Machine Learning on GCP: from Notebooks to Pipelines
Notebooks are not enough for ML at scale

All images, unless otherwise noted, are by the author
Advocating for AI
There is a misunderstanding (not to say fantasy) which keeps coming back in companies whenever it comes to AI and Machine Learning. People often misjudge the complexity and the skills needed to bring Machine Learning projects to production, either because they do not understand the job, or (even worse) because they think they understand it, whereas they don’t.
Their first reaction when discovering AI might be something like “AI is actually pretty simple, I just need a Jupyter Notebook, copy paste code from here and there — or ask Copilot — and boom. No need to hire Data Scientists after all…” And the story always end badly, with bitterness, disappointment and a feeling that AI is a scam: difficulty to move to production, data drift, bugs, unwanted behavior.
So let’s write it down once and for all: AI/Machine Learning/any data-related job, is a real job, not a hobby. It requires skills, craftsmanship, and tools. If you think you can do ML in production with notebooks, you are wrong.
This article aims at showing, with a simple example, all the effort, skills and tools, it takes to move from a notebook to a real pipeline in production. Because ML in production is, mostly, about being able to automate the run of your code on a regular basis, with automation and monitoring.
And for those who are looking for an end-to-end “notebook to vertex pipelines” tutorial, you might find this helpful.
A simple use case
Let’s imagine you are a Data Scientist working at an e-commerce company. Your company is selling clothes online, and the marketing team asks for your help: they are preparing a special offer for specific products, and they would like to efficiently target customers by tailoring email content that will be pushed to them to maximize conversion. Your job is therefore simple: each customer should be assigned a score which represents the probability he/she purchases a product from the special offer.
The special offer will specifically target those brands, meaning that the marketing team wants to know which customers will buy their next product from the below brands:
Allegra K, Calvin Klein, Carhartt, Hanes, Volcom, Nautica, Quiksilver, Diesel, Dockers, Hurley
We will, for this article, use a publicly available dataset from Google, the `thelook_ecommerce` dataset. It contains fake data with transactions, customer data, product data, everything we would have at our disposal when working at an online fashion retailer.
To follow this notebook, you will need access to Google Cloud Platform, but the logic can be replicated to other Cloud providers or third-parties like Neptune, MLFlow, etc.
As a respectable Data Scientist, you start by creating a notebook which will help us in exploring the data.
We first import libraries which we will use during this article:
import catboost as cb
import pandas as pd
import sklearn as sk
import numpy as np
import datetime as dt
from dataclasses import dataclass
from sklearn.model_selection import train_test_split
from google.cloud import bigquery
%load_ext watermark
%watermark --packages catboost,pandas,sklearn,numpy,google.cloud.bigquery
catboost : 1.0.4
pandas : 1.4.2
numpy : 1.22.4
google.cloud.bigquery: 3.2.0
Before Production
Getting and preparing the data
We will then load the data from BigQuery using the Python Client. Be sure to use your own project id:
query = """
SELECT
transactions.user_id,
products.brand,
products.category,
products.department,
products.retail_price,
users.gender,
users.age,
users.created_at,
users.country,
users.city,
transactions.created_at
FROM `bigquery-public-data.thelook_ecommerce.order_items` as transactions
LEFT JOIN `bigquery-public-data.thelook_ecommerce.users` as users
ON transactions.user_id = users.id
LEFT JOIN `bigquery-public-data.thelook_ecommerce.products` as products
ON transactions.product_id = products.id
WHERE status <> 'Cancelled'
"""
client = bigquery.Client()
df = client.query(query).to_dataframe()
You should see something like that when looking at the dataframe:
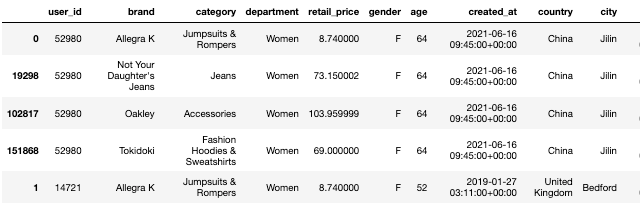
These represent the transactions / purchases made by the customers, enriched with customer and product information.
