end. However, the same can already be achieved while we parse every line from the input file. We replace existing values each time a new value which is either larger (for maximum) or smaller (for minimum) is found. For mean, we sum all the values and keep a separate counter as to how many times a temperature for a given station has been found.
Overall, out new logic looks like the following:
The function to combine all the results (from different chunks) also needs to be updated accordingly.
Let’s run a new benchmark and see if this change improves the timing.

The median time seems to have improved, but only slightly. It’s a win, nonetheless!
More performance enhancement
Our previous logic to calculate and save the mix, max for temperature can be further simplified. Moreover, following the suggestion from this Julia Discourse post, we can make use of views (using @view ) when parsing the station names and temperature data. This has also been discussed in the Julia performance manual. Since we are using a slice expression for parsing every line, @view helps us avoid the cost of allocation and copying.
Rest of the logic remains the same. Running the benchmark now gives the following:

Whoa! We managed to reach down to almost a minute. It seems switching to a view does make a big difference. Perhaps, there are further tweaks that could be made to improve performance even further. In case you have any suggestions, do let me know in the comments.
Using external packages
Restricting ourselves only to base Julia was fun. However, in the real world, we will almost always be using packages and thus making use of existing efficient implementations for performing the relevant tasks. In our case, CSV.jl (parsing the file in parallel) and DataFrames.jl (performing groupby and combine) will come in handy.
The function below performs the following tasks:
- Use Mmap to read the large file
- Split file into a predefined number of chunks
- Loop through the chunks, read each chunk in parallel using CSV.read (12 threads passed to ntasks) into a DataFrame.
- Use DataFrame groupby and combine to get the results for each station
- Concatenate all DataFrames to combine results from all chunks
- Once outside the loop, perform a groupby and combine again to get the final set of results for all stations.
We can now run the benchmark in the same manner as before.

The performance using CSV.jl and DataFrames.jl is quite good, albeit slower than our base Julia implementation. When working on real world projects, these packages are an essential part of a data scientist’s toolkit. It would thus be interesting to explore if further optimizations are possible using this approach.
Conclusion
In this article, we tackled the One Billion Row Challenge using Julia. Starting from a very naive implementation that took ~ 10 minutes, we managed to gain significant performance improvement through iterative changes to the code. The most optimized implementation completes the challenge in ~ 1 minute. I am certain that there’s still more room for improvement. As an added bonus, we learned some valuable tricks on how to deal with larger than memory data sets. This might come in handy when doing some big data analysis and visualization using Julia.
I hope you found this exercise useful. Thank you for your time! Connect with me on LinkedIn or visit my Web 3.0 powered website.
References
- https://www.morling.dev/blog/one-billion-row-challenge/
- https://docs.julialang.org/en/v1/manual/performance-tips/index.html#man-performance-annotations
The One Billion Row Challenge in Julia was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The One Billion Row Challenge in Julia
Go Here to Read this Fast! The One Billion Row Challenge in Julia