

An open-source library for building knowledge graphs from text corpus using open-source LLMs like Llama 3 and Mixtral.
In this article, I will share a Python library — the Graph Maker — that can create a Knowledge Graph from a corpus of text as per a given Ontology. The Graph Maker uses open-source LLMs like Llama3, Mistral, Mixtral or Gemma to extract the KG.
We will go through the basics of ‘Why’ and ‘What’ of the Graph Maker, a brief recap of the previous article, and how the current approach addresses some of its challenges. I will share the GitHub repository at the end of this article.
Introduction
This article is a sequel to the article I wrote a few months ago about how to convert any text into a Graph.
How to Convert Any Text Into a Graph of Concepts
The article received an overwhelming response. The GitHub repository shared in the article has more than 180 Forks and more than 900 Stars. The article itself was read by more than 80K readers on the Medium. Recently the article was attributed in the following paper published by Prof Markus J. Buehler at MIT.
This is a fascinating paper that demonstrates the gigantic potential of Knowledge Graphs in the era of AI. It demonstrates how KGs can be used, not only to retrieve knowledge but also to discover new knowledge. Here is one of my favourite excerpts from this paper.
“For instance, we will show how this approach can relate seemingly disparate concepts such as Beethoven’s 9th symphony with bio-inspired materials science”
These developments are a big reaffirmation of the ideas I presented in the previous article and encouraged me to develop the ideas further.
I also received numerous feedback from fellow techies about the challenges they encountered while using the repository, and suggestions for improving the idea. I incorporated some of these suggestions into a new Python package I share here.
Before we discuss the working of the package — The Graph Maker — let us discuss the ‘Why’ and the ‘What’ of it.
A Brief Recap
We should probably start with ‘Why Graphs’. However, We discussed this briefly in my previous article. Feel free to hop onto that article for a refresher. However, let us briefly discuss the key concepts that are relevant to our current discussion here.
TL;DR this section if you are already well versed in the lore of Knowledge Graphs.
Here is an illustration that sums up the idea of Knowledge Graphs neatly.
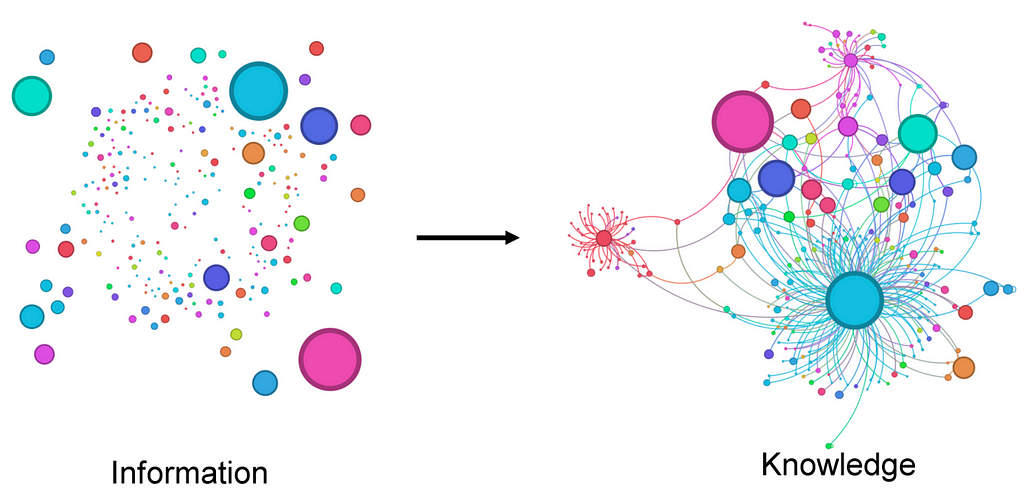
To create a KG, we need two pieces of information.
- Knowledge Base: This can be a corpus of text, a code base, a collection of articles, etc.
- Ontology: The categories of the entities, and the types of their relationships we care about. I am probably oversimplifying the definition of ontology here but it works for our purpose.
