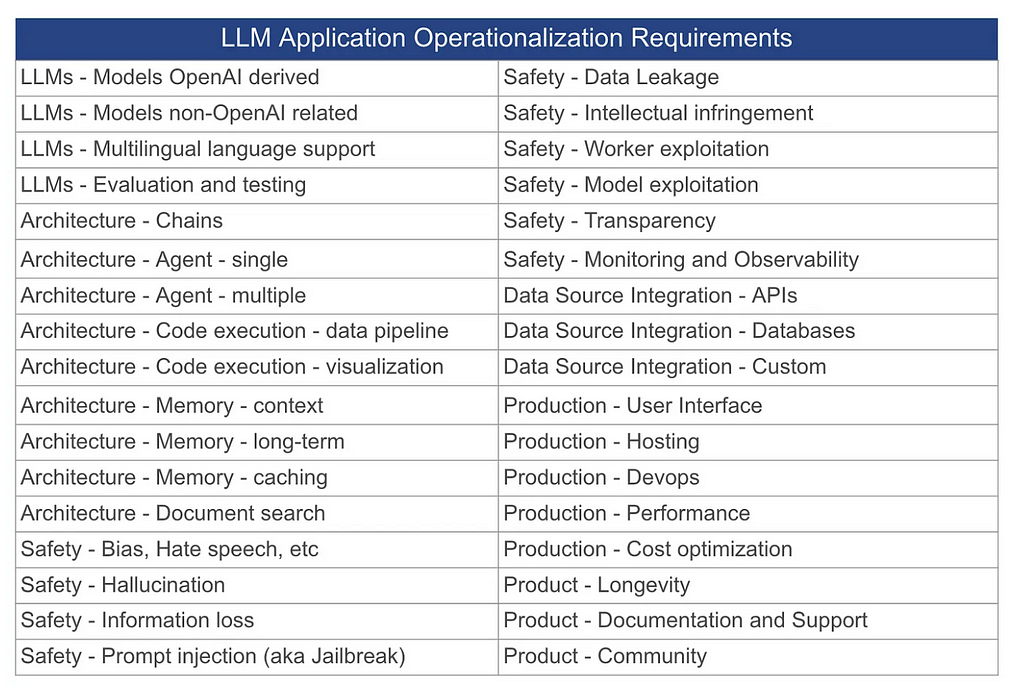
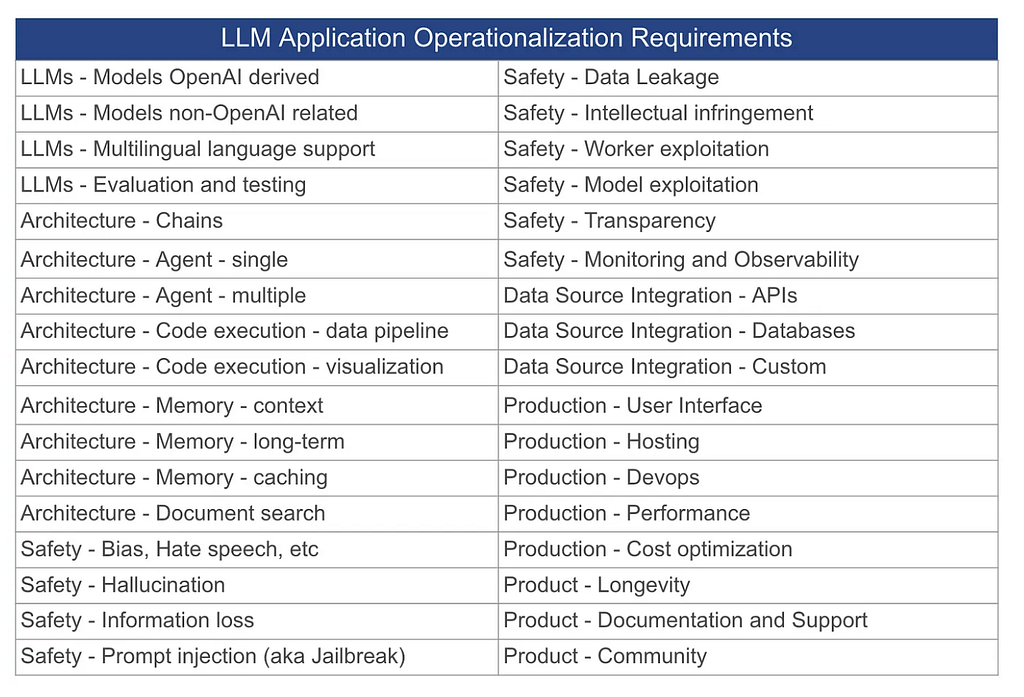
TL;DR
There are lots of tutorials on using powerful Large Language Models (LLMs) for knowledge retrieval. However, if considering real-world application of these techniques, engineering best practices need to be applied and these should be extended to mitigate some of the new risks associated with LLMs, such as hallucinations. In this article, we explore how to implement some key areas required for operationalizing LLMs — such as safety, prompt engineering, grounding, and evaluation — developing a simple Prompt Flow to create a simple demo AI assistant for answering questions about humanitarian disasters using information from situation reports on the ReliefWeb platform. Prompt Flow includes a great set of tools for orchestrating LLM workflows, and packages such as deep eval provide ways to test outputs on the fly using LLMs (albeit with some caveats).
