

Understanding “You Only Cache Once”
This blog post will go in detail on the “You Only Cache Once: Decoder-Decoder Architectures for Language Models” Paper and its findings
As the Large Language Model (LLM) space becomes more mature, there are increasing efforts to take the current performance and make it more cost-effective. This has been done by creating custom hardware for them to run on (ie Language Processing Units by Groq), by optimizing the low level software that they interact with (think Apple’s MLX Library or NVIDIA’s CUDA Library), and by becoming more deliberate with the calculations the high-level software does.
The “You Only Cache Once: Decoder-Decoder Architectures for Language Models” paper presents a new architecture for LLMs that improves performance by using memory-efficient architecture. They call this YOCO.
Let’s dive in!
Key-Value (KV) Cache
To understand the changes made here, we first need to discuss the Key-Value Cache. Inside of the transformer we have 3 vectors that are critical for attention to work — key, value, and query. From a high level, attention is how we pass along critical information about the previous tokens to the current token so that it can predict the next token. In the example of self-attention with one head, we multiply the query vector on the current token with the key vectors from the previous tokens and then normalize the resulting matrix (the resulting matrix we call the attention pattern). We now multiply the value vectors with the attention pattern to get the updates to each token. This data is then added to the current tokens embedding so that it now has the context to determine what comes next.

We create the attention pattern for every single new token we create, so while the queries tend to change, the keys and the values are constant. Consequently, the current architectures try to reduce compute time by caching the key and value vectors as they are generated by each successive round of attention. This cache is called the Key-Value Cache.
While architectures like encoder-only and encoder-decoder transformer models have had success, the authors posit that the autoregression shown above, and the speed it allows its models, is the reason why decoder-only models are the most commonly used today.
YOCO Architecture
To understand the YOCO architecture, we have to start out by understanding how it sets out its layers.
For one half of the model, we use one type of attention to generate the vectors needed to fill the KV Cache. Once it crosses into the second half, it will use the KV Cache exclusively for the key and value vectors respectively, now generating the output token embeddings.
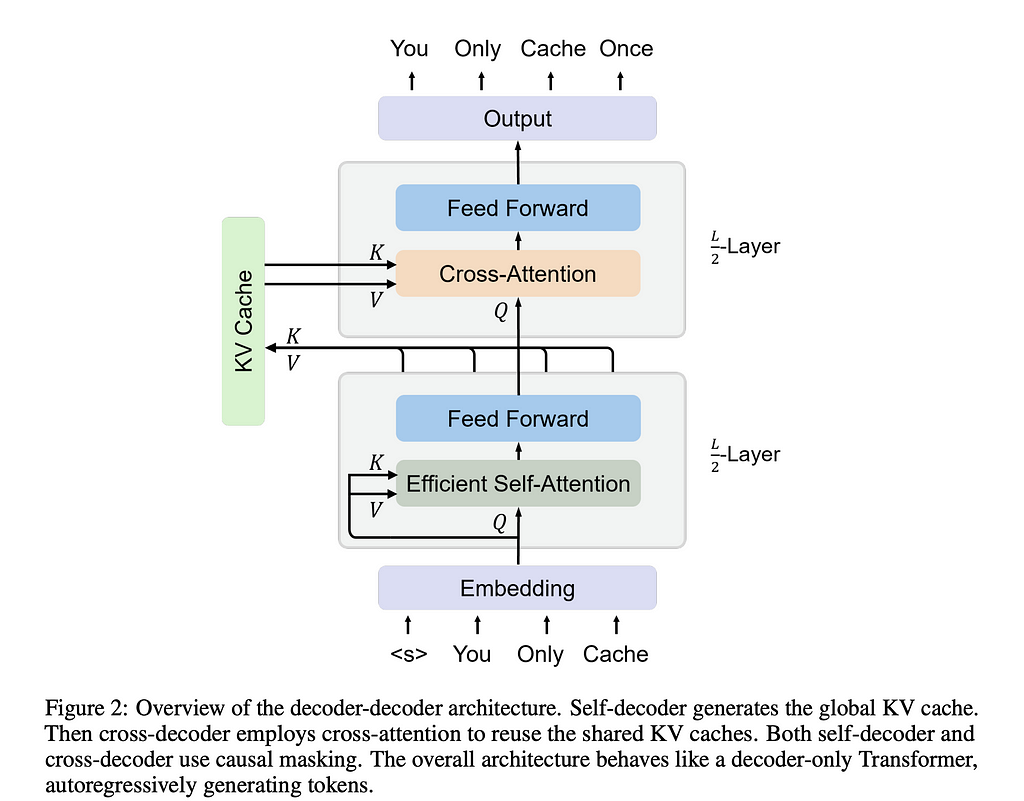
This new architecture requires two types of attention — efficient self-attention and cross-attention. We’ll go into each below.