Here is a simple ontology
Entities: Person, Place
Relationships:
Person — related to → Person
Person — lives in → Place
Person — visits → Place
Given these two pieces of information, we can build a KG from a text that mentions people and places. However, let’s say our knowledge base is about a clinical study of prescription drugs and their interactions. We might use a different ontology where Compounds, Usage, Effects, Reactions etc may form our ontology.
In the previous article, we discussed How we can extract a Knowledge Graph using an LLM, without supplying it with an ontology. The idea was to let the LLM discover the ontology best suited for the given corpus of text by itself.
Although this approach lacks the rigour of the traditional methods of generating KGs, it has its merits. It can generate KGs with unstructured data more easily than traditional methods. The KGs that it generates are, in some sense, also unstructured. However, they are easier to build and are richer in information. They are well suited for GRAG (Graph Retrieval Augmented Generation) like applications.
Why The Graph Maker?
Let me list a few challenges and observations I received in the feedback for my previous article. It will help us understand the challenges in creating KGs with LLMs. Let us use the Wikipedia summary of the Lord of the Rings books. One cant not love the Lord of the Rings after all!
Meaningful Entities
Given a free run, the entities that the LLM extracts can be too diverse in their categories. It mistakes by marking abstract concepts as entities. For example in the text “Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo”, the LLM may extract “Bilbo Baggins celebrates his birthday” or “Celebrates his birthday” as ‘Action’. But it may be more useful if it extracts “Birthday” as an ‘Event’.
Consistent Entities
It can also mistake marking the same entity differently in different contexts. For example:
‘Sauron’, ‘the Dark Lord Sauron’ and ‘the Dark Lord’ Should not be extracted as different entities. Or if they are extracted as different entities, they should be connected with an equivalence relationship.
Resilience in parsing
The output of the LLMs is, by nature, indeterministic. To extract the KG from a large document, we must split the corpus into smaller text chunks and then generate subgraphs for every chunk. To build a consistent graph, the LLM must output JSON objects as per the given schema consistently for every subgraph. Missing even one may affect the connectivity of the entire graph adversely.
Although LLMs are getting better at responding with well-formatted JSON objects, It is still far from perfect. LLMs with limited context windows may also generate incomplete responses.
Categorisation of the Entities
LLMs can error generously when recognising entities. This is a bigger problem when the context is domain-specific, or when the entities are not named in standard English. NER models can do better at that, but they too are limited to the data they are trained on. Moreover, they can’t understand the relations between the entities.
To coerce an LLM to be consistent with categories is an art in prompt engineering.
Implied relations
Relations can be explicitly mentioned, or implied by the context. For example:
“Bilbo Baggins celebrates his birthday and leaves the Ring to Frodo” implies the relationships:
Bilbo Baggins → Owner → Ring
Bilbo Baggins → heir → Frodo
Frodo → Owner → Ring
Here I think LLMs at some point in time will become better than any traditional method of extracting relationships. But as of now, this is a challenge that needs clever prompt engineering.
The Graph Maker
The graph maker library I share here improves upon the previous approach by travelling halfway between the rigour and the ease — halfway between the structure and the lack of it. It does remarkably better than the previous approach I discussed on most of the above challenges.
As opposed to the previous approach, where the LLM is free to discover the ontology by itself, the graph maker tries to coerce the LLM to use a user-defined ontology.
Here is how it works in 5 easy steps.
1. Define the Ontology of your Graph
The library understands the following schema for the Ontology. Behind the scenes, ontology is a pedantic model.
ontology = Ontology(
# labels of the entities to be extracted. Can be a string or an object, like the following.
labels=[
{"Person": "Person name without any adjectives, Remember a person may be referenced by their name or using a pronoun"},
{"Object": "Do not add the definite article 'the' in the object name"},
{"Event": "Event event involving multiple people. Do not include qualifiers or verbs like gives, leaves, works etc."},
"Place",
"Document",
"Organisation",
"Action",
{"Miscellaneous": "Any important concept can not be categorised with any other given label"},
],
# Relationships that are important for your application.
# These are more like instructions for the LLM to nudge it to focus on specific relationships.
# There is no guarantee that only these relationships will be extracted, but some models do a good job overall at sticking to these relations.
relationships=[
"Relation between any pair of Entities",
],
)
I have tuned the prompts to yield results that are consistent with the given ontology. I think it does a pretty good job at it. However, it is still not 100% accurate. The accuracy depends on the model we choose to generate the graph, the application, the ontology, and the quality of the data.