Operationalizing Large Language Model Applications
In a previous blog post “Some thoughts on operationalizing LLM Applications”, we discussed that when launching LLM applications there are a wide range of factors to consider beyond the shiny new technology of generative AI. Many of the engineering requirements apply to any software development, such as DevOps and having a solid framework to monitor and evaluate performance, but other areas such as mitigating hallucination risk are fairly new. Any organization launching a fancy new generative AI application ignores these at their peril, especially in high-risk contexts where biased, incorrect, and missing information could have very damaging outcomes.
Many organizations are going through this operatiuonalizing process right now and are trying to figure out how exactly to use new Generative AI. The good news is that we are in a phase where supporting products and services are beginning to make it a lot easier to apply solid principles for making applications safe, cost-effective, and accurate. AWS Bedrock, Azure Machine Learning and Studio, Azure AI Studio (preview), and a wide range of other vendor and open source products all make it easier to develop LLM solutions.
Prompt Flow
In this article, we will focus on using Prompt Flow, an open-source project developed by Microsoft …
Prompt Flow is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, and evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.
Why Prompt Flow?
After quite a bit of personal research, Prompt Flow has emerged as a great way to develop LLM applications in some situations because of the following …
- Intuitive user interface. As we shall see below, even simple LLM applications require complicated workflows. Prompt Flow offers a nice development user interface, making it easier to visualize flows, with built-in evaluation and strong integration with Visual Studio Code supported by solid supporting documentation.
- Open source. This is useful in situations where applications are being shipped to organizations with different infrastructure requirements. As we shall see below, Prompt Flow isn’t tied to any specific cloud vendor (even though it was developed by Microsoft) and can be deployed in several ways.
- Enterprise support in Azure. Though open source, if you are on Azure, Prompt Flow is natively supported and provides a wide range of enterprise-grade features. Being part of Azure Machine Learning Studio and the preview Azure AI studio, it comes with off-the-shelf-integration for safety, observability, and deployment, freeing up time to focus on the business use case
- Easy deployment. As mentioned above, deployment on Azure is a few clicks. But even if you are running locally or another cloud vendor, Prompt flow supports deployment using Docker
It may not be ideal for all situations of course, but if you want the best of both worlds — open source and enterprise support in Azure — then Prompt Flow might be for you.
An AI assistant to answer questions about active humanitarian disasters
In this article we will develop an AI assistant with Prompt Flow that can answer questions using information contained in humanitarian reports on the amazing ReliefWeb platform. ReliefWeb includes content submitted by humanitarian organizations which provide information about what is happening on the ground for disasters around the world, a common format being ‘Situation Reports’. There can be a lot of content so being able to extract a key piece of required information quickly is less effort than reading through each report one by one.
Please note: Code for this article can be found here, but it should be mentioned that it is a basic example and only meant to demonstrate some key concepts for operationalizing LLMs. For it to be used in production more work would be required around integration and querying of ReliefWeb, as well as including the analysis of PDF documents rather than just their HTML summaries, but hopefully the code provides some examples people may find useful.