Given our objective is to predict which brand customers will buy in their next purchase, we will proceed as follows:
- Group purchases chronologically for each customer
- If a customer has N purchases, we consider the Nth purchase as the target, and the N-1 as our features.
- We therefore exclude customers with only 1 purchase
Let’s put that into code:
# Compute recurrent customers
recurrent_customers = df.groupby('user_id')['created_at'].count().to_frame("n_purchases")
# Merge with dataset and filter those with more than 1 purchase
df = df.merge(recurrent_customers, left_on='user_id', right_index=True, how='inner')
df = df.query('n_purchases > 1')
# Fill missing values
df.fillna('NA', inplace=True)
target_brands = [
'Allegra K',
'Calvin Klein',
'Carhartt',
'Hanes',
'Volcom',
'Nautica',
'Quiksilver',
'Diesel',
'Dockers',
'Hurley'
]
aggregation_columns = ['brand', 'department', 'category']
# Group purchases by user chronologically
df_agg = (df.sort_values('created_at')
.groupby(['user_id', 'gender', 'country', 'city', 'age'], as_index=False)[['brand', 'department', 'category']]
.agg({k: ";".join for k in ['brand', 'department', 'category']})
)
# Create the target
df_agg['last_purchase_brand'] = df_agg['brand'].apply(lambda x: x.split(";")[-1])
df_agg['target'] = df_agg['last_purchase_brand'].isin(target_brands)*1
df_agg['age'] = df_agg['age'].astype(float)
# Remove last item of sequence features to avoid target leakage :
for col in aggregation_columns:
df_agg[col] = df_agg[col].apply(lambda x: ";".join(x.split(";")[:-1]))
Notice how we removed the last item in the sequence features: this is very important as otherwise we get what we call a “data leakeage”: the target is part of the features, the model is given the answer when learning.
We now get this new df_agg dataframe:


Comparing with the original dataframe, we see that user_id 2 has indeed purchased IZOD, Parke & Ronen, and finally Orvis which is not in the target brands.
Splitting into train, validation and test
As a seasoned Data Scientist, you will now split your data into different sets, as you obviously know that all three are required to perform some rigorous Machine Learning. (Cross-validation is out of the scope for today folks, let’s keep it simple.)
One key thing when splitting the data is to use the not-so-well-known stratify parameter from the scikit-learn train_test_split() method. The reason for that is because of class-imbalance: if the target distribution (% of 0 and 1 in our case) differs between training and testing, we might get frustrated with poor results when deploying the model. ML 101 kids: keep you data distributions as similar as possible between training data and test data.
# Remove unecessary features
df_agg.drop('last_purchase_category', axis=1, inplace=True)
df_agg.drop('last_purchase_brand', axis=1, inplace=True)
df_agg.drop('user_id', axis=1, inplace=True)
# Split the data into train and eval
df_train, df_val = train_test_split(df_agg, stratify=df_agg['target'], test_size=0.2)
print(f"{len(df_train)} samples in train")
df_train, df_val = train_test_split(df_agg, stratify=df_agg['target'], test_size=0.2)
print(f"{len(df_train)} samples in train")
# 30950 samples in train
df_val, df_test = train_test_split(df_val, stratify=df_val['target'], test_size=0.5)
print(f"{len(df_val)} samples in val")
print(f"{len(df_test)} samples in test")
# 3869 samples in train
# 3869 samples in test
Now this is done, we will gracefully split our dataset between features and targets:
X_train, y_train = df_train.iloc[:, :-1], df_train['target']
X_val, y_val = df_val.iloc[:, :-1], df_val['target']
X_test, y_test = df_test.iloc[:, :-1], df_test['target']
Among the feature are different types. We usually separate those between:
- numerical features: they are continuous, and reflect a measurable, or ordered, quantity.
- categorical features: they are usually discrete, and are often represented as strings (ex: a country, a color, etc…)
- text features: they are usually sequences of words.
Of course there can be more like image, video, audio, etc.
The model: introducing CatBoost
For our classification problem (you already knew we were in a classification framework, didn’t you?), we will use a simple yet very powerful library: CatBoost. It is built and maintained by Yandex, and provides a high-level API to easily play with boosted trees. It is close to XGBoost, though it does not work exactly the same under the hood.