2. Split the text into chunks.
We can use as large a corpus of text as we want to create large knowledge graphs. However, LLMs have a finite context window right now. So we need to chunk the text appropriately and create the graph one chunk at a time. The chunk size that we should use depends on the model context window. The prompts that are used in this project eat up around 500 tokens. The rest of the context can be divided into input text and output graph. In my experience, smaller chunks of 200 to 500 tokens generate a more detailed graph.
3. Convert these chunks into Documents.
The document is a pedantic model with the following schema
## Pydantic document model
class Document(BaseModel):
text: str
metadata: dict
The metadata we add to the document here is tagged to every relation that is extracted out of the document.
We can add the context of the relation, for example, the page number, chapter, the name of the article, etc. into the metadata. More often than not, Each node pairs have multiple relations with each other across multiple documents. The metadata helps contextualise these relationships.
4. Run the Graph Maker.
The Graph Maker directly takes a list of documents and iterates over each of them to create one subgraph per document. The final output is the complete graph of all the documents.
Here is a simple example of how to achieve this.
from graph_maker import GraphMaker, Ontology, GroqClient
## -> Select a groq supported model
model = "mixtral-8x7b-32768"
# model ="llama3–8b-8192"
# model = "llama3–70b-8192"
# model="gemma-7b-it" ## This is probably the fastest of all models, though a tad inaccurate.
## -> Initiate the Groq Client.
llm = GroqClient(model=model, temperature=0.1, top_p=0.5)
graph_maker = GraphMaker(ontology=ontology, llm_client=llm, verbose=False)
## -> Create a graph out of a list of Documents.
graph = graph_maker.from_documents(docs)
## result: a list of Edges.
print("Total number of Edges", len(graph))
## 1503
The Graph Makers run each document through the LLM and parse the response to create the complete graph. The final graph is as a list of edges, where every edge is a pydantic model like the following.
class Node(BaseModel):
label: str
name: str
class Edge(BaseModel):
node_1: Node
node_2: Node
relationship: str
metadata: dict = {}
order: Union[int, None] = None
I have tuned the prompts so they generate fairly consistent JSONs now. In case the JSON response fails to parse, the graph maker also tries to manually split the JSON string into multiple strings of edges and then tries to salvage whatever it can.
5. Save to Neo4j
We can save the model to Neo4j either to create an RAG application, run Network algorithms, or maybe just visualise the graph using the Bloom
from graph_maker import Neo4jGraphModel
create_indices = False
neo4j_graph = Neo4jGraphModel(edges=graph, create_indices=create_indices)
neo4j_graph.save()
Each edge of the graph is saved to the database as a transaction. If you are running this code for the first time, then set the `create_indices` to true. This prepares the database by setting up the uniqueness constraints on the nodes.
5.1 Visualise, just for fun if nothing else
In the previous article, we visualised the graph using networkx and pyvis libraries. Here, because we are already saving the graph to Neo4J, we can leverage Bloom directly to visualise the graph.
To avoid repeating ourselves, let us generate a different visualisation from what we did in the previous article.
Let’s say we like to see how the relations between the characters evolve through the book.
We can do this by tracking how the edges are added to the graph incrementally while the graph maker traverses through the book. To enable this, the Edge model has an attribute called ‘order’. This attribute can be used to add a temporal or chronological dimension to the graph.
In our example, the graph maker automatically adds the sequence number in which a particular text chunk occurs in the document list, to every edge it extracts from that chunk. So to see how the relations between the characters evolve, we just have to cross section the graph by the order of the edges.
Here is an animation of these cross-sections.
