Embracing uncertainty, right people, and learning from the data

This blog post is an updated version of part of a conference talk I gave at GOTO Amsterdam last year. The talk is also available to watch online.
Providing value and positive impact through machine learning product initiatives is not an easy job. One of the main reasons for this complexity is the fact that, in ML initiatives developed for digital products, two sources of uncertainty intersect. On one hand, there is the uncertainty related to the ML solution itself (will we be able to predict what we need to predict with good enough quality?). On the other hand, there is the uncertainty related to the impact the whole system will be able to provide (will users like this new functionality? will it really help solve the problem we are trying to solve?).
All this uncertainty means failure in ML product initiatives is something relatively frequent. Still, there are strategies to manage and improve the probabilities of success (or at least to survive through them with dignity!). Starting ML initiatives on the right foot is key. I discussed my top learnings in that area in a previous post: start with the problem (and define how predictions will be used from the beginning), start small (and maintain small if you can), and prioritize the right data (quality, volume, history).
Starting ML Product Initiatives on the Right Foot
However, starting a project is just the beginning. The challenge to successfully manage an ML initiative and provide a positive impact continues throughout the whole project lifecycle. In this post, I’ll share my top three learnings on how to survive and thrive during ML initiatives:
- Embrace uncertainty: innovation, stopping, pivoting, and failing.
- Surround yourself with the right people: roles, skills, diversity, and the network.
- Learn from the data: right direction, be able to improve, and detect failures and have a plan.
Embrace uncertainty
It is really hard (impossible even!) to plan ML initiatives beforehand and to develop them according to that initial plan.
The most popular project plan for ML initiatives is the ML Lifecycle, which splits the phases of an ML project into business understanding, data understanding, data preparation, modeling, evaluation, and deployment. Although these phases are drawn as consecutive steps, in many representations of this lifecycle you’ll find arrows pointing backward: at any point in the project, you might learn something that forces you to go back to a previous phase.
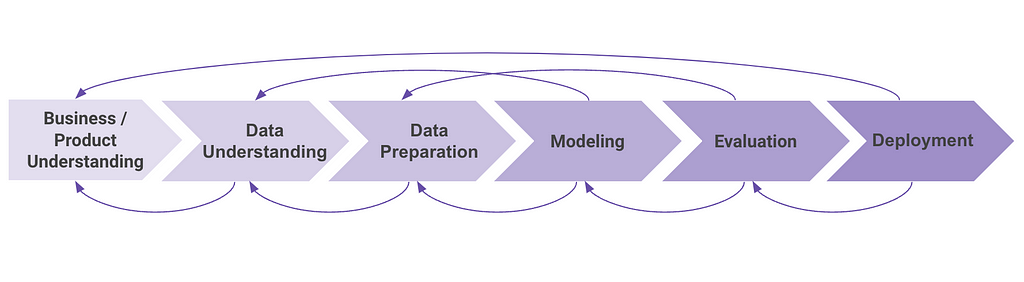
This translates into projects where it is really hard to know when they will finish. For example, during the evaluation step, you might realize thanks to model explainability techniques that a specific feature wasn’t well encoded, and this forces you to go back to the data preparation phase. It could also happen that the model isn’t able to predict with the quality you need, and might force you to go back to the beginning in the business understanding phase to redefine the project and business logic.
Whatever your role in an ML initiative or project is, it is key to acknowledge things won’t go according to plan, to embrace all this uncertainty from the beginning, and to use it to your advantage. This is important both to managing stakeholders (expectations, trust) and for yourself and the rest of the team (motivation, frustration). How?
- Avoid too ambitious time or delivery constraints, by ensuring ML initiatives are perceived as what they really are: innovation that needs to explore the unknown and has high risk, but high reward and potential too.
- Know when to stop, by balancing the value of each incremental improvement (ML models can always be improved!) with its price in terms of time, effort, and opportunity cost.
- Be ready to pivot and fail, by continuously leveraging the learnings and insights the project grants you, and to decide to modify the project scope, or even to kill it if that is what those new learnings tell you.
Surround yourself with the right people

Any project starts with people. The right combination of people, skills, perspectives, and a network that empowers you.
The days when Machine Learning (ML) models were confined to the Data Scientist’s laptop are over. Today, the true potential of ML is realised when models are deployed and integrated into the company’s processes. This means more people and skills need to collaborate to make that possible (Data Scientists, Machine Learning Engineers, Backend Developers, Data Engineers…).
The first step is identifying the skills and roles that are required to successfully build the end-to-end ML solution. However, more than a group of roles covering a list of skills is required. Having a diverse team that can bring different perspectives and empathize with different user segments has proven to help teams improve their ways of working and build better solutions (“why having a diverse team will make your products better”).
People don’t talk about this enough, but the key people to deliver a project go beyond the team itself. I refer to these other people as “the network”. The network is people you know are really good at specific things, you trust to ask for help and advice when needed, and can unblock, accelerate, or empower you and the team. The network can be your business stakeholders, manager, staff engineers, user researchers, data scientists from other teams, customer support team… Ensure you build your own network and identify who is that ally who you can go to depending on each specific situation or need.
Learn from your data
A project is a continuous learning opportunity, and many times learnings and insights come from checking the right data and monitors.
In ML initiatives there are 3 big groups of metrics and measures that can bring a lot of value in terms of learnings and insights: model performance monitoring, service performance, and final impact monitoring. In a previous post I deep dive into this topic.
ML systems monitoring: from service performance to positive business impact
Checking at the right data and monitors while developing or deploying ML solutions is key to:
- Ensure moving in the right direction: this includes many things from the right design of the solution or choosing the right features, to understanding if there is a need to pivot or even stop the project.
- Know what or how to improve: to understand if outcome goals were reached (e.g. through experimentation or a/b testing), and to deep dive on what went well, what didn’t, and how to continue delivering value.
- Detect failure on time and have a plan: to enable quick responses to issues, ideally before they impact the business. Even if they do impact the business, having the right metrics should allow you to understand the why behind the failure, maintain things under control, and prepare a plan to move forward (while maintaining the trust of your stakeholders).
Wrapping it up
Effectively managing ML initiatives from beginning until end is a complex task with multiple dimensions. In this blogpost I shared, based on my experience first as Data Scientist and lately as ML Product Manager, the factors I consider key when dealing with an ML project: embracing uncertainty, surrounding yourself with the right people, and learning from the data.
I hope these insights help you successfully manage your ML initiatives and drive positive impact through them. Stay tuned for more posts about the intersection of Machine Learning and Product Management 🙂
Effective Strategies for Managing ML Initiatives was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Effective Strategies for Managing ML Initiatives
Go Here to Read this Fast! Effective Strategies for Managing ML Initiatives