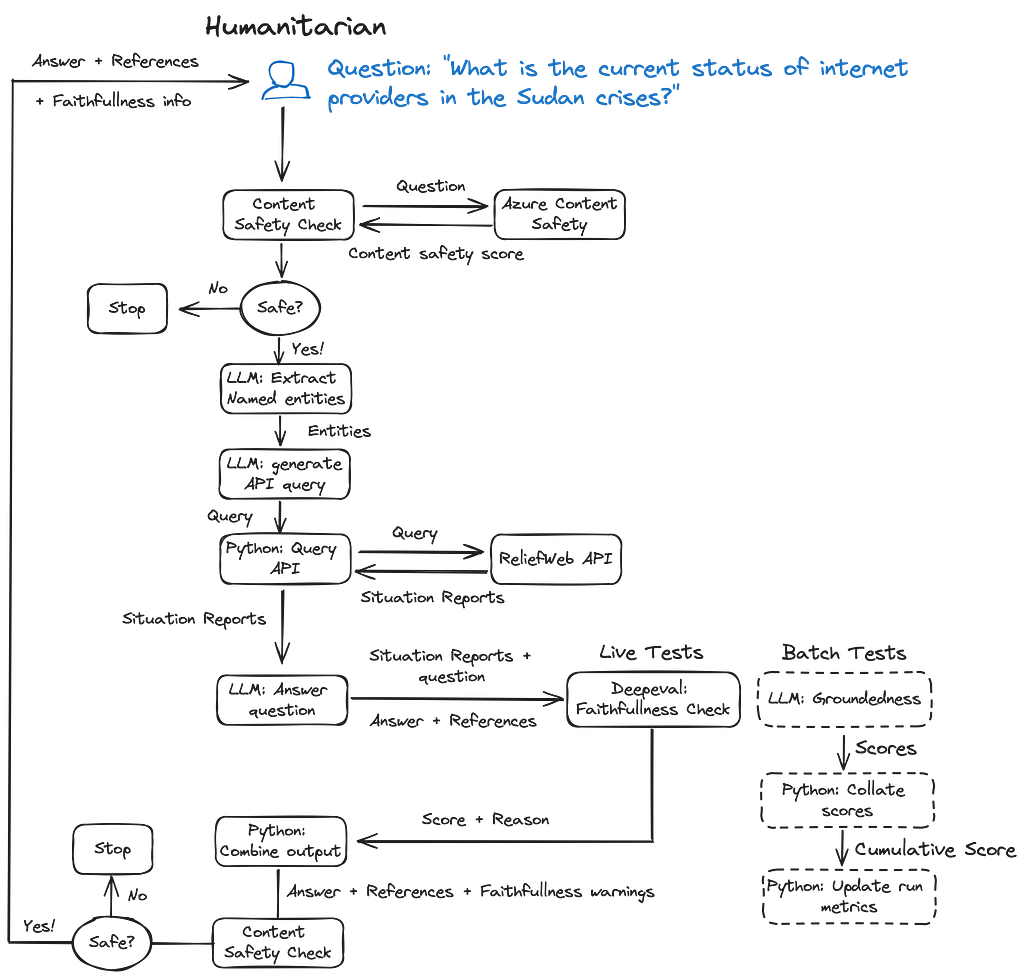
The demo application has been set up to demonstrate the following …
- Content safety monitoring
- Orchestrating LLM tasks
- Automated self-checking for factual accuracy and coverage
- Batch testing of groundedness
- Self-testing using Prompt Flow run in GitHub actions
- Deployment
Setup of the demo Prompt Flow application
The demo application for this article comes with a requirements.txt and runs with Python 3.11.4 should you want to install it in your existing environment, otherwise please see the setup steps below.
If you don’t have these already, install …
Then run through the following steps …
4. You will need LLM API Keys from either OpenAI or Azure OpenAI, as well as the deployment names of the models you want to use
5. Check out the application repo which includes the Prompt Flow app in this article
6. In your repo’s top folder, copy.env.example to .env and set the API keys in that file
7. Set up an environment at the command line, open a terminal, and in the repo top directory run: conda env create -f environment.yml. This will build a conda environment called pf-rweb-demo
