

Step-by-Step Workflow for developing and refining an AI Agent while dealing with errors
When we think about the future of AI, we envision intuitive everyday helpers seamlessly integrating into our workflows and taking on complex, routinely tasks. We all have found touchpoints that relieve us from the tedium of mental routine work. Yet, the main tasks currently tackled involve text creation, correction, and brainstorming, underlined by the significant role RAG (Retrieval-Augmented Generation) pipelines play in ongoing development. We aim to provide Large Language Models with better context to generate more valuable content.
Thinking about the future of AI conjures images of Jarvis from Iron Man or Rasputin from Destiny (the game) for me. In both examples, the AI acts as a voice-controlled interface to a complex system, offering high-level abstractions. For instance, Tony Stark uses it to manage his research, conduct calculations, and run simulations. Even R2D2 can respond to voice commands to interface with unfamiliar computer systems and extract data or interact with building systems.
In these scenarios, AI enables interaction with complex systems without requiring the end user to have a deep understanding of them. This could be likened to an ERP system in a large corporation today. It’s rare to find someone in a large corporation who fully knows and understands every facet of the in-house ERP system. It’s not far-fetched to imagine that, in the near future, AI might assist nearly every interaction with an ERP system. From the end user managing customer data or logging orders to the software developer fixing bugs or implementing new features, these interactions could soon be facilitated by AI assistants familiar with all aspects and processes of the ERP system. Such an AI assistant would know which database to enter customer data into and which processes and code might be relevant to a bug.
To achieve this, several challenges and innovations lie ahead. We need to rethink processes and their documentation. Today’s ERP processes are designed for human use, with specific roles for different users, documentation for humans, input masks for humans, and user interactions designed to be intuitive and error-free. The design of these aspects will look different for AI interactions. We need specific roles for AI interactions and different process designs to enable intuitive and error-free AI interaction. This is already evident in our work with prompts. What we consider to be a clear task often turns out not to be so straightforward.
From Concept to Reality: Building the Basis for AI Agents
However, let’s first take a step back to the concept of agents. Agents, or AI assistants that can perform tasks using the tools provided and make decisions on how to use these tools, are the building blocks that could eventually enable such a system. They are the process components we’d want to integrate into every facet of a complex system. But as highlighted in a previous article, they are challenging to deploy reliably. In this article, I will demonstrate how we can design and optimize an agent capable of reliably interacting with a database.
While the grand vision of AI’s future is inspiring, it’s crucial to take practical steps towards realizing this vision. To demonstrate how we can start building the foundation for such advanced AI systems, let’s focus on creating a prototype agent for a common task: expense tracking. This prototype will serve as a tangible example of how AI can assist in managing financial transactions efficiently, showcasing the potential of AI in automating routine tasks and highlighting the challenges and considerations involved in designing an AI system that interacts seamlessly with databases. By starting with a specific and relatable use case, we can gain valuable insights that will inform the development of more complex AI agents in the future.
The Aim of This Article
This article will lay the groundwork for a series of articles aimed at developing a chatbot that can serve as a single point of interaction for a small business to support and execute business processes or a chatbot that in your personal life organizes everything you need to keep track of. From data, routines, files, to pictures, we want to simply chat with our Assistant, allowing it to figure out where to store and retrieve your data.
Transitioning from the grand vision of AI’s future to practical applications, let’s zoom in on creating a prototype agent. This agent will serve as a foundational step towards realizing the ambitious goals discussed earlier. We will embark on developing an “Expense Tracking” agent, a straightforward yet essential task, demonstrating how AI can assist in managing financial transactions efficiently.
This “Expense Tracking” prototype will not only showcase the potential of AI in automating routine tasks but also illuminate the challenges and considerations involved in designing an AI system that interacts seamlessly with databases. By focusing on this example, we can explore the intricacies of agent design, input validation, and the integration of AI with existing systems — laying a solid foundation for more complex applications in the future.
