Top 3 lessons learned: the problem, the size, and the data

This blog post is an updated version of part of a conference talk I gave on GOTO Amsterdam last year. The talk is also available to watch online.
As a Machine Learning Product Manager, I am fascinated by the intersection of Machine Learning and Product Management, particularly when it comes to creating solutions that provide value and positive impact on the product, company, and users. However, managing to provide this value and positive impact is not an easy job. One of the main reasons for this complexity is the fact that, in Machine Learning initiatives developed for digital products, two sources of uncertainty intersect.
From a Product Management perspective, the field is uncertain by definition. It is hard to know the impact a solution will have on the product, how users will react to it, and if it will improve product and business metrics or not… Having to work with this uncertainty is what makes Product Managers potentially different from other roles like Project Managers or Product Owners. Product strategy, product discovery, sizing of opportunities, prioritization, agile, and fast experimentation, are some strategies to overcome this uncertainty.
The field of Machine Learning also has a strong link to uncertainty. I always like to say “With predictive models, the goal is to predict things you don’t know are predictable”. This translates into projects that are hard to scope and manage, not being able to commit beforehand to a quality deliverable (good model performance), and many initiatives staying forever as offline POCs. Defining well the problem to solve, initial data analysis and exploration, starting small, and being close to the product and business, are actions that can help tackle the ML uncertainty in projects.
Mitigating this uncertainty risk from the beginning is key to developing initiatives that end up providing value to the product, company, and users. In this blog post, I’ll deep-dive into my top 3 lessons learned when starting ML Product initiatives to manage this uncertainty from the beginning. These learnings are mainly based on my experience, first as a Data Scientist and now as an ML Product Manager, and are helpful to improve the likelihood that an ML solution will reach production and achieve a positive impact. Get ready to explore:
- Start with the problem, and define how predictions will be used from the beginning.
- Start small, and maintain small if you can.
- Data, data, and data: quality, volume, and historic.
Start with the problem (and define how predictions will be used)

I have to admit, I have learned this the hard way. I’ve been involved in projects where, once the model was developed and prediction performance was determined to be “good enough”, the model’s predictions weren’t really usable for any specific use case, or were not useful to help solve any problem.
There are many reasons this can happen, but the ones I’ve found more frequently are:
- Solution-driven initiatives: even before GenAI, Machine Learning, and predictive models were “cool” solutions, and because of that some initiatives started from the ML solution: “let’s try to predict churn” (users or clients who abandon a company), “let’s try to predict user segments”… Current GenAI hype has worsened this trend, putting pressure on companies to integrate GenAI solutions “anywhere” they fit.
- Lack of end-to-end design of the solution: in very few cases, the predictive model is a standalone solution. Usually, though, models and their predictions are integrated into a bigger system to solve a specific use case or enable a new functionality. If this end-to-end solution is not defined from the beginning, it can happen that the model, once already implemented, is found to be useless.
To start an ML initiative on the right foot, it is key to start with the good problem to solve. This is foundational in Product Management, and recurrently reinforced product leaders like Marty Cagan and Melissa Perri. It includes product discovery (through user interviews, market research, data analysis…), and sizing and prioritization of opportunities (by taking into account quantitative and qualitative data).
Once opportunities are identified, the second step is to explore potential solutions for the problem, which should include Machine Learning and GenAI techniques, if they can help solve the problem.
If it is decided to try out a solution that includes the use of predictive models, the third step would be to do an end-to-end definition and design of the solution or system. This way, we can ensure the requirements on how to use the predictions by the system, influence the design and implementation of the predictive piece (what to predict, data to be used, real-time vs batch, technical feasibility checks…).
However, I’d like to add there might be a notable exception in this topic. Starting from GenAI solutions, instead of from the problem, can make sense if this technology ends up truly revolutionizing your sector or the world as we know it. There are a lot of discussions about this, but I’d say it is not clear yet whether that will happen or not. Up until now, we have seen this revolution in very specific sectors (customer support, marketing, design…) and related to people’s efficiency when performing certain tasks (coding, writing, creating…). For most companies though, unless it’s considered R&D work, delivering short/mid-term value still should mean focusing on problems, and considering GenAI just as any other potential solution to them.
Start small (and maintain small if you can)
Tough experiences lead to this learning as well. Those experiences had in common a big ML project defined in a waterfall manner. The kind of project that is set to take 6 months, and follow the ML lifecycle phase by phase.
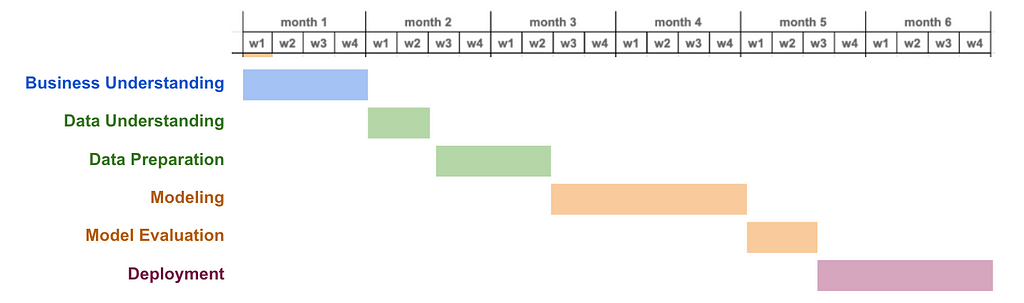
What could go wrong, right? Let me remind you of my previous quote “With predictive models, the goal is to predict things you don’t know are predictable”! In a situation like this, it can happen that you arrive at month 5 of the project, and during the model evaluation realize there is no way the model is able to predict whatever it needs to predict with good enough quality. Or worse, you arrive at month 6, with a super model deployed in production, and realize it is not bringing any value.
This risk combines with the uncertainties related to Product, and makes it mandatory to avoid big, waterfall initiatives if possible. This is not something new or related only to ML initiatives, so there is a lot we can learn from traditional software development, Agile, Lean, and other methodologies and mindsets. By starting small, validating assumptions soon and continuously, and iteratively experimenting and scaling, we can effectively mitigate this risk, adapt to insights and be more cost-efficient.
While these principles are well-established in traditional software and product development, their application to ML initiatives is a bit more complex, as it is not easy to define “small” for an ML model and deployment. There are some approaches, though, that can help start small in ML initiatives.
Rule-based approaches, simplifying a predictive model through a decision tree. This way, “predictions” can be easily implemented as “if-else statements” in production as part of the functionality or system, without the need to deploy a model.
Proofs of Concept (POCs), as a way to validate offline the predictive feasibility of the ML solution, and hint on the potential (or not) of the predictive step once in production.
Minimum Viable Products (MVPs), to first focus on essential features, functionalities, or user segments, and expand the solution only if the value has been proven. For an ML model this can mean, for example, only the most straightforward, priority input features, or predicting only for a segment of data points.
Buy instead of build, to leverage existing ML solutions or platforms to help reduce development time and initial costs. Only when proved valuable and costs increase too much, might be the right time to decide to develop the ML solution in-house.
Using GenAI as an MVP, for some use cases (especially if they involve text or images), genAI APIs can be used as a first approach to solve the prediction step of the system. Tasks like classifying text, sentiment analysis, or image detection, where GenAI models deliver impressive results. When the value is validated and if costs increase too much, the team can decide to build a specific “traditional” ML model in-house.
Note that using GenAI models for image or text classification, while possible and fast, means using a way too big an complex model (expensive, lack of control, hallucinations…) for something that could be predicted with a much simpler and controllable one. A fun analogy would be the idea of delivering a pizza with a truck: it is feasible, but why not just use a bike?
Data, data, and data (quality, volume, historic)

