How Google figures out the price of a product across websites
Written by Varun Joshi and Gauri Kamat
As e-commerce continues to dominate the retail space, the challenge of accurately matching products across platforms and databases grows more complex. In this article, we demonstrate that product matching can simply be an instance of the wider statistical framework of entity resolution.
Product matching (PM) refers to the problem of figuring out if two separate listings actually refer to the same product. There are a variety of situations where this is important. For example, consider the use-cases below:
- With the rapid expansion of online marketplaces, e-commerce platforms (e.g., Amazon) have thousands of sellers offering their products, and new sellers are regularly on-boarded to the platform. Moreover, these sellers potentially add thousands of new products to the platform every day [1]. However, the same product might already be available on the website from other sellers. Product matching is required to group these different offers into a single listing so that customers can have a clear view of the different offers available for a product
- In e-commerce marketplaces, sellers can also create duplicate listings to acquire more real estate on the search page. In other words, they can list the same product multiple times (with slight variation in title, description, etc.) to increase the probability that their product will be seen by the customer. To improve customer experience, product matching is required to detect and remove such duplicate listings
- Another important use case is competitor analysis. To set competitive prices and make decisions on the inventory, e-commerce companies need to be aware of the offers for the same product across their competition.
- Finally, price comparison services e.g., Google shopping [2], need product matching to figure out the price for a product across different platforms.
In this article, we show how the Entity Resolution (ER) framework helps us solve the PM problem. Specifically, we describe a framework widely used in ER, and demonstrate its application on a synthetic PM dataset. We begin by providing relevant background on ER.
What is entity resolution?
Entity Resolution (ER) is a technique that identifies duplicate entities either within, or across data sources. ER within the same database is commonly called deduplication, while ER across multiple databases is called record linkage. When unique identifiers (like social security numbers) are available, ER is a fairly easy task. However, such identifiers are typically unavailable for reasons owing to data privacy. In these cases, ER becomes considerably more complex.
Why does ER matter? ER can help augment existing databases with data from additional sources. This allows users to perform new analyses, without the added cost of collecting more data. ER has found applications across multiple domains, including e-commerce, human rights research, and healthcare. A recent application involves counting casualties in the El Salvadoran civil war, by applying ER to retrospective mortality surveys. Another interesting application is deduplicating inventor names in a patents database maintained by the U.S. Patents and Trademarks Office.
Deterministic and Probabilistic ER
Deterministic ER methods rely on exact agreement on all attributes of any record pair. For instance, suppose that we have two files A and B. Say we are comparing record a from file A and b from file B. Further, suppose that the comparison is based on two attributes: product type (for e.g., clothing, electronics) and manufacturing year. A deterministic rule declares (a, b) to be a link, if product typeᵃ = product typeᵇ and yearᵃ= yearᵇ. This is workable, as long as all attributes are categorical. If we have a textual attribute like product name, then deterministic linking may produce errors. For example, if nameᵃ = “Sony TV 4” and nameᵇ = “Sony TV4”, then (a,b) will be declared a non-link, even though the two names only differ by a space.
What we then need is something that takes into account partial levels of agreement. This is where probabilistic ER can be used. In probabilistic ER, every pair (a,b) is assigned a probability of being a link, based on (1) how many attributes agree; and (2) how well they agree. For example, if product typeᵃ = product typeᵇ, yearᵃ= yearᵇ, and nameᵃ and nameᵇ are fairly close, then (a,b) will be assigned a high probability of being a link. If product typeᵃ = product typeᵇ, yearᵃ= yearᵇ, but nameᵃ and nameᵇ are poles apart (e.g. “AirPods” and “Sony TV4”), then this probability will be much lower. For textual attributes, probabilistic ER relies on string distance metrics, such as the Jaro-Winkler and the Levenshtein distances.
The Fellegi-Sunter model
The Fellegi-Sunter model [3] provides a probabilistic framework, allowing analysts to quantify the likelihood of a match between records, based on the similarity of their attributes. The model operates by calculating a match weight for each record pair from both files. This weight reflects the degree of agreement between their respective attributes. For a given record-pair the match weight is
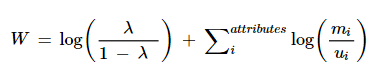
where mᵢ is the the probability that the two records agree on attribute i given that they are a match; uᵢ is the probability that the two records agree on attribute i given that they are a non-match; and lambda is the prior probability of a match, i.e. the probability of matching given no other information about the record pair. The m probability generally reflects the quality of the variables used for linking, while the u probability reflects incidental agreement between non matching record pairs.
The match weight is converted to a match probability between two records.
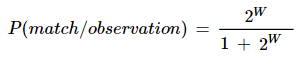
Finally, the match probability is compared to a chosen threshold value to decide whether the record pair is a match, a non-match, or requires further manual review.
Illustration with synthetic product data
Data Generation
We generate data to reflect a realistic product matching scenario. Specifically, we generate file A comprising 79 records, and file B comprising 192 records. There are 59 overlapping records between the two files. Both files contain four linking variables, namely the product name, product type, brand, and price. For example, a record in file A representing Apple airpods has the product name “Apple AirPods”, product type “Earbuds”, the recorded brand is “Apple” and the product price is $200. The product name, type, and brand are string-valued variables, while the price is a continuous-valued numeric variable. We also generate errors in each of the linking variables. In the string valued fields, we introduce deletion errors; for example, a series 6 Apple watch may be recorded as “Apple Watch Series 6” in file A and as “Apple Watch 6” in file B. We also introduce case-change errors in the string fields; for example, the same product may be recorded as “apple watch series 6” in file A and as “Apple Watch 6” in file B. The continuous nature of the price variable may automatically induce errors. For example, a product may be priced at $55 in one file, but $55.2 in the other.
For synthetic data generation, we used the free version of ChatGPT (i.e., GPT 3.5) [4]. The following three prompts were used for data generation:
Prompt 1: to generate the dataset with links
Generate a synthetic dataset which links 59 distinct products from two different sources.
The dataset should have the following columns: Title_A, Product_Type_A, Brand_A, Price_A, Title_B, Product_Type_B, Brand_B, Price_B.
Each row of the dataset refers to the same product but the values of the corresponding columns from Dataset A and Dataset B can be slightly different. There can be typos or missing value in each column.
As an example, check out the following couple of rows:
Title_A | Product_Type_A | Brand_A | Price_A | Title_B | Product_Type_B | Brand_B | Price_B
Levis Men 505 Regular | Jeans | Levis | 55 | Levs Men 505 | Jeans | Levis | 56
Toshiba C350 55 in 4k | Smart TV | Toshiba | 350 | Toshiba C350 4k Fire TV | Smart TV | Toshiba Inc | 370
Nike Air Max 90 | Sneakers | Nike | 120 | Nike Air Max 90 | Shoes | Nikes | 120
Sony WH-1000XM4 | Headphones | Sony | 275 | Sony WH-1000XM4 | | Sony | 275 |
Make sure that |Price_A - Price_B| *100/Price_A <= 10
Output the dataset as a table with 59 rows which can be exported to Excel
The above prompt generates the dataset with links. The number of rows can be modified to generate a dataset with a different number of links.
To generate more records for each individual dataset (dataset A or dataset B) the following two prompts were used.
Prompt 2: to generate more records for dataset A
Generate 20 more distinct products for the above dataset. But this time, I only need the information about dataset A. The dataset should have the following columns: Title_A, Product_Type_A, Brand_A, Price_A
Prompt 3: to generate more records for dataset B
Now generate 60 more distinct products for the above dataset. But this time, I only need the information about dataset B. The dataset should have the following columns: Title_B, Product_Type_B, Brand_B, Price_B. Don't just get me electronic products. Instead, try to get a variety of different product types e.g., clothing, furniture, auto, home improvement, household essentials, etc.
Record Linkage
Our goal is to identify the overlapping records between files A and B using the Fellegi-Sunter (FS) model. We implement the FS model using the splink package [5] in Python.
To compare the product title, product type, and brand, we use the default name comparison function available in the splink package. Specifically, the comparison function has the following 4 comparison levels:
- Exact match
- Damerau-Levenshtein Distance <= 1
- Jaro Winkler similarity >= 0.9
- Jaro Winkler similarity >= 0.8
If a pair of products does not fall into any of the 4 levels, a default Anything Else level is assigned to the pair.
The splink package does not have a function to compare numerical columns. Therefore, for price comparison, we first convert the price into a categorical variable by splitting it up into the following buckets: [<$100, $100–200, $200–300, $300–400, $400–500, $500–600, $600–700, $700–800, $800–900, $900–1000, >=$1000]. Then, we check if the price falls into the same bucket for a pair of records. In other words, we use the Exact Match comparison level.
All the comparisons can be specified through a settings dictionary in the splink package
The parameters of the FS model are estimated using the expectation maximization algorithm. In splink, there are built-in functions for doing this
To evaluate how the FS model performs, we note the number of linked records, precision, recall, and F1 score of the prediction. Precision is defined as the proportion of linked records that are true links. And Recall is defined as the proportion of true links that are correctly identified. The F1 score is equal to 2*Precision*Recall/(Precision + Recall). splink provides a function to generate all these metrics as shown below
The full code to train and evaluate this model is available here: https://github.com/vjoshi345/product-matching-article/blob/main/train_synthetic_fellegi_sunter.py
Results
We run the FS model on all possible pairs of products from the two datasets. Specifically, there are 15,168 product pairs (79 * 192). The splink package has a function to automatically generate predictions (i.e., matching links) for different match probability thresholds. Below we show the confusion matrix for match probability=0.913 (the threshold for which we get the highest F1 score).

Total number of linked records = 82
Precision = 58/82 = 0.707
Recall = 58/59 = 0.983
F1 = (2 * 0.707 * 0.983)/(0.707 + 0.983) = 0.823
Conclusion
The purpose of this article was to show how product matching is a specific instance of the more general Entity Resolution problem. We demonstrated this by utilizing one of the popular models from the ER framework to solve the product matching problem. Since we wanted this to be an introductory article, we created a relatively simple synthetic dataset. In a real-world scenario, the data will be much more complex with dozens of different variables e.g., product description, color, size, etc. For accurate matching, we would need more advanced NLP techniques beyond text distance metrics. For example, we can utilize embeddings derived from Transformer models to semantically match products. This can help us match two products with syntactically different descriptions e.g., two products with Product Type Jeans and Denims respectively.
Further, the number of products for real-world datasets will be in the range of hundreds of millions with potentially hundreds of thousands of links. Such datasets require more efficient methods as well as compute resources for effective product matching.
References
[1]: https://medium.com/walmartglobaltech/product-matching-in-ecommerce-4f19b6aebaca
[2]: https://shopping.google.com/?pli=1
[3] I. Fellegi and A.B. Sunter (1969). A theory for record linkage. Journal of the American Statistical Association
[5]: https://moj-analytical-services.github.io/splink/index.html
Streamlining E-commerce: Leveraging Entity Resolution for Product Matching was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Streamlining E-commerce: Leveraging Entity Resolution for Product Matching