8. Open VS Code
9. Open the repo with File > Open Folder and select the repo’s top directory
10. In VS Code, click on the Prompt flow icon — it looks like a ‘P’ on the left-hand bar

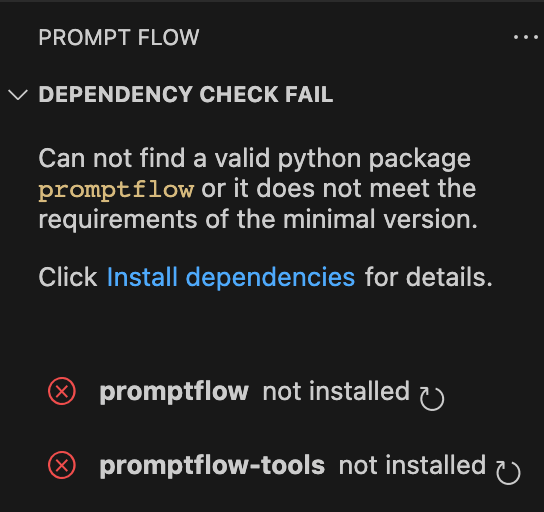
11. The first time you click on this, you should see on the upper-left, the message below, click on the ‘Install dependencies’ link
12. Click ‘Select Python Interpreter’ and choose the conda Python environment pf-rweb-demoyou built in step 7. Once you do this the libraries section should

13. You should now see a section called ‘Flows’ on the left-hand navigation, click on the ‘relief web_chat’ and select ‘Open’

This should open the Prompt Flow user interface …
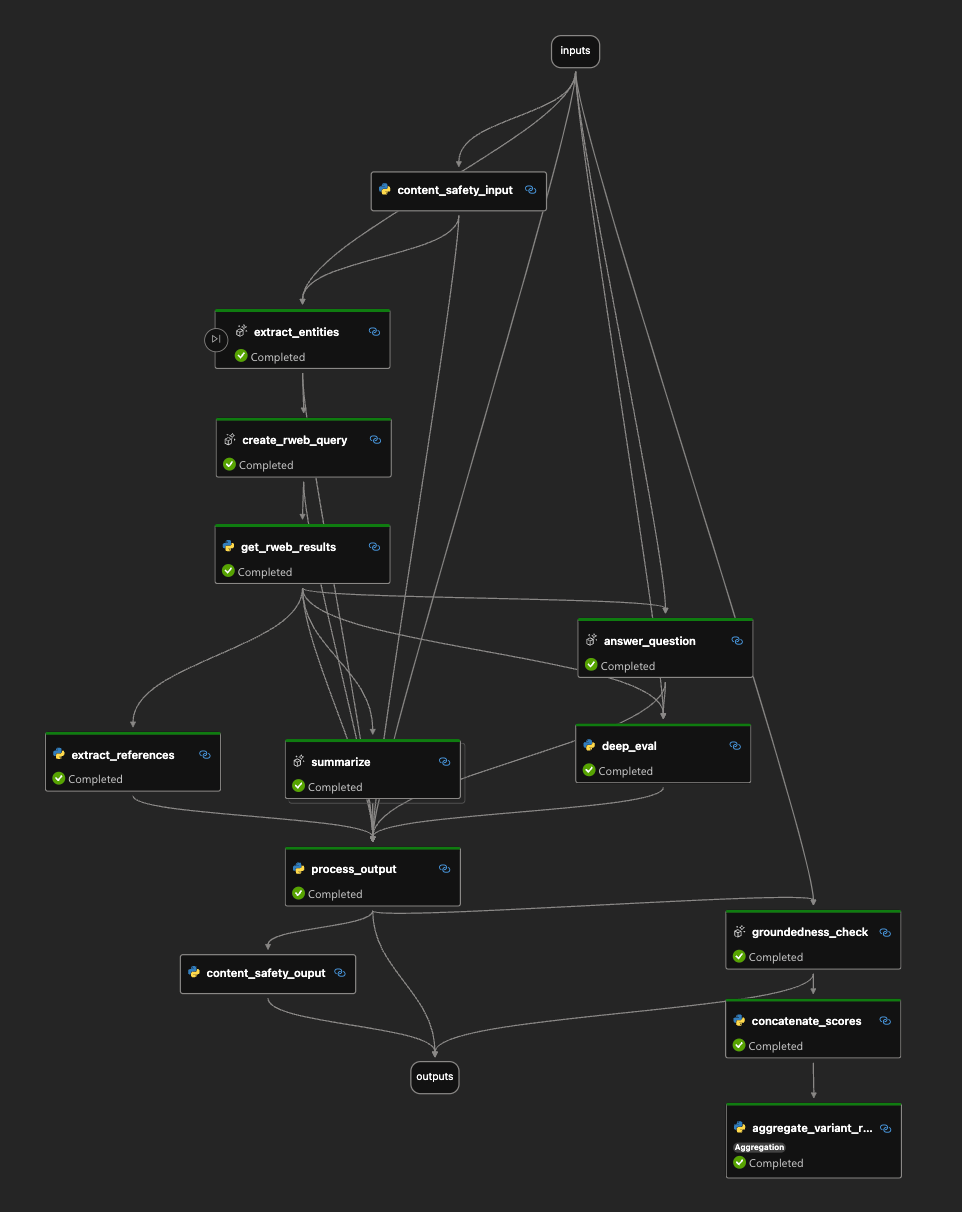
12. Click on the ‘P’ (Prompt Flow) in the left-hand vertical bar, you should see a section for connections
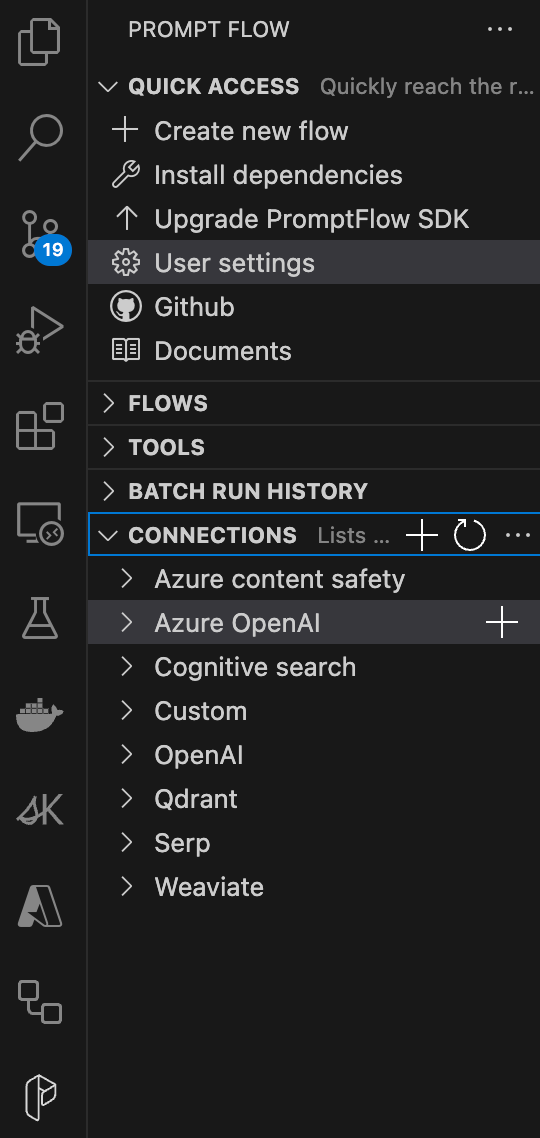
13. Click on the ‘+’ for either Azure OpenAI or OpenAI depending on which service you are using.