CatBoost offers a nice wrapper to deal with features from different kinds. In our case, some features can be considered as “text” as they are the concatenation of words, such as “Calvin Klein;BCBGeneration;Hanes”. Dealing with this type of features can sometimes be painful as you need to handle them with text splitters, tokenizers, lemmatizers, etc. Hopefully, CatBoost can manage everything for us!
# Define features
features = {
'numerical': ['retail_price', 'age'],
'static': ['gender', 'country', 'city'],
'dynamic': ['brand', 'department', 'category']
}
# Build CatBoost "pools", which are datasets
train_pool = cb.Pool(
X_train,
y_train,
cat_features=features.get("static"),
text_features=features.get("dynamic"),
)
validation_pool = cb.Pool(
X_val,
y_val,
cat_features=features.get("static"),
text_features=features.get("dynamic"),
)
# Specify text processing options to handle our text features
text_processing_options = {
"tokenizers": [
{"tokenizer_id": "SemiColon", "delimiter": ";", "lowercasing": "false"}
],
"dictionaries": [{"dictionary_id": "Word", "gram_order": "1"}],
"feature_processing": {
"default": [
{
"dictionaries_names": ["Word"],
"feature_calcers": ["BoW"],
"tokenizers_names": ["SemiColon"],
}
],
},
}
We are now ready to define and train our model. Going through each and every parameter is out of today’s scope as the number of parameters is quite impressive, but feel free to check the API yourself.
And for brevity, we will not perform hyperparameter tuning today, but this is obviously a large part of the Data Scientist’s job!
# Train the model
model = cb.CatBoostClassifier(
iterations=200,
loss_function="Logloss",
random_state=42,
verbose=1,
auto_class_weights="SqrtBalanced",
use_best_model=True,
text_processing=text_processing_options,
eval_metric='AUC'
)
model.fit(
train_pool,
eval_set=validation_pool,
verbose=10
)
And voila, our model is trained. Are we done?
No. We need to check that our model’s performance between training and testing is consistent. A huge gap between training and testing means our model is overfitting (i.e. “learning the training data by heart and not good at predicting unseen data”).
For our model evaluation, we will use the ROC-AUC score. Not deep-diving on this one either, but from my own experience this is a generally quite robust metric and way better than accuracy.
A quick side note on accuracy: I usually do not recommend using this as your evaluation metric. Think of an imbalanced dataset where you have 1% of positives and 99% of negatives. What would be the accuracy of a very dumb model predicting 0 all the time? 99%. So accuracy not helpful here.
from sklearn.metrics import roc_auc_score
print(f"ROC-AUC for train set : {roc_auc_score(y_true=y_train, y_score=model.predict(X_train)):.2f}")
print(f"ROC-AUC for validation set : {roc_auc_score(y_true=y_val, y_score=model.predict(X_val)):.2f}")
print(f"ROC-AUC for test set : {roc_auc_score(y_true=y_test, y_score=model.predict(X_test)):.2f}")
ROC-AUC for train set : 0.612
ROC-AUC for validation set : 0.586
ROC-AUC for test set : 0.622
To be honest, 0.62 AUC is not great at all and a little bit disappointing for the expert Data Scientist you are. Our model definitely needs a little bit of parameter tuning here, and maybe we should also perform feature engineering more seriously.
But it is already better than random predictions (phew):
# random predictions
print(f"ROC-AUC for train set : {roc_auc_score(y_true=y_train, y_score=np.random.rand(len(y_train))):.3f}")
print(f"ROC-AUC for validation set : {roc_auc_score(y_true=y_val, y_score=np.random.rand(len(y_val))):.3f}")
print(f"ROC-AUC for test set : {roc_auc_score(y_true=y_test, y_score=np.random.rand(len(y_test))):.3f}")
ROC-AUC for train set : 0.501
ROC-AUC for validation set : 0.499
ROC-AUC for test set : 0.501
Let’s assume we are satisfied for now with our model and our notebook. This is where amateur Data Scientists would stop. So how do we make the next step and become production ready?
Moving to Production
Meet Docker
Docker is a set of platform as a service products that use OS-level virtualization to deliver software in packages called containers. This being said, think of Docker as code which can run everywhere, and allowing you to avoid the “works on your machine but not on mine” situation.