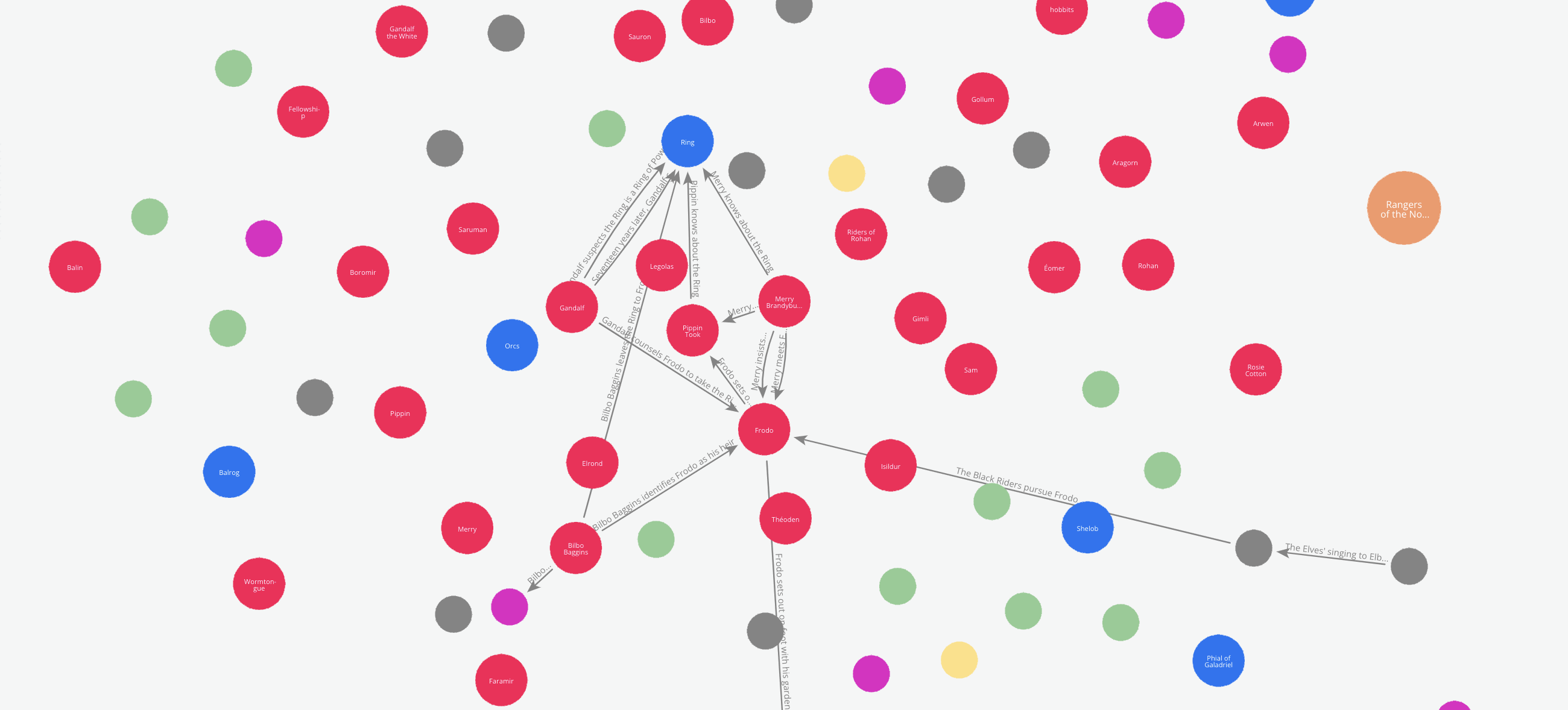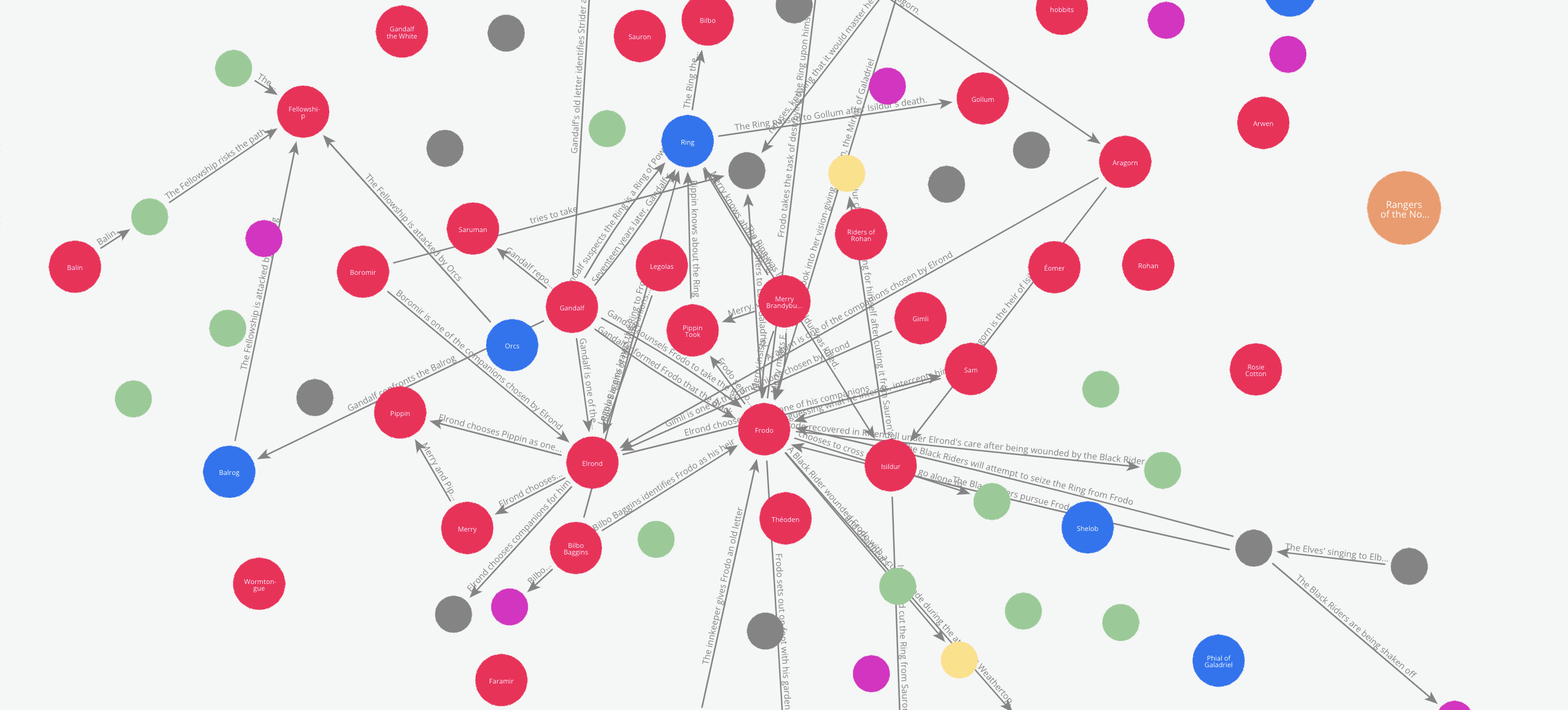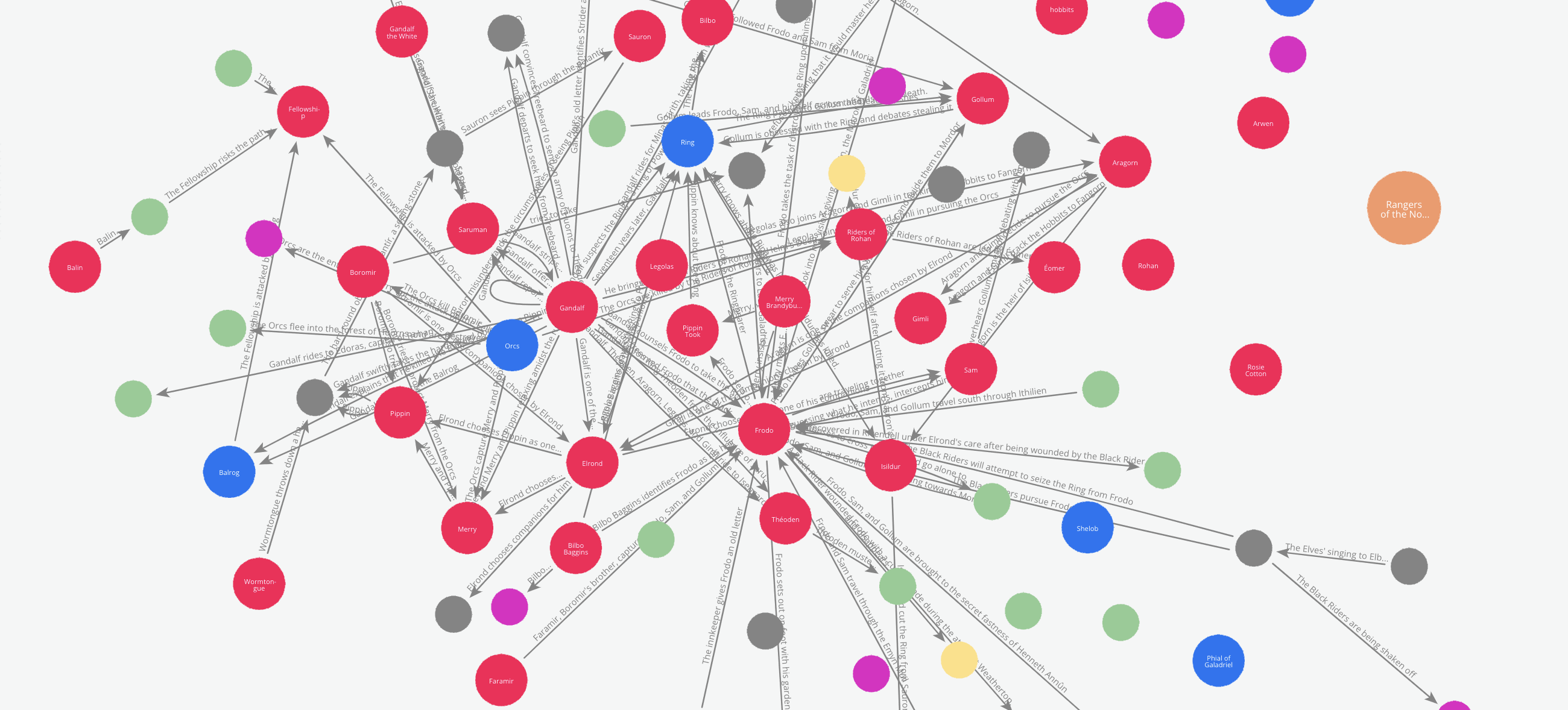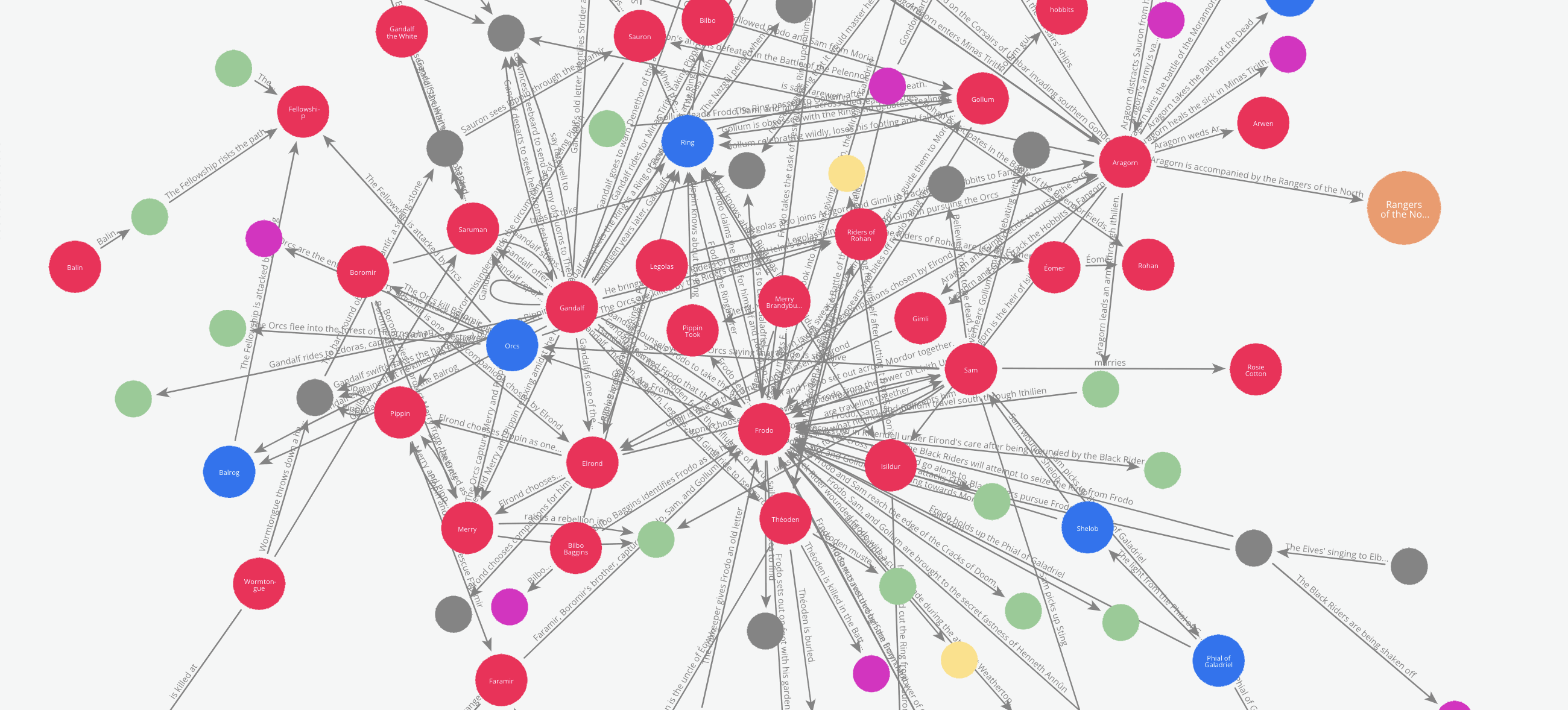
Graph and RAG
The best application of this kind of KG is probably in RAG. There are umpteen articles on Medium on how to augment your RAG applications with Graphs.
Essentially Graphs offer a plethora of different ways to retrieve knowledge. Depending on how we design the Graph and our application, some of these techniques can be more powerful than simple semantic search.
At the very basic, we can add embedding vectors into our nodes and relationships, and run a semantic search against the vector index for retrieval. However, I feel the real power of the Graphs for RAG applications is when we mix Cypher queries and Network algorithms with Semantic Search.
I have been exploring some of these techniques myself. I am hoping to write about them in my next article.
The Code
Here is the GitHub Repository. Please feel free to take it for a spin. I have also included an example Python notebook in the repository that can help you get started quickly.
Please note that you will need to add your GROQ credentials in the .env file before you can get started.
Initially, I developed this codebase for a few of my pet projects. I feel it can be helpful for many more applications. If you use this library for your applications, please share it with me. I would love to learn about your use cases.
Also if you feel you can contribute to this open source project, please do so and make it your own.
I hope you find the graph maker useful. Thanks for reading.
I am a learner of architecture (not the buildings… the tech kind). In the past, I have worked with Semiconductor modelling, Digital circuit design, Electronic Interface modelling, and the Internet of Things.
Currently, Data and Consumer Analytics @Walmart Keeps me busy.
Thanks
Text to Knowledge Graph Made Easy with Graph Maker was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Text to Knowledge Graph Made Easy with Graph Maker
Go Here to Read this Fast! Text to Knowledge Graph Made Easy with Graph Maker