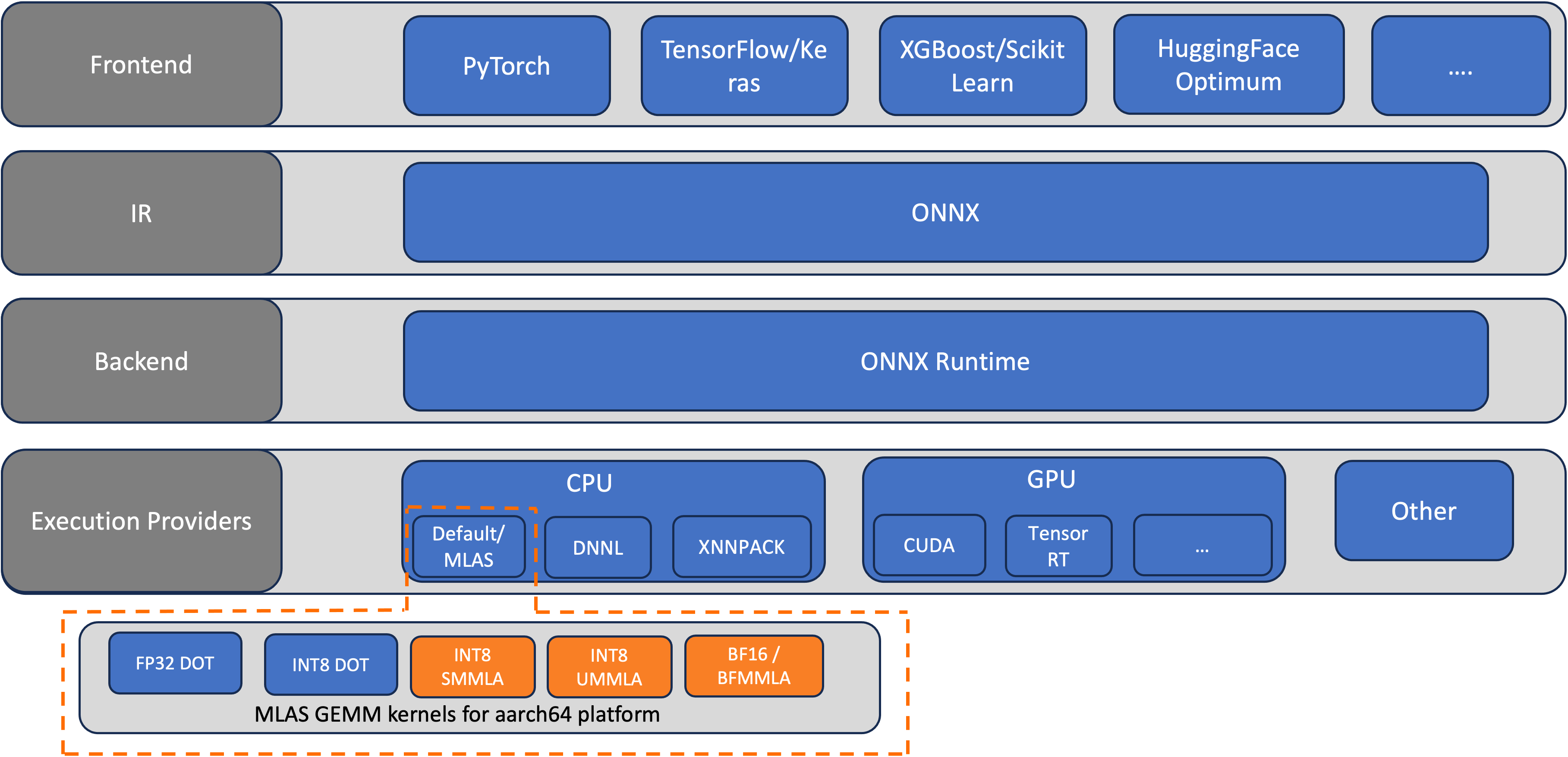

ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. ONNX Runtime is the runtime engine used for model inference and training with ONNX. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix […]
Originally appeared here:
Accelerate NLP inference with ONNX Runtime on AWS Graviton processors
Go Here to Read this Fast! Accelerate NLP inference with ONNX Runtime on AWS Graviton processors