Data is THE recurring problem Data Scientist and ML teams encounter when starting ML initiatives. How many times have you been surprised by data with duplicates, errors, missing batches, weird values… And how different that is from the toy datasets you find in online courses!
It can also happen that the data you need is simply not there: the tracking of the specific event was never implemented, collection and proper ETLs where implemented recently… I have experienced how this translates into having to wait some months to be able to start a project with enough historic and volume data.
All this relates to the adage “Garbage in, garbage out”: ML models are only as good as the data they’re trained on. Many times, solutions have a bigger potential to be improve by improving the data than by improving the models (Data Centric AI). Data needs to be sufficient in volume, historic (data generated during years can bring more value than the same volume generated in just a week), and quality. To achieve that, mature data governance, collection, cleaning, and preprocessing are critical.
From the ethical AI point of view, data is also a primary source of bias and discrimination, so acknowledging that and taking action to mitigate these risks is paramount. Considering data governance principles, privacy and regulatory compliance (e.g. EU’s GDPR), is also key to ensure a responsible use of data (especially when dealing with personal data).
With GenAI models this is pivoting: huge volumes of data are already used to train them. When using these types of models, we might not need volume and quality data for training, but we might need it for fine-tuning (see Good Data = Good GenAI), or to construct the prompts (nurture the context, few-shot learning, Retrieval Augmented Generation… — I explained all these concepts in a previous post!).
It is important to note that by using these models we are losing control of the data used to train them, and we can suffer from the lack of quality or type of data used there: there are many known examples of bias and discrimination in GenAI outputs that can negatively impact our solution. A good example was Bloomberg’s article on how “How ChatGPT is a recruiter’s dream tool — tests show there’s racial bias”. LLM leaderboards testing for biases, or LLMs specifically trained to avoid these biases can be useful in this sense.

Wrapping it up
We started this blogpost discussing what makes ML Product initiatives especially tricky: the combination of the uncertainty related to developing solutions in digital products, with the uncertainty related to trying to predict things through the use of ML models.
It is comforting to know there are actionable steps and strategies available to mitigate these risks. Yet, perhaps the best ones, are related to starting the initiatives off on the right foot! To do so, it can really help to start with the right problem and an end-to-end design of the solution, reduce initial scope, and prioritize data quality, volume, and historical accuracy.
I hope this post was useful and that it will help you challenge how you start working in future new initiatives related to ML Products!
Starting ML Product Initiatives on the Right Foot was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Starting ML Product Initiatives on the Right Foot
Go Here to Read this Fast! Starting ML Product Initiatives on the Right Foot