1. Hands-On: Testing OpenAI Tool Call
To bring our prototype agent to life and identify potential bottlenecks, we’re venturing into testing the tool call functionality of OpenAI. Starting with a basic example of expense tracking, we’re laying down a foundational piece that mimics a real-world application. This stage involves creating a base model and transforming it into the OpenAI tool schema using the langchain library’s convert_to_openai_tool function. Additionally, crafting a report_tool enables our future agent to communicate results or highlight missing information or issues:
from pydantic.v1 import BaseModel, validator
from datetime import datetime
from langchain_core.utils.function_calling import convert_to_openai_tool
class Expense(BaseModel):
description: str
net_amount: float
gross_amount: float
tax_rate: float
date: datetime
class Report(BaseModel):
report: str
add_expense_tool = convert_to_openai_tool(Expense)
report_tool = convert_to_openai_tool(Report)
With the data model and tools set up, the next step is to use the OpenAI client SDK to initiate a simple tool call. In this initial test, we’re intentionally providing insufficient information to the model to see if it can correctly indicate what’s missing. This approach not only tests the functional capability of the agent but also its interactive and error-handling capacities.
Calling OpenAI API
Now, we’ll use the OpenAI client SDK to initiate a simple tool call. In our first test, we deliberately provide the model with insufficient information to see if it can notify us of the missing details.
from openai import OpenAI
from langchain_core.utils.function_calling import convert_to_openai_tool
SYSTEM_MESSAGE = """You are tasked with completing specific objectives and
must report the outcomes. At your disposal, you have a variety of tools,
each specialized in performing a distinct type of task.
For successful task completion:
Thought: Consider the task at hand and determine which tool is best suited
based on its capabilities and the nature of the work.
Use the report_tool with an instruction detailing the results of your work.
If you encounter an issue and cannot complete the task:
Use the report_tool to communicate the challenge or reason for the
task's incompletion.
You will receive feedback based on the outcomes of
each tool's task execution or explanations for any tasks that
couldn't be completed. This feedback loop is crucial for addressing
and resolving any issues by strategically deploying the available tools.
"""
user_message = "I have spend 5$ on a coffee today please track my expense. The tax rate is 0.2."
client = OpenAI()
model_name = "gpt-3.5-turbo-0125"
messages = [
{"role":"system", "content": SYSTEM_MESSAGE},
{"role":"user", "content": user_message}
]
response = client.chat.completions.create(
model=model_name,
messages=messages,
tools=[
convert_to_openai_tool(Expense),
convert_to_openai_tool(ReportTool)]
)
Next, we’ll need a new function to read the arguments of the function call from the response:
def parse_function_args(response):
message = response.choices[0].message
return json.loads(message.tool_calls[0].function.arguments)
print(parse_function_args(response))
{'description': 'Coffee',
'net_amount': 5,
'gross_amount': None,
'tax_rate': 0.2,
'date': '2023-10-06T12:00:00Z'}
As we can observe, we have encountered several issues in the execution:
- The gross_amount is not calculated.
- The date is hallucinated.
With that in mind. Let’s try to resolve this issues and optimize our agent workflow.
2. Optimize Tool handling
To optimize the agent workflow, I find it crucial to prioritize workflow over prompt engineering. While it might be tempting to fine-tune the prompt so that the agent learns to use the tools provided perfectly and makes no mistakes, it’s more advisable to first adjust the tools and processes. When a typical error occurs, the initial consideration should be how to fix it code-based.
Handling Missing Information
Handling missing information effectively is an essential topic for creating robust and reliable agents. In the previous example, providing the agent with a tool like “get_current_date” is a workaround for specific scenarios. However, we must assume that missing information will occur in various contexts, and we cannot rely solely on prompt engineering and adding more tools to prevent the model from hallucinating missing information.
A simple workaround for this scenario is to modify the tool schema to treat all parameters as optional. This approach ensures that the agent only submits the parameters it knows, preventing unnecessary hallucination.