14. In the connection edit window, set the name to something reasonable, and if using Azure the fieldapi_base to your base URL. Don’t populate the api_key as you will get prompted for this.
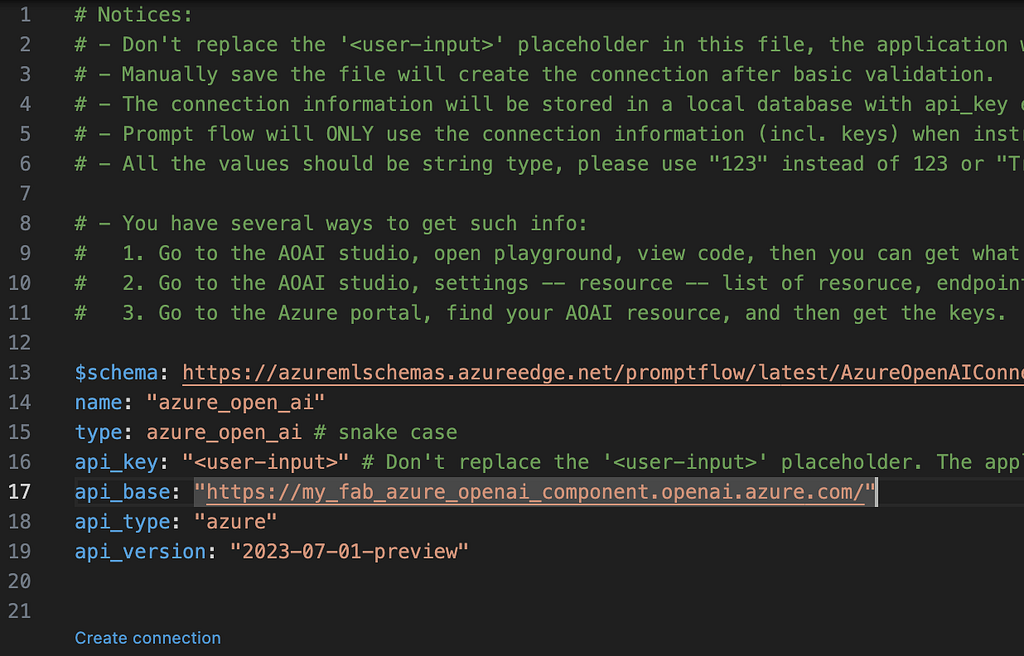
15. Click the little ‘create connection’ and when prompted enter your API Key, your connection has now been created
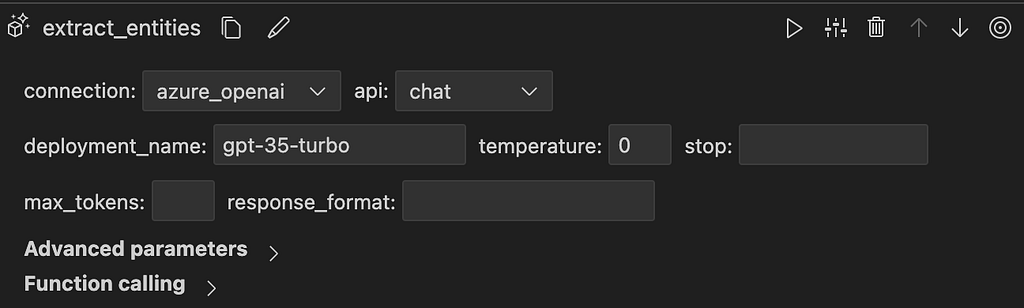
16. If you are using Azure and called your connection azure_openai and have model deployments ‘gpt-4-turbo’ and ‘got-35-turbo-16k’, you should be configured, otherwise, click on any LLM Nodes in the Prompt Flow user interface and set the connection and deployment name appropriately. See below for the settings used for ‘extract_entities’ LLM node
Running the demo Prompt Flow application
Now that you’re all set up, anytime you want to run the flow …
- Open the flow as described in steps 9–11 above
- Click on the little double-play icon at the top of the flow

This should run the full flow. To see the outputs you can click on any node and view inputs/outputs and even run individual nodes as part of debugging.