Efficient Self-Attention and Self-Decoder
Efficient Self-Attention (ESA) is designed to achieve a constant inference memory. Put differently we want the cache complexity to rely not on the input length but on the number of layers in our block. In the below equation, the authors abstracted ESA, but the remainder of the self-decoder is consistent as shown below.

Let’s go through the equation step by step. X^l is our token embedding and Y^l is an intermediary variable used to generate the next token embedding X^l+1. In the equation, ESA is Efficient Self-Attention, LN is the layer normalization function — which here was always Root Mean Square Norm (RMSNorm ), and finally SwiGLU. SwiGLU is defined by the below:
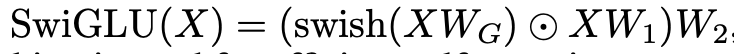
Here swish = x*sigmoid (Wg * x), where Wg is a trainable parameter. We then find the element-wise product (Hadamard Product) between that result and X*W1 before then multiplying that whole product by W2. The goal with SwiGLU is to get an activation function that will conditionally pass through different amounts of information through the layer to the next token.
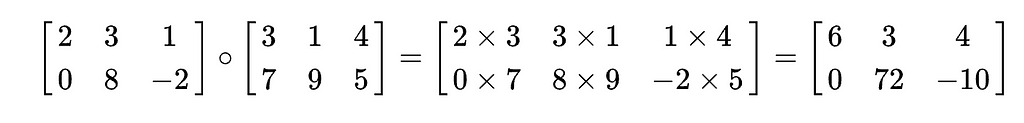
Now that we see how the self-decoder works, let’s go into the two ways the authors considered implementing ESA.
Gated Retention ESA
First, they considered what is called Gated Retention. Retention and self-attention are admittedly very similar, with the authors of the “Retentive Network: A Successor to Transformer for Large Language Models” paper saying that the key difference lies in the activation function — retention removes softmax allowing for a recurrent formulation. They use this recurrent formulation along with the parallelizability to drive memory efficiencies.
To dive into the mathematical details:
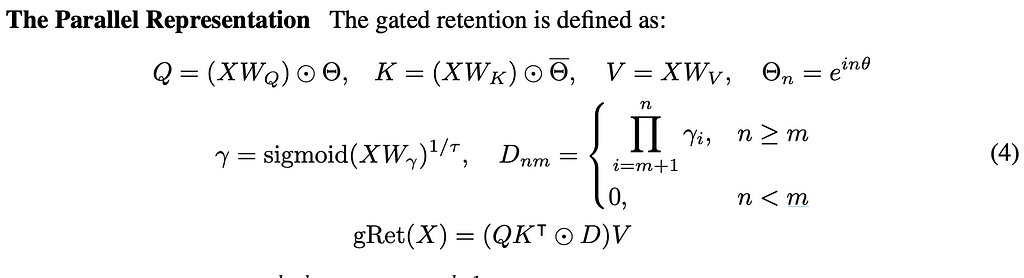
We have our typical matrices of Q, K, and V — each of which are multiplied by the learnable weights associated with each matrix. We then find the Hadamard product between the weighted matrices and the scalar Θ. The goal in using Θ is to create exponential decay, while we then use the D matrix to help with casual masking (stopping future tokens from interacting with current tokens) and activation.
Gated Retention is distinct from retention via the γ value. Here the matrix Wγ is used to allow our ESA to be data-driven.
Sliding Window ESA
Sliding Window ESA introduces the idea of limiting how many tokens the attention window should pay attention to. While in regular self-attention all previous tokens are attended to in some way (even if their value is 0), in sliding window ESA, we choose some constant value C that limits the size of these matrices. This means that during inference time the KV cache can be reduced to a constant complexity.
