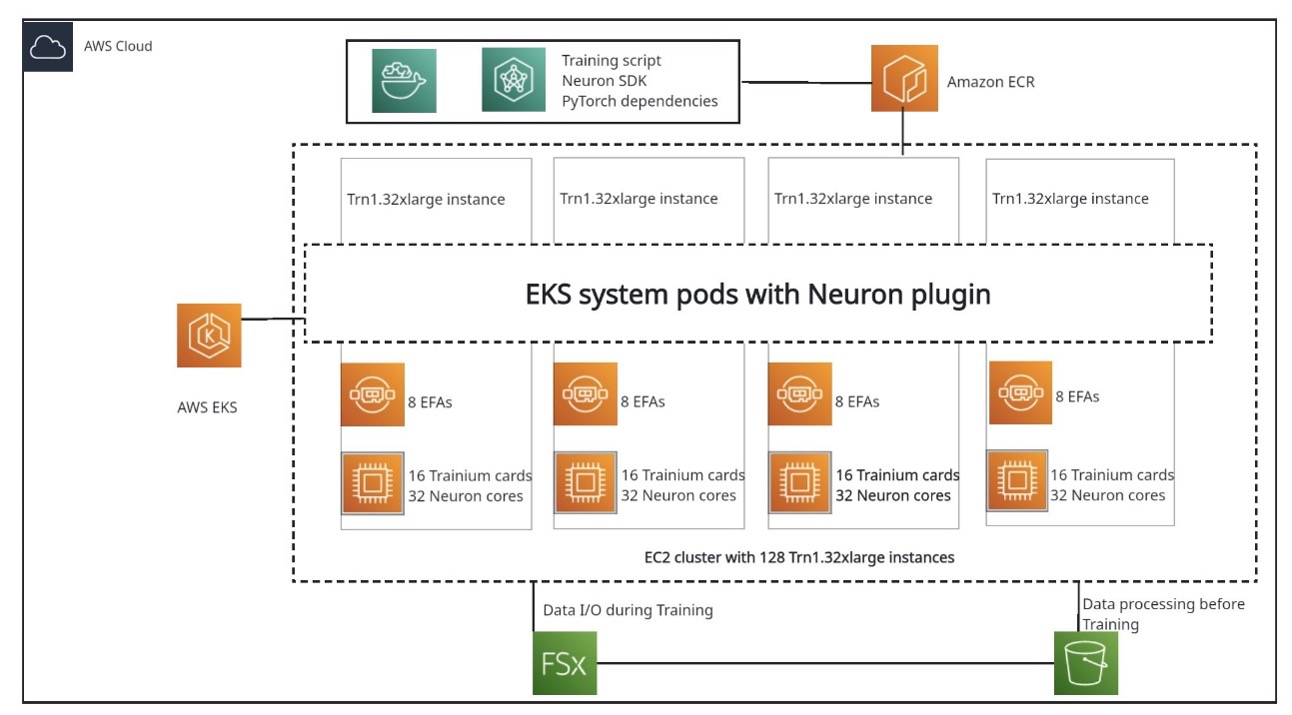

In this post, we show you how to accelerate the full pre-training of LLM models by scaling up to 128 trn1.32xlarge nodes, using a Llama 2-7B model as an example. We share best practices for training LLMs on AWS Trainium, scaling the training on a cluster with over 100 nodes, improving efficiency of recovery from system and hardware failures, improving training stability, and achieving convergence.
Originally appeared here:
End-to-end LLM training on instance clusters with over 100 nodes using AWS Trainium