Therefore, let’s take a look at openai tool schema:
add_expense_tool = convert_to_openai_tool(Expense)
print(add_expense_tool)
{'type': 'function',
'function': {'name': 'Expense',
'description': '',
'parameters': {'type': 'object',
'properties': {'description': {'type': 'string'},
'net_amount': {'type': 'number'},
'gross_amount': {'type': 'number'},
'tax_rate': {'type': 'number'},
'date': {'type': 'string', 'format': 'date-time'}},
'required': ['description',
'net_amount',
'gross_amount',
'tax_rate',
'date']}}}
As we can see we have special key required , which we need to remove. Here’s how you can adjust the add_expense_tool schema to make parameters optional by removing the required key:
del add_expense_tool["function"]["parameters"]["required"]
Designing Tool class
Next, we can design a Tool class that initially checks the input parameters for missing values. We create the Tool class with two methods: .run(), .validate_input(), and a property openai_tool_schema, where we manipulate the tool schema by removing required parameters. Additionally, we define the ToolResult BaseModel with the fields content and success to serve as the output object for each tool run.
from pydantic import BaseModel
from typing import Type, Callable, Dict, Any, List
class ToolResult(BaseModel):
content: str
success: bool
class Tool(BaseModel):
name: str
model: Type[BaseModel]
function: Callable
validate_missing: bool = False
class Config:
arbitrary_types_allowed = True
def run(self, **kwargs) -> ToolResult:
if self.validate_missing:
missing_values = self.validate_input(**kwargs)
if missing_values:
content = f"Missing values: {', '.join(missing_values)}"
return ToolResult(content=content, success=False)
result = self.function(**kwargs)
return ToolResult(content=str(result), success=True)
def validate_input(self, **kwargs) -> List[str]:
missing_values = []
for key in self.model.__fields__.keys():
if key not in kwargs:
missing_values.append(key)
return missing_values
@property
def openai_tool_schema(self) -> Dict[str, Any]:
schema = convert_to_openai_tool(self.model)
if "required" in schema["function"]["parameters"]:
del schema["function"]["parameters"]["required"]
return schema
The Tool class is a crucial component in the AI agent’s workflow, serving as a blueprint for creating and managing various tools that the agent can utilize to perform specific tasks. It is designed to handle input validation, execute the tool’s function, and return the result in a standardized format.
The Tool class key components:
- name: The name of the tool.
- model: The Pydantic BaseModel that defines the input schema for the tool.
- function: The callable function that the tool executes.
- validate_missing: A boolean flag indicating whether to validate missing input values (default is False).
The Tool class two main methods:
- run(self, **kwargs) -> ToolResult: This method is responsible for executing the tool’s function with the provided input arguments. It first checks if validate_missing is set to True. If so, it calls the validate_input() method to check for missing input values. If any missing values are found, it returns a ToolResult object with an error message and success set to False. If all required input values are present, it proceeds to execute the tool’s function with the provided arguments and returns a ToolResult object with the result and success set to True.
- validate_input(self, **kwargs) -> List[str]: This method compares the input arguments passed to the tool with the expected input schema defined in the model. It iterates over the fields defined in the model and checks if each field is present in the input arguments. If any field is missing, it appends the field name to a list of missing values. Finally, it returns the list of missing values.
The Tool class also has a property called openai_tool_schema, which returns the OpenAI tool schema for the tool. It uses the convert_to_openai_tool() function to convert the model to the OpenAI tool schema format. Additionally, it removes the “required” key from the schema, making all input parameters optional. This allows the agent to provide only the available information without the need to hallucinate missing values.
By encapsulating the tool’s functionality, input validation, and schema generation, the Tool class provides a clean and reusable interface for creating and managing tools in the AI agent’s workflow. It abstracts away the complexities of handling missing values and ensures that the agent can gracefully handle incomplete information while executing the appropriate tools based on the available input.
Testing Missing Information Handling
Next, we will extend our OpenAI API call. We want the client to utilize our tool, and our response object to directly trigger a tool.run(). For this, we need to initialize our tools in our newly created Tool class. We define two dummy functions which return a success message string.
def add_expense_func(**kwargs):
return f"Added expense: {kwargs} to the database."
add_expense_tool = Tool(
name="add_expense_tool",
model=Expense,
function=add