

Augmenting LLM Apps with a Voice Modality
Many LLMs, particularly those that are open-source, have typically been limited to processing text or, occasionally, text with images (Large Multimodal Models or LMMs). But what if you want to communicate with your LLM using your voice? Thanks to the advancement of powerful speech-to-text open-source technologies in recent years, this becomes achievable.
We will go into the integration of Llama 3 with a speech-to-text model, all within a user-friendly interface. This fusion enables (near) real-time communication with an LLM through speech. Our exploration involves selecting Llama 3 8B as the LLM, using the Whisper speech-to-text model, and the capabilities of NiceGUI — a framework that uses FastAPI on the backend and Vue3 on the frontend, interconnected with socket.io.
After reading this post, you will be able to augment an LLM with a new audio modality. This will allow you to build a full end-to-end workflow and UI that enables you to use your voice to command and prompt an LLM instead of typing. This feature can prove especially beneficial for mobile applications, where typing on a keyboard may not be as user-friendly as on desktops. Additionally, integrating this functionality can enhance the accessibility of your LLM app, making it more inclusive for individuals with disabilities.
Here are the tools and technologies that this project will help you get familiar with:
- Llama 3 LLM
- Whisper STT
- NiceGUI
- (Some) Basic Javascript and Vue3
- The Replicate API
List of Components
In this project, we integrate various components to enable voice interaction with LLMs (Large Language Models). Firstly, LLMs serve as the core of our system, processing inputs and generating outputs based on extensive language knowledge. Next, Whisper, our chosen speech-to-text model, converts spoken input into text, enabling smooth communication with the LLMs. Our frontend, based on Vue3, incorporates custom components within the NiceGUI framework, providing an intuitive user interface for interaction. On the backend, custom code combined with FastAPI forms the base of the app’s functionality. Finally, Replicate.com provides the hosting infrastructure for the ML models, ensuring reliable access and scalability. Together, these components converge to create a basic app for (near) real-time voice interaction with LLMs.
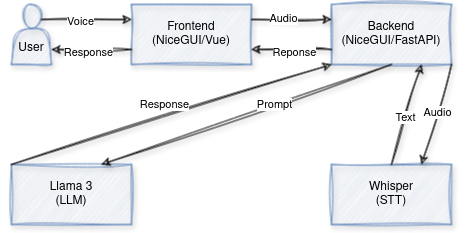
Frontend
NiceGUI does not yet have an audio recording component so I contributed one to their example set: https://github.com/zauberzeug/nicegui/tree/main/examples/audio_recorder that I’ll be reusing here.
In order to create such component, we just need to define a .vue file that defines what we want:
<template>
<div>
<button class="record-button" @mousedown="startRecording" @mouseup="stopRecording">Hold to speak</button>
</div>
</template>
Here, basically, we create a button element where when clicked will call a method startRecording and as soon as the mouse is up will call stopRecording.
For this, we define these main methods:
methods: {
async requestMicrophonePermission() {
try {
this.stream = await navigator.mediaDevices.getUserMedia({ audio: true });
} catch (error) {
console.error('Error accessing microphone:', error);
}
},
async startRecording() {
try {
if (!this.stream) {
await this.requestMicrophonePermission();
}
this.audioChunks = [];
this.mediaRecorder = new MediaRecorder(this.stream);
this.mediaRecorder.addEventListener('dataavailable', event => {
if (event.data.size > 0) {
this.audioChunks.push(event.data);
}
});
this.mediaRecorder.start();
this.isRecording = true;
} catch (error) {
console.error('Error accessing microphone:', error);
}
},
stopRecording() {
if (this.isRecording) {
this.mediaRecorder.addEventListener('stop', () => {
this.isRecording = false;
this.saveBlob();
// this.playRecordedAudio();
});
this.mediaRecorder.stop();
}
}
This code defines three methods: requestMicrophonePermission, startRecording, and stopRecording. The requestMicrophonePermission method asynchronously attempts to access the user’s microphone using navigator.mediaDevices.getUserMedia, handling any errors that may occur. The startRecording method, also asynchronous, initializes recording by setting up a media recorder with the obtained microphone stream, while the stopRecording method stops the recording process and saves the recorded audio.
Once the recording is done, this code will also emit an event named ‘audio_ready’ along with a base64 encoded audio data. Inside the method, a new FileReader object is created. Upon loading the file, the onload event is triggered, extracting the base64 data from the loaded file result. Finally, this base64 data is emitted as part of the ‘audio_ready’ event using $emit() function with the key ‘audioBlobBase64’ containing the base64 data.
emitBlob() {
const reader = new FileReader();
reader.onload = () => {
const base64Data = reader.result.split(',')[1]; // Extracting base64 data from the result
this.$emit('audio_ready', { audioBlobBase64: base64Data });
};
}
This event will be received by the backend along with the base64 data.
The backend
The backend will be basically the glue that ties the user’s input with the ML models hosted in Replicate.
We will be employing two primary models for our project:
- openai/whisper: This Transformer sequence-to-sequence model is dedicated to speech-to-text tasks, proficient in converting audio into text. Trained across various speech processing tasks, such as multilingual speech recognition, speech translation, spoken language identification, and voice activity detection.
- meta/meta-llama-3-8b-instruct: The Llama 3 family, including this 8 billion-parameter variant, is an LLM family created by Meta. These pretrained and instruction-tuned generative text models are specifically optimized for dialogue use cases.
For the first one, we define a simple function that takes as input the base64 audio and calls the replicate api:
def transcribe_audio(base64_audio):
audio_bytes = base64.b64decode(base64_audio)
prediction = replicate.run(
f"{MODEL_STT}:{VERSION}", input={"audio": io.BytesIO(audio_bytes), **ARGS}
)
text = "n".join(segment["text"] for segment in prediction.get("segments", []))
return text
Which can be used easily as:
with open("audio.ogx", "rb") as f:
content = f.read()
_base64_audio = base64.b64encode(content).decode("utf-8")
_prediction = transcribe_audio(_base64_audio)
pprint.pprint(_prediction)
Then, for the second component, we define a similar function:
def call_llm(prompt):
prediction = replicate.stream(MODEL_LLM, input={"prompt": prompt, **ARGS})
output_text = ""
for event in prediction:
output_text += str(event)
return output_text
This will query the LLM and stream responses from it token by token into the output_text
Next, we define the full workflow in the following async method:
async def run_workflow(self, audio_data):
self.prompt = "Transcribing audio..."
self.response_html = ""
self.audio_byte64 = audio_data.args["audioBlobBase64"]
self.prompt = await run.io_bound(
callback=transcribe_audio, base64_audio=self.audio_byte64
)
self.response_html = "Calling LLM..."
self.response = await run.io_bound(callback=call_llm, prompt=self.prompt)
self.response_html = self.response.replace("n", "</br>")
ui.notify("Result Ready!")
Once the audio data is ready, we first transcribe the audio, then once this is done, we call the LLM and display its response. The variables self.prompt and self.response_html are bound to other NiceGUI components that get updated automatically. If you want to know more about how that works, you can look into a previous tutorial I wrote:
Meet the NiceGUI: Your Soon-to-be Favorite Python UI Library
The full workflow result looks like this:
Pretty neat!
What takes the most time here is the audio transcription. The endpoint is always warm on replicate when I check it, but this version is the large-v3 which is not the fastest one. Audio files are also a lot heavier to move around than plain text, so this contributes to the small latency.
Notes:
- You will need to set REPLICATE_API_TOKEN before running this code. You can get this by signing up in replicate.com. I was able to do these experiments using their free tier.
- Sometimes the transcription is delayed a little bit and is returned after a short “Queuing” period.
- Code is at: https://github.com/CVxTz/LLM-Voice The entry point is main.py.
Conclusion
In summary, the integration of open-source models like Whisper and Llama 3 has significantly simplified voice interaction with LLMs, making it highly accessible and user-friendly. This combination is particularly convenient for users who prefer not to type, offering a smooth experience. However, this is only the first part of the project; there will be more improvements to come. The next steps include enabling two-way voice communication, providing the option to utilize local models for enhanced privacy, enhancing the overall design for a more polished interface, implementing multi-turn conversations for more natural interactions, developing a desktop application for wider accessibility, and optimizing latency for real-time speech-to-text processing. With these enhancements, the aim is to improve the experience of voice interaction with LLMs, making it easier to use for those, like me, that don’t like typing that much.
Let me know which improvements do you think I should work on first.
Speak, Don’t Type: Exploring Voice Interaction with LLMs [Part 1] was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Speak, Don’t Type: Exploring Voice Interaction with LLMs [Part 1]
Go Here to Read this Fast! Speak, Don’t Type: Exploring Voice Interaction with LLMs [Part 1]