

A brief overview
This article is meant to provide a simple approachable summary of studies that explored labelling data with LLMs¹. We will cover current views on annotating textual data with LLMs and also things to consider for your own projects.
Overview:
Why even use an LLM for labelling?
High quality labelled data creates the foundation for training and evaluating machine learning models across diverse tasks. The most common approach to annotating datasets right now is to hire crowd-workers (e.g. Amazon Mechanical Turk) or domain experts if specialised knowledge is required.
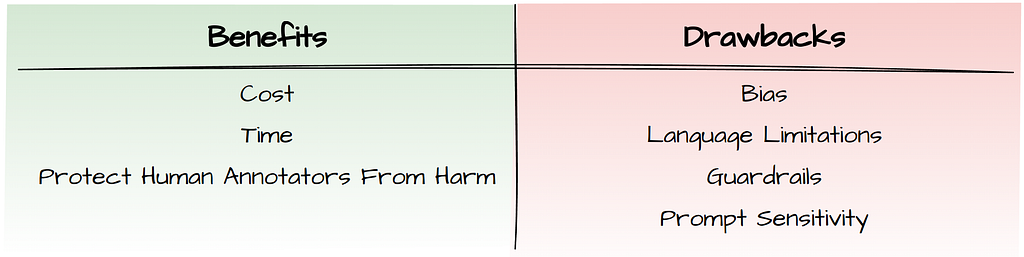
These approaches can be rather expensive and time-consuming, which is why a lot of people are now wondering if LLMs can handle data labelling well enough. Businesses with limited budgets could benefit from this by building specialised models that address their particular needs. In more sensitive domains like medicine, there’s potential to speed up the labelling process by having experts review and correct LLM labels rather than starting from scratch.
Additionally, researchers at Carnegie Mellon & Google find that people are motivated by the possibility of protecting human annotators from psychological harm caused during the labelling process (e.g hate-speech) as well as the diversification of opinions in the data.
Current views across different studies
Opinions are somewhat split amongst studies regarding the potential of LLMs as annotators. While some studies are optimistic about their capabilities, others remain sceptical. Table 1 provides an overview of the approach and results from twelve studies. You can find the source of these studies in the References (see end of this article).

Model²
The Number of Model Families highlights that most of the studies only test one model family and when we look at which model they used, we can see that almost all except for 2 studies used GPT. Study [7] is the only one which solely focuses on the exploration of open-source LLMs (Table 2).

Datasets
The third column of Table 1 contains the Number of Datasets that were used for labelling purposes. The different studies explore different tasks and thereby also a variety of datasets. Most explore the performance on more than one dataset. Study [3] stands out by testing LLM classification performance across 20 different datasets. More details on which datasets were used are shown in Table 3 below, and could help you spot the studies most relevant to you.
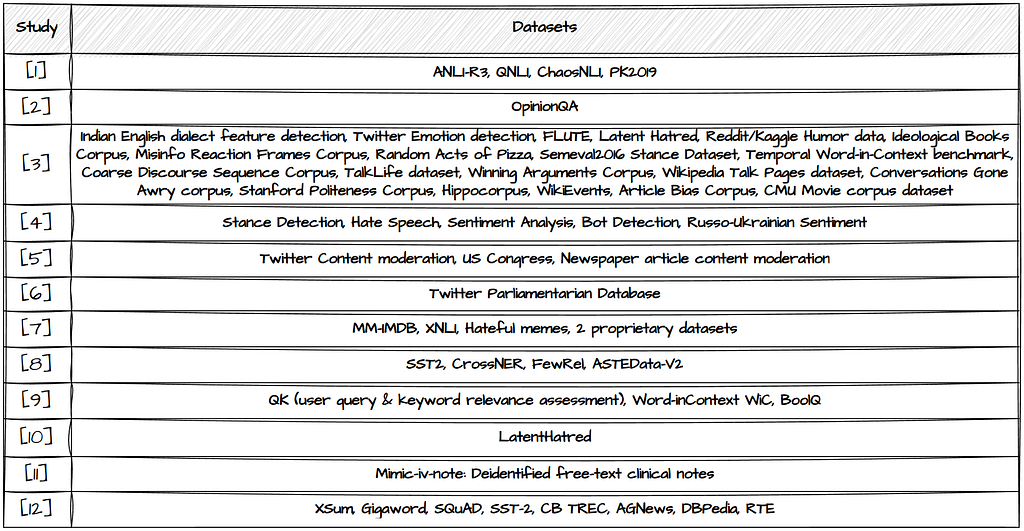
If you’re starting out with no labelled data at hand: Have a look at existing labelled datasets for tasks that are similar to your own use case and label the data with an LLM. Compare the LLM generated labels with the human labels by investigating the errors and potential issues in detail. This should give you an indication of how well the LLM will perform on your task and whether the time & cost savinngs can be justified.
Perspectivist Approach
A Perspectivist Approach simply means recognising that there is no one “right” way to understand a dataset or solve a problem. Different perspectives can reveal different insights or solutions. Whereas traditionally, most datasets are labelled using a majority voting approach, meaning that the most commonly chosen label is viewed as the ground truth:

In Table 1, the labelling approach is categorised based on whether the study uses a majority voting or perspectivist mindset. We can see that most of the studies take a majority voting approach towards their labelling efforts.
LLM as Annotator?
The last column summarises each study’s findings, with a check-mark indicating a tendency towards believing that LLMs can be helpful in the annotation process. While some are quite optimistic about their potential and suggest the replacement of human annotators, others see them more as a support tool rather than a substitute for humans. Regardless, even amongst these studies with a positive outlook, there are some tasks on which LLMs don’t perform well enough.
Additionally, three studies, two of which follow the perspectivist approach, conclude that they are not suited for labelling data. Another study (not included in the table) takes a different approach and shows that the current method of aligning LLMs via a single reward function doesn’t capture the diversity of preferences among different human subgroups, especially minority views.
Things to Consider when Using LLMs as Annotators
Prompting: Zero vs. Few-shot
Obtaining meaningful responses from LLMs can be a bit of a challenge. How do you then best prompt an LLM to label your data? As we can see from Table 1, the above studies explored either zero-shot or few-shot prompting, or both. Zero-shot prompting expects an answer from the LLM without having seen any examples in the prompt. Whereas few-shot prompting includes multiple examples in the prompt itself so that the LLM knows what a desired response looks like:
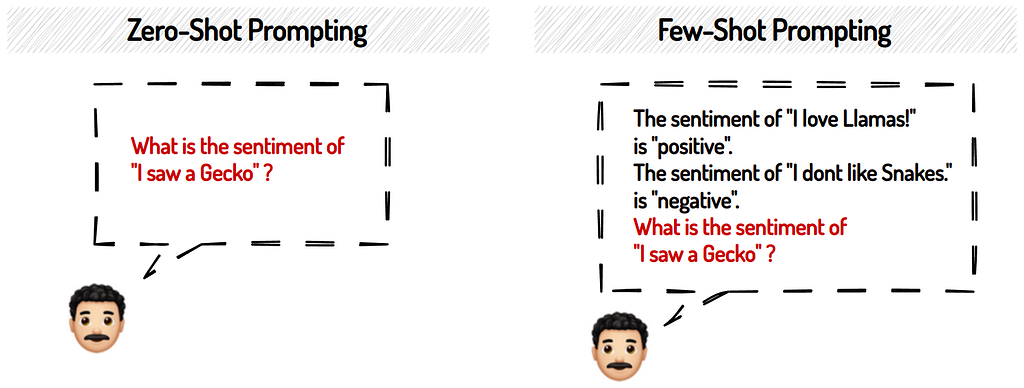
The studies differ in their views on which approach returns better results. Some resort to few-shot prompting on their tasks, others to zero-shot prompting. So you might want to explore what works best for your particular use case and model.
If you are wondering how to even start with good prompting Sander Schulhoff & Shyamal H Anadkat have created LearnPrompting which can help you with basics and also more advanced techniques.
Prompting: Sensitivity
LLMs are sensitive to minor modifications in the prompt. Changing one word of your prompt can affect the response. If you want to account for that variability to some degree you could approach it as in study [3]. First, they let a task expert provide the initial prompt. Then, using GPT, they generate 4 more with similar meaning and average the results over all 5 prompts. Or you could also explore moving away from hand-written prompts and try replacing them with signatures leaving it to DSPy to optimise the prompt for you as shown in Leonie Monigatti’s blog post.
Model Choice

Which model should you choose for labelling your dataset? There are a few factors to consider. Let’s briefly touch on some key considerations:
- Open Source vs. Closed Source: Do you go for the latest best performing model? Or is open-source customisation more important to you? You’ll need to think about things such as your budget, performance requirements, customization and ownership preferences, security needs, and community support requirements.
- Guardrails: LLMs have guardrails in place to prevent them from responding with undesirable or harmful content. If your task involves sensitive content, models might refuse to label your data. Also, LLMs vary in the strength of their safeguards, so you should explore and compare them to find the most suitable one for your task.
- Model Size: LLMs come in different sizes and bigger models might perform better but they also require more compute resources. If you prefer to use open-source LLMs and have limited compute, you could consider quantisation. In the case of closed-source models, the larger models currently have higher costs per prompt associated with them. But is bigger always better?
Model Bias
According to study [3] larger, instruction-tuned³ models show superior labelling performance. However, the study doesn’t evaluate bias in their results. Another research effort shows that bias tends to increase with both scale and ambiguous contexts. Several studies also warn about left-leaning tendencies and the limited capability to accurately represent the opinions of minority groups (e.g. older individuals or underrepresented religions). All in all, current LLMs show considerable cultural biases and respond with stereotyped views of minority individuals. Depending on your task and its aims, these are things to consider across every timeline in your project.

“By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries” — quote from study [2]
Model Parameter: Temperature
A commonly mentioned parameter across most studies in Table 1 is the temperature parameter, which adjusts the “creativity” of the LLMs outputs. Studies [5] and [6] experiment with both higher and lower temperatures, and find that LLMs have higher consistency in responses with lower temperatures without sacrificing accuracy; therefore they recommend lower values for annotation tasks.
Language Limitations
As we can see in Table 1, most of the studies measure the LLMs labelling performance on English datasets. Study [7] explores French, Dutch and English tasks and sees a considerable decline in performance with the non-English languages. Currently, LLMs perform better in English, but alternatives are underway to extend their benefits to non-English users. Two such initiatives include: YugoGPT (for Serbian, Croatian, Bosnian, Montenegrin) by Aleksa Gordić & Aya (101 different languages) by Cohere for AI.
Human Reasoning & Behaviour (Natural Language Explanations)
Apart from simply requesting a label from the LLM, we can also ask it to provide an explanation for the chosen label. One of the studies [10] finds that GPT returns explanations that are comparable, if not more clear than those produced by humans. However, we also have researchers from Carnegie Mellon & Google highlighting that LLMs are not yet capable of simulating human decision making and don’t show human-like behavior in their choices. They find that instruction-tuned models show even less human-like behaviour and say that LLMs should not be used to substitute humans in the annotation pipeline. I would also caution the use of natural language explanations at this stage in time.
“Substitution undermines three values: the representation of participants’ interests; participants’ inclusion and empowerment in the development process” — quote from Agnew (2023)
Summary | TL;DR
- LLMs can be an option for those with limited budgets and relatively objective tasks, where you care about the most likely label. Be careful with subjective tasks where opinions about the correct label might differ considerably!
- Avoid using LLMs to simulate human reasoning and behaviour.
- For more critical tasks (e.g. healthcare) you could use LLMs to speed up the labelling process by having humans correct the labelled data; but don’t remove humans from the labelling process entirely!
- Evaluate your results critically for biases & other problems and consider if the cost of the errors are worth the trouble they might cause.
This review is by no means an exhaustive comparison. If you have other sources that can contribute to the discussion or personal experience with LLM data labelling, please do share in the comments.
References
- If you want to look at the studies and other resources individually here is a list of all the papers used to create this blog post: Blog References.
- If you want more insights on Table 1 and the studies, I will be attaching a workshop paper here soon: link to come
Footnotes
¹This is not a comprehensive review on all the literature out there but covers only papers I found whilst doing reading on this topic. Additionally, my focus was mostly on classification tasks.
²Given the pace of development in LLMs, there are now a lot more powerful models available compared to the ones tested in these studies.
³Instruction-tuned models are trained with a focus on understanding and generating accurate and coherent responses based on given instructions/prompts.
Can Large Language Models (LLMs) be used to label data? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Can Large Language Models (LLMs) be used to label data?
Go Here to Read this Fast! Can Large Language Models (LLMs) be used to label data?