Now, let’s go through some of the main components of the application …
Content Safety
Any chat application using LLMs should have some tests to ensure user inputs and LLM outputs are safe. Safety checks should cover areas such as:
- Bias
- Hate speech / Toxicity
- Self-harm
- Violence
- Prompt injection (hacking to get different prompt through to the LLM)
- Intellectual property infringement
This list is not exhaustive and not all will be applicable, depending on the application context, but a review should always be carried out and appropriate safety tests identified.
Prompt Flow comes with integration to Azure content safety which covers some of the above and is very easy to implement by selecting ‘Content Safety’ when creating a new node in the flow. I originally configured the demo application to use this, but realized not everybody will have Azure so instead the flow includes two Python placeholder nodes content_safety_in and content_safety_out to illustrate where content safety checks could be applied. These do not implement actual safety validation in the demo application, but libraries such as Guardrails AI and deep eval offer a range of tests that could be used in these scripts.
The content_safety_innode controls the downstream flow, and will not call those tasks if the content is considered unsafe.
Given the LLM output is heavily grounded in provided data and evaluated on the fly, it’s probably overkill to include a safety check on the output for this application, but it illustrates that there are two points safety could be enforced in an LLM application.
It should also be noted that Azure also provides safety filters at the LLM level if using Azure Model Library. This can be a convenient way to implement content safety without having to develop code or specify nodes in your flow, clicking a button and paying a little extra for a safety service can sometimes be the better option.
Entity Extraction
In order to query the ReliefWeb API it is useful to extract entities from the user’s question and search with those rather than the raw input. Depending on the remote API this can yield more appropriate situation reports for finding answers.
An example in the demo application is as follows …
User input: “How many children are affected by the Sudan crises?”
LLM Entities extracted:
[
{
"entity_type": "disaster_type",
"entity": "sudan crises"
}
]
ReliefWeb API query string: “Sudan crises”
This is a very basic entity extraction as we are only interested in a simple search query that will return results in the ReliefWeb API. The API supports more complex filtering and entity extraction could be extended accordingly. Other Named Entity Recognition techniques like GLiNER may improve performance.
Getting data from the ReliefWeb API
Once a query string is generated, a call to the ReliefWeb API can be made. For the demo application we restrict the results to the top 5 most recent situation reports, where Python code creates the following API request …
{
"appname": “<YOUR APP NAME>”,
"query": {
"value": "Sudan crises",
"operator": "AND"
},
"filter": {
"conditions": [
{
"field": "format.name",
"value": "Situation Report"
}
]
},
"limit": 5,
"offset": 0,
"fields": {
"include": [
"title",
"body",
"url",
"source",
"date",
"format",
"status",
"primary_country",
"id"
]
},
"preset": "latest",
"profile": "list"
}
[ The above corresponds with this website query ]
One thing to note about calling APIs is that they can incur costs if API results are processed directly by the LLM. I’ve written a little about this here, but for small amounts of data, the above approach should suffice.
Summarization
Though the focus of the demo application is on answering a specific question, a summary node has been included in the flow to illustrate the possibility of having the LLM perform more than one task. This is where Prompt Flow works well, in orchestrating complex multi-task processes.
LLM summarization is an active research field and poses some interesting challenges. Any summarization will lose information from the original document, this is expected. However, controlling which information is excluded is important and will be specific to requirements. When summarizing a ReliefWeb situation report, it may be important in one scenario to ensure all metrics associated with refugee migration are accurately represented. Other scenarios might require that information related to infrastructure is the focus. The point being that a summarization prompt may need to be tailored to the audience’s requirements. If this is not the case, there are some useful general summarization prompts such as Chain of Density (CoD) which aim to capture pertinent information.