To again dive into the math:
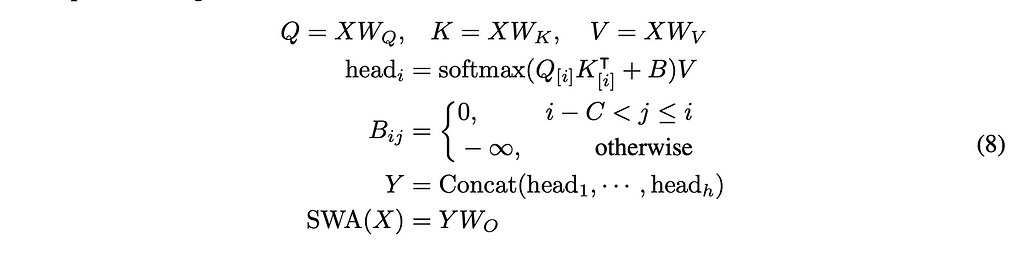
We have our matrices being scaled by their corresponding weights. Next, we compute the head similar to how multi-head attention is computed, where B acts both as a causal map and also to make sure only the tokens C back are attended to.
Whether using sliding window or gated retention, the goal of the first half of the model is to generate the KV cache which will then be used in the second half to generate the output tokens.
Now we will see exactly how the global KV cache helps speed up inference.
Cross-Attention and the Cross-Decoder
Once moving to the second half of the model, we first create the global KV cache. The cache is made up of K-hat and V-hat, which we create by running a layer normalization function on the tokens we get out of the first half of the model and then multiply these by their corresponding weight matrix.
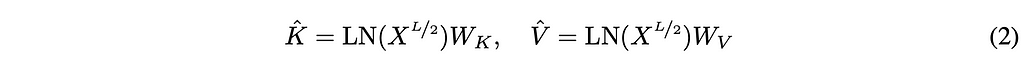
With the global KV cache created, we now leverage a different decoder and attention to generate the next tokens. To dive into the math below:

We generate our query matrix by taking the token embedding and running the same normalization and then matrix multiplication on this as we did on K-hat and V-hat, the difference being we run this on every token that comes through, not just on the ones from the end of the first half of the model. We then run cross attention on the three matrices, and use normalization and SwiGLU from before to determine what the next token should be. This X^l+1 is the token that is then predicted.
Cross attention is very similar to self-attention, the twist here is that cross-attention leverages embeddings from different corpuses.
Memory Advantages
Let’s begin by analyzing the memory complexity between Transformers and YOCOs. For the Transformer, we have to keep in memory the weights for the input sequence (N) as well as the weights for each layer (L) and then do so for every hidden dimension (D). This means we are storing memory on the order of L * N * D.
By comparison, the split nature of YOCO means that we have 2 situations to analyze to find out the big O memory complexity. When we run through the first half of the model, we are doing efficient self-attention, which we know wants a constant cache size (either by sliding window attention or gated retention). This makes its big O dependent on the weights for each layer (L) and the number of hidden dimensions in the first half of the model(D). The second half uses cross-attention which keeps in memory the weights for the input sequence (N), but then uses the constant global cache, making it not change from the big O memory analysis point of view. Thus, the only other dependent piece is the number of hidden dimensions in the second half of the model(D), which we will say is effectively the same. Thus, we are storing memory on the order of L * D + N * D = (N + L) * D

The authors note that when the input size is significantly bigger than the number of layers, the big O calculation approximates O(N), which is why they call their model You Only Cache Once.
Inference Advantages
During inference, we have two major stages: prefilling (sometimes called initiation) and then generation (sometimes call decoding). During prefilling, we are taking the prompt in and create all of the necessary computations to generate the first output. This can start with loading model weights into the GPU memory and then end with the first token being output. Once that first output is created, the autoregressive nature of transformers means that the lion-share of the calculations needed to create the entire response has already been completed.

Starting with the prefilling stage, both the transfomer and YOCO model will load in the weights to GPU memory in the same time, but YOCO has two major advantages after that. First, because YOCO’s self-decoder can run in parallel, it can run significantly faster than the regular self-attention without parallelization. Second, as only the first half generates the global KV cache, only half of the model needs to run during prefilling, significantly reducing the number of computations. Both of these result in YOCO’s prefilling stage being much faster than a transformers (roughly 30x so!)