Why use Docker? Because among cool things such as being able to share your code, keep versions of it and ensure its easy deployment everywhere, it can also be used to build pipelines. Bear with me and you will understand as we go.
The first step to building a containerized application is to refactor and clean up our messy notebook. We are going to define 2 files, preprocess.py and train.py for our very simple example, and put them in a src directory. We will also include our requirements.txt file with everything in it.
# src/preprocess.py
from sklearn.model_selection import train_test_split
from google.cloud import bigquery
def create_dataset_from_bq():
query = """
SELECT
transactions.user_id,
products.brand,
products.category,
products.department,
products.retail_price,
users.gender,
users.age,
users.created_at,
users.country,
users.city,
transactions.created_at
FROM `bigquery-public-data.thelook_ecommerce.order_items` as transactions
LEFT JOIN `bigquery-public-data.thelook_ecommerce.users` as users
ON transactions.user_id = users.id
LEFT JOIN `bigquery-public-data.thelook_ecommerce.products` as products
ON transactions.product_id = products.id
WHERE status <> 'Cancelled'
"""
client = bigquery.Client(project='<replace_with_your_project_id>')
df = client.query(query).to_dataframe()
print(f"{len(df)} rows loaded.")
# Compute recurrent customers
recurrent_customers = df.groupby('user_id')['created_at'].count().to_frame("n_purchases")
# Merge with dataset and filter those with more than 1 purchase
df = df.merge(recurrent_customers, left_on='user_id', right_index=True, how='inner')
df = df.query('n_purchases > 1')
# Fill missing value
df.fillna('NA', inplace=True)
target_brands = [
'Allegra K',
'Calvin Klein',
'Carhartt',
'Hanes',
'Volcom',
'Nautica',
'Quiksilver',
'Diesel',
'Dockers',
'Hurley'
]
aggregation_columns = ['brand', 'department', 'category']
# Group purchases by user chronologically
df_agg = (df.sort_values('created_at')
.groupby(['user_id', 'gender', 'country', 'city', 'age'], as_index=False)[['brand', 'department', 'category']]
.agg({k: ";".join for k in ['brand', 'department', 'category']})
)
# Create the target
df_agg['last_purchase_brand'] = df_agg['brand'].apply(lambda x: x.split(";")[-1])
df_agg['target'] = df_agg['last_purchase_brand'].isin(target_brands)*1
df_agg['age'] = df_agg['age'].astype(float)
# Remove last item of sequence features to avoid target leakage :
for col in aggregation_columns:
df_agg[col] = df_agg[col].apply(lambda x: ";".join(x.split(";")[:-1]))
df_agg.drop('last_purchase_category', axis=1, inplace=True)
df_agg.drop('last_purchase_brand', axis=1, inplace=True)
df_agg.drop('user_id', axis=1, inplace=True)
return df_agg
def make_data_splits(df_agg):
df_train, df_val = train_test_split(df_agg, stratify=df_agg['target'], test_size=0.2)
print(f"{len(df_train)} samples in train")
df_val, df_test = train_test_split(df_val, stratify=df_val['target'], test_size=0.5)
print(f"{len(df_val)} samples in val")
print(f"{len(df_test)} samples in test")
return df_train, df_val, df_test
# src/train.py
import catboost as cb
import pandas as pd
import sklearn as sk
import numpy as np
import argparse
from sklearn.metrics import roc_auc_score
def train_and_evaluate(
train_path: str,
validation_path: str,
test_path: str
):
df_train = pd.read_csv(train_path)
df_val = pd.read_csv(validation_path)
df_test = pd.read_csv(test_path)
df_train.fillna('NA', inplace=True)
df_val.fillna('NA', inplace=True)
df_test.fillna('NA', inplace=True)
X_train, y_train = df_train.iloc[:, :-1], df_train['target']
X_val, y_val = df_val.iloc[:, :-1], df_val['target']
X_test, y_test = df_test.iloc[:, :-1], df_test['target']
features = {
'numerical': ['retail_price', 'age'],
'static': ['gender', 'country', 'city'],
'dynamic': ['brand', 'department', 'category']
}
train_pool = cb.Pool(
X_train,
y_train,
cat_features=features.get("static"),
text_features=features.get("dynamic"),
)
validation_pool = cb.Pool(
X_val,
y_val,
cat_features=features.get("static"),
text_features=features.get("dynamic"),
)
test_pool = cb.Pool(
X_test,
y_test,
cat_features=features.get("static"),
text_features=features.get("dynamic"),
)
params = CatBoostParams()
text_processing_options = {
"tokenizers": [
{"tokenizer_id": "SemiColon", "delimiter": ";", "lowercasing": "false"}
],
"dictionaries": [{"dictionary_id": "Word", "gram_order": "1"}],
"feature_processing": {
"default": [
{
"dictionaries_names": ["Word"],
"feature_calcers": ["BoW"],
"tokenizers_names": ["SemiColon"],
}
],
},
}
# Train the model
model = cb.CatBoostClassifier(
iterations=200,
loss_function="Logloss",
random_state=42,
verbose=1,
auto_class_weights="SqrtBalanced",
use_best_model=True,
text_processing=text_processing_options,
eval_metric='AUC'
)
model.fit(
train_pool,
eval_set=validation_pool,
verbose=10
)
roc_train = roc_auc_score(y_true=y_train, y_score=model.predict(X_train))
roc_eval = roc_auc_score(y_true=y_val, y_score=model.predict(X_val))
roc_test = roc_auc_score(y_true=y_test, y_score=model.predict(X_test))
print(f"ROC-AUC for train set : {roc_train:.2f}")
print(f"ROC-AUC for validation set : {roc_eval:.2f}")
print(f"ROC-AUC for test. set : {roc_test:.2f}")
return {"model": model, "scores": {"train": roc_train, "eval": roc_eval, "test": roc_test}}
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--train-path", type=str)
parser.add_argument("--validation-path", type=str)
parser.add_argument("--test-path", type=str)
parser.add_argument("--output-dir", type=str)
args, _ = parser.parse_known_args()
_ = train_and_evaluate(
args.train_path,
args.validation_path,
args.test_path)
Much cleaner now. You can actually launch your script from the command line now!
$ python train.py --train-path xxx --validation-path yyy etc.
We are now ready to build our Docker image. For that we need to write a Dockerfile at the root of the project:
# Dockerfile
FROM python:3.8-slim
WORKDIR /
COPY requirements.txt /requirements.txt
COPY src /src
RUN pip install --upgrade pip && pip install -r requirements.txt
ENTRYPOINT [ "bash" ]
This will take our requirements, copy the src folder and its contents, and install the requirements with pip when the image will build.
To build and deploy this image to a container registry, we can use the Google Cloud SDK and the gcloud commands:
PROJECT_ID = ...
IMAGE_NAME=f'thelook_training_demo'
IMAGE_TAG='latest'
IMAGE_URI='eu.gcr.io/{}/{}:{}'.format(PROJECT_ID, IMAGE_NAME, IMAGE_TAG)
!gcloud builds submit --tag $IMAGE_URI .
If everything goes well, you should see something like that:

Vertex Pipelines, the move to production
Docker images are the first step to doing some serious Machine Learning in production. The next step is building what we call “pipelines”. Pipelines are a series of operations orchestrated by a framework called Kubeflow. Kubeflow can run on Vertex AI on Google Cloud.
The reasons for preferring pipelines over notebooks in production can be debatable, but I will give you three based on my experience:
- Monitoring and reproducibility: each pipeline is stored with its artefacts (datasets, models, metrics), meaning you can compare runs, re-run them, and audit them. Each time you re-run a notebook, you lose the history (or you have to manage artefacts yourself as weel as the logs. Good luck.)
- Costs: Running a notebook implies having a machine on which it runs. — This machine has a cost, and for large models or huge datasets you will need virtual machines with heavy specs.
— You have to remember to switch it off when you don’t use it.
— Or you may simply crash your local machine if you choose not to use a virtual machine and have other applications running.
— Vertex AI pipelines is a serverless service, meaning you do not have to manage the underlying infrastructure, and only pay for what you use, meaning the execution time. - Scalability: Good luck when running dozens of experiments on your local laptop simultaneously. You will roll back to using a VM, and scale that VM, and re-read the bullet point above.
The last reason to prefer pipelines over notebooks is subjective and highly debatable as well, but in my opinion notebooks are simply not designed for running workloads on a schedule. They are great though for exploration.
Use a cron job with a Docker image at least, or pipelines if you want to do things the right way, but never, ever, run a notebook in production.
Without further ado, let’s write the components of our pipeline:
# IMPORT REQUIRED LIBRARIES
from kfp.v2 import dsl
from kfp.v2.dsl import (Artifact,
Dataset,
Input,
Model,
Output,
Metrics,
Markdown,
HTML,
component,
OutputPath,
InputPath)
from kfp.v2 import compiler
from google.cloud.aiplatform import pipeline_jobs
%watermark --packages kfp,google.cloud.aiplatform
kfp : 2.7.0
google.cloud.aiplatform: 1.50.0
The first component will download the data from Bigquery and store it as a CSV file.
The BASE_IMAGE we use is the image we build previously! We can use it to import modules and functions we defined in our Docker image src folder:
@component(
base_image=BASE_IMAGE,
output_component_file="get_data.yaml"
)
def create_dataset_from_bq(
output_dir: Output[Dataset],
):
from src.preprocess import create_dataset_from_bq
df = create_dataset_from_bq()
df.to_csv(output_dir.path, index=False)
Next step: split data
@component(
base_image=BASE_IMAGE,
output_component_file="train_test_split.yaml",
)
def make_data_splits(
dataset_full: Input[Dataset],
dataset_train: Output[Dataset],
dataset_val: Output[Dataset],
dataset_test: Output[Dataset]):
import pandas as pd
from src.preprocess import make_data_splits
df_agg = pd.read_csv(dataset_full.path)
df_agg.fillna('NA', inplace=True)
df_train, df_val, df_test = make_data_splits(df_agg)
print(f"{len(df_train)} samples in train")
print(f"{len(df_val)} samples in train")
print(f"{len(df_test)} samples in test")
df_train.to_csv(dataset_train.path, index=False)
df_val.to_csv(dataset_val.path, index=False)
df_test.to_csv(dataset_test.path, index=False)
Next step: model training. We will save the model scores to display them in the next step:
@component(
base_image=BASE_IMAGE,
output_component_file="train_model.yaml",
)
def train_model(
dataset_train: Input[Dataset],
dataset_val: Input[Dataset],
dataset_test: Input[Dataset],
model: Output[Model]
):
import json
from src.train import train_and_evaluate
outputs = train_and_evaluate(
dataset_train.path,
dataset_val.path,
dataset_test.path
)
cb_model = outputs['model']
scores = outputs['scores']
model.metadata["framework"] = "catboost"
# Save the model as an artifact
with open(model.path, 'w') as f:
json.dump(scores, f)
The last step is computing the metrics (which are actually computed in the training of the model). It is merely necessary but is nice to show you how easy it is to build lightweight components. Notice how in this case we don’t build the component from the BASE_IMAGE (which can be quite large sometimes), but only build a lightweight image with necessary components:
@component(
base_image="python:3.9",
output_component_file="compute_metrics.yaml",
)
def compute_metrics(
model: Input[Model],
train_metric: Output[Metrics],
val_metric: Output[Metrics],
test_metric: Output[Metrics]
):
import json
file_name = model.path
with open(file_name, 'r') as file:
model_metrics = json.load(file)
train_metric.log_metric('train_auc', model_metrics['train'])
val_metric.log_metric('val_auc', model_metrics['eval'])
test_metric.log_metric('test_auc', model_metrics['test'])
There are usually other steps which we can include, like if we want to deploy our model as an API endpoint, but this is more advanced-level and requires crafting another Docker image for the serving of the model. To be covered next time.
Let’s now glue the components together:
# USE TIMESTAMP TO DEFINE UNIQUE PIPELINE NAMES
TIMESTAMP = dt.datetime.now().strftime("%Y%m%d%H%M%S")
DISPLAY_NAME = 'pipeline-thelook-demo-{}'.format(TIMESTAMP)
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
# Define the pipeline. Notice how steps reuse outputs from previous steps
@dsl.pipeline(
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline. Use to determine the pipeline Context.
name="pipeline-demo"
)
def pipeline(
project: str = PROJECT_ID,
region: str = REGION,
display_name: str = DISPLAY_NAME
):
load_data_op = create_dataset_from_bq()
train_test_split_op = make_data_splits(
dataset_full=load_data_op.outputs["output_dir"]
)
train_model_op = train_model(
dataset_train=train_test_split_op.outputs["dataset_train"],
dataset_val=train_test_split_op.outputs["dataset_val"],
dataset_test=train_test_split_op.outputs["dataset_test"],
)
model_evaluation_op = compute_metrics(
model=train_model_op.outputs["model"]
)
# Compile the pipeline as JSON
compiler.Compiler().compile(
pipeline_func=pipeline,
package_path='thelook_pipeline.json'
)
# Start the pipeline
start_pipeline = pipeline_jobs.PipelineJob(
display_name="thelook-demo-pipeline",
template_path="thelook_pipeline.json",
enable_caching=False,
location=REGION,
project=PROJECT_ID
)
# Run the pipeline
start_pipeline.run(service_account=<your_service_account_here>)
If everything works well, you will now see your pipeline in the Vertex UI:
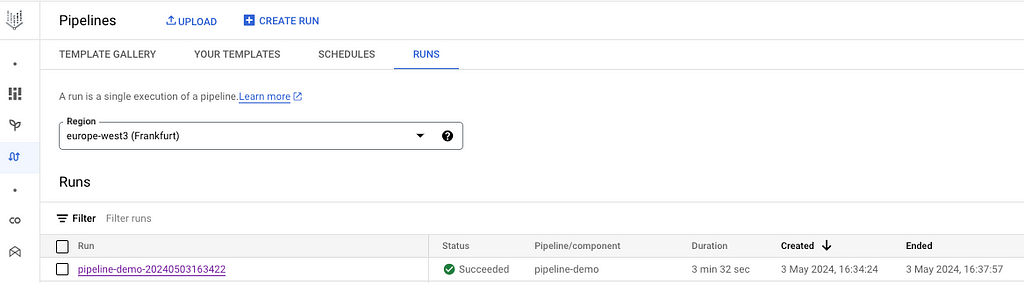
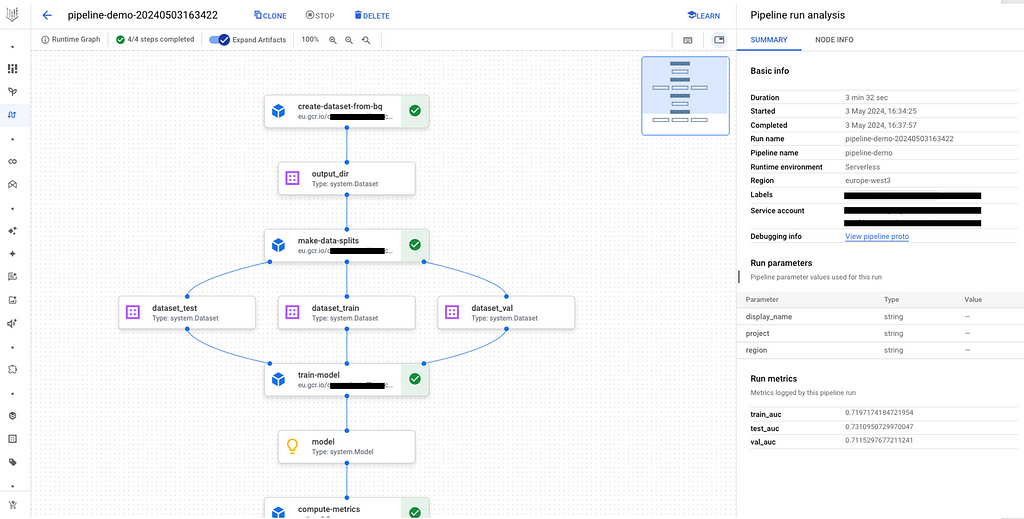
You can click on it and see the different steps:
Conclusion
Data Science, despite all the no-code/low-code enthusiasts telling you you don’t need to be a developer to do Machine Learning, is a real job. Like every job, it requires skills, concepts and tools which go beyond notebooks.
And for those who aspire to become Data Scientists, here is the reality of the job.
Happy coding.
Machine Learning on GCP : from dev to prod with Vertex AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Machine Learning on GCP : from dev to prod with Vertex AI
Go Here to Read this Fast! Machine Learning on GCP : from dev to prod with Vertex AI