The demo app has two summarization prompts, a very basic one …
system:
You are a humanitarian researcher who needs produces accurate and consise summaries of latest news
========= TEXT BEGIN =========
{{text}}
========= TEXT END =========
Using the output from reliefweb above, write a summary of the article.
Be sure to capture any numerical data, and the main points of the article.
Be sure to capture any organizations or people mentioned in the article.
As well as a variant which uses CoD …
system:
Article:
{{text}}
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
You are an expert in writing rich and dense summaries in broad domains.
You will generate increasingly concise, entity-dense summaries of the above JSON list of data extracted.
Repeat the following 2 steps 5 times.
- Step 1: Identify 1-3 informative Entities from the Article
which are missing from the previously generated summary and are the most
relevant.
- Step 2: Write a new, denser summary of identical length which covers
every entity and detail from the previous summary plus the missing entities
A Missing Entity is:
- Relevant: to the main story
- Specific: descriptive yet concise (5 words or fewer)
- Novel: not in the previous summary
- Faithful: present in the Article
- Anywhere: located anywhere in the Article
Guidelines:
- The first summary should be long (5 paragraphs) yet
highly non-specific, containing little information beyond the entities
marked as missing.
- Use overly verbose language and fillers (e.g. "this article discusses") to
reach approx.
- Make every word count: re-write the previous summary to improve flow and
make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases
like "the article discusses"
- The summaries should become highly dense and concise yet self-contained,
e.g., easily understood without the Article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made,
add fewer new entities.
> Remember to use the exact same number of words for each summary.
Answer in JSON.
> The JSON in `summaries_per_step` should be a list (length 5) of
dictionaries whose keys are "missing_entities" and "denser_summary".
Question Answering
The demo app contains a node to answer the user’s original question. For this we used a prompt as follows:
system:
You are a helpful assistant. Using the output from a query to reliefweb,
anser the user's question.
You always provide your sources when answering a question, providing the
report name, link and quote the relevant information.
{{reliefweb_data}}
{% for item in chat_history %}
user:
{{item.inputs.question}}
assistant:
{{item.outputs.answer}}
{% endfor %}
user:
{{question}}
This is a basic prompt which includes a request to include references and links with any answer.
Attribution of Informational Sources
Even with validation and automatic fact-checking of LLM outputs, it is very important to provide attribution links to data sources used so the human can check themselves. In some cases it may still be useful to provide an uncertain answer — clearly informing the user about the uncertainty — as long as there is an information trail to the sources for further human validation.
In our example this means links to the situation reports which were used to answer the user’s question. This allows the person asking the question to jump to the sources and check facts themselves, as well as read additional context. In the demo app we have included two attribution methodologies. The first is to include a request in the prompt, as shown above. As with any LLM output this can of course result in hallucination, but as we’ll see below these can be validated.
The second method is to simply collate a list of documents returned in the API call, being all the sources reviewed even if some weren’t used in the answer. Being able to view the full list can help identify cases where a key report was perhaps missed due to how the API was queried.
Both attribution methods can be useful to the user in understanding how their answer was found.
Automatic Fact Checking
LLM information extraction, though amazing, is imperfect. Hallucinations and information omission are possible in situations where questions are asked of content. Therefore it’s key to validate the answer to ensure it isn’t presenting incorrect or incomplete information. Since we are essentially comparing one text (raw data returned from the API) with LLM-generated text (the question answer), we can also use LLMs to validate. With good prompt design these can be made to work well, if not absolutely perfectly.
In the demo app we have include two methods for this to illustrate …
Real-time fact checking
One useful library for checking LLM-generated output against the source data is deep eval, which offers a wide range of tests for LLM generated output. In our example we have implemented a faithfulness check to compare the answer with raw API output and give a score between 0–1 and reason for that score, where 1 is the best score possible. In the demo app, even if the score is less than 1 we have opted to allow the answer to be presented to the user, along with a warning and reasons, about the score being less than perfect.
Here is an example answer showing the warning for a run asking the question “What is the current status of internet providers in the Sudan crises?” where we adjusted the answer intentionally to say the effects were minor instead of the true major communications outage mentioned in the source data …
The current status of internet providers in Sudan, as reported in the “Sudan, conflict — ETC Situation Report #15 Reporting period: 01/02/2024 to 29/02/2024” by the Emergency Telecommunications Cluster (ETC) led by the World Food Programme (WFP), indicates that there have been only minor disruptions to telecommunications infrastructure due to the conflict between the Sudanese Armed Forces (SAF) and the Rapid Support Forces (RSF). Here is the relevant excerpt from the report:
“All three of Sudan’s main internet operators were reported as offline on 07 February in the latest of a minor network blackout of communications affecting millions of people.”
This information suggests that as of the reporting period, there was a minor network blackout, and the main internet operators in Sudan were offline, which would have a minor impact on communication and response efforts within the country.
For more details, you can access the full report on ReliefWeb: Sudan, conflict — ETC Situation Report #15.
Warning! Fact checker evaluation returned a score of 0.88/1.0
Reason:
The score is 0.88 because the actual output incorrectly downplays the extent of the damage to telecommunications infrastructure in Sudan, suggesting only minor disruptions, whereas the retrieval context indicates there was widespread damage to telecommunications infrastructure and the national power grid.
Note the Warning section at the end and the associated Reason.
It should however be noted, that though deep eval offers a neat way to evaluate LLMs, since it uses an LLM it too could sometimes suffer from hallucination. For the demo application performance was acceptable in re-running the same question 20 times, but for production, it would make sense to include self-tests to evaluate the evaluation (!) and ensure behavior is as expected.
Batch Groundedness testing
Another approach supported by Prompt Flow is the ability to create a test file with inputs and context information, which can be executed in a prompt flow batch run. This is analogous to software self-tests, with a twist that in evaluating LLMs where responses can vary slightly each time, it’s useful to use LLMs in the tests also. In the demo app, there is a groundedness test that does exactly this for batch runs, where the outputs of all tests are collated and summarized so that performance can be tracked over time.
We have included batch test nodes in the demo app for demonstration purposes, but in the live applications, they wouldn’t be required and could be removed for improved performance.
Finally, it’s worth noting that although we can implement strategies to mitigate LLM-related issues, any software can have bugs. If the data being returned from the API doesn’t contain the required information to begin with, no amount of LLM magic will find the answer. For example, the data returned from ReliefWeb is heavily influenced by the search engine so if the best search terms aren’t used, important reports may not be included in the raw data. LLM fact-checking cannot control for this, so it’s important not to forget good old-fashioned self-tests and integration tests.
LLMOps
Now that we have batch tests in Prompt Flow, we can use these as part of our DevOps, or LLMOps, process. The demo app repo contains a set of GitHub actions that run the tests automatically, and check the aggregated results to automatically confirm if the app is performing as expected. This confirmation could be used to control whether the application is deployed or not.
Deployment
Which brings us onto deployment. Prompt Flow offers easy ways to deploy, which is a really great feature which may save time so more effort can be put into addressing the user’s requirements.
The ‘Build’ option will suggest two options ‘Build as local app’ and ‘Build as Docker’.

The first is quite useful and will launch a chat interface, but it’s only meant for testing and not production. The second will build a Docker container, to present an API app running the flow. This container could be deployed on platforms supporting docker and used in conjunction with a front-end chat interface such as Streamline, chainlit, Copilot Studio, etc. If deploying using Docker, then observability for how your app is used — a must for ensuring AI safety — needs to be configured on the service hosting the Docker container.
For those using Azure, the flow can be imported to Azure Machine Learning, where it can be managed as in VS Code. One additional feature here is that it can be deployed as an API with the click of a button. This is a great option because the deployment can be configured to include detailed observability and safety monitoring with very little effort, albeit with some cost.
Final Thoughts
We have carried out a quick exploration of how to implement some important concepts required when operationalizing LLMs: content safety, fact checking (real-time and batch), fact attribution, prompt engineering, and DevOps. These were implemented using Prompt Flow, a powerful framework for developing LLM applications.
The demo application we used is only a demonstration, but it shows how complex simple tasks can quickly get when considering all aspects of productionizing LLM applications safely.
Caveats and Trade-offs
As with all things, there are trade-offs when implementing some of the items above. Adding safety tests and real-time evaluation will slow application response times and incur some extra costs. For me, this is an acceptable trade-off for ensuring solutions are safe and accurate.
Also, though the LLM evaluation techniques are a great step forward in making applications more trustworthy and safe, using LLMs for this is not infallible and will sometimes fail. This can be addressed with more engineering of the LLM output in the demo application, as well as advances in LLM capabilities — it’s still a relatively new field — but it’s worth mentioning here that application design should include evaluation of the evaluation techniques. For example, creating a set of self-tests with defined context and question answers and running those through the evaluation workflow to give confidence it will work as expected in a dynamic environment.
I hope you have enjoyed this article!
References
- Prompt Flow documentation
- ReliefWeb
- From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting, Adams et al, 2023
- GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer, Zaratiana et al, 2023
- The code for this article can be found here
Please like this article if inclined and I’d be delighted if you followed me! You can find more articles here.
A Humanitarian Crises Situation Report AI Assistant: Exploring LLMOps with Prompt Flow was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Humanitarian Crises Situation Report AI Assistant: Exploring LLMOps with Prompt Flow