During the generation stage, we do not have to have as many changes of GPU memory with YOCO as we would with a transformer for the reasons shown above. This is a major contributor to the throughput that YOCO can achieve.
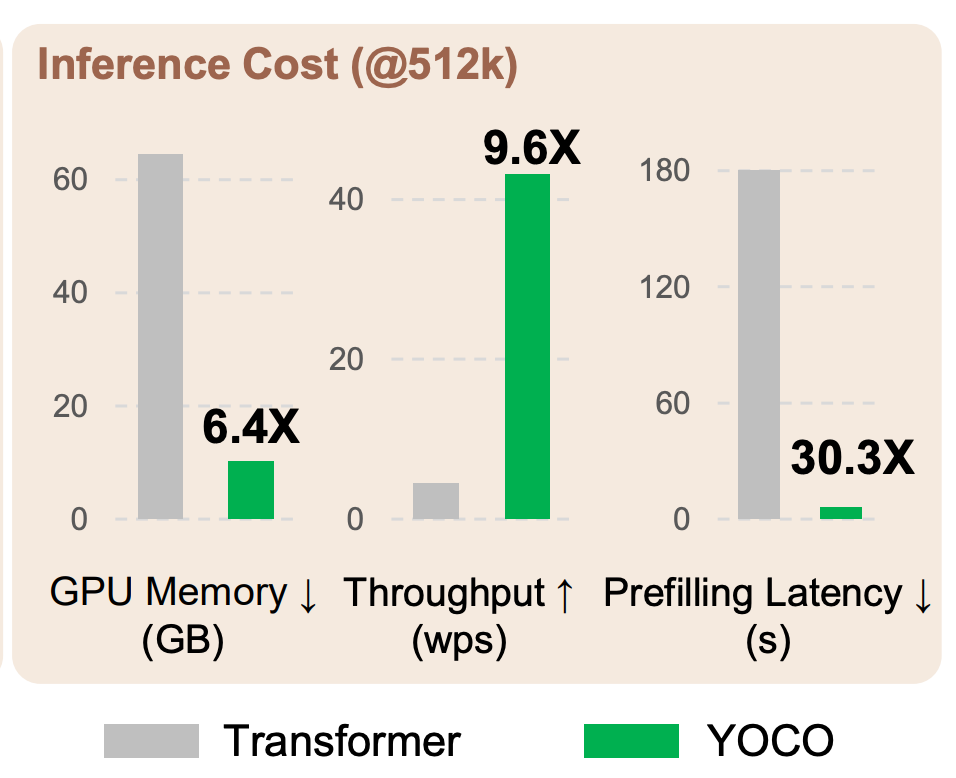
All of these metrics highlight that the architecture change alone can introduce significant efficiencies for these models.
Conclusion
With new architectures, there comes a bit of a dilemma. After having spent billions of dollars training models with older architectures, companies rightfully wonder if it is worth spending billions more on a newer architecture that may itself be outmoded soon.
One possible solution to this dilemma is transfer learning. The idea here is to put noise into the trained model and then use the output given to then backpropagate on the new model. The idea here is that you don’t need to worry about generating huge amounts of novel data and potentially the number of epochs you have to train for is also significantly reduced. This idea has not been perfected yet, so it remains to be seen the role it will play in the future.
Nevertheless, as businesses become more invested in these architectures the potential for newer architectures that improve cost will only increase. Time will tell how quickly the industry moves to adopt them.
For those who are building apps that allow for a seamless transition between models, you can look at the major strives made in throughput and latency by YOCO and have hope that the major bottlenecks your app is having may soon be resolved.
It’s an exciting time to be building.
With special thanks to Christopher Taylor for his feedback on this blog post.
[1] Sun, Y., et al. “You Only Cache Once: Decoder-Decoder Architectures for Language Models” (2024), arXiv
[2] Sun, Y., et al. “Retentive Network: A Successor to Transformer for Large Language Models” (2023), arXiv
[3] Wikimedia Foundation, et al. “Hadamard product (matrices)” (2024), Wikipedia
[4] Sanderson, G. et al., “Attention in transformers, visually explained | Chapter 6, Deep Learning” (2024), YouTube
[5] A. Vaswani, et al., “Attention Is All You Need” (2017), arXiv
Understanding You Only Cache Once was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Understanding You Only Cache Once
Go Here to Read this Fast! Understanding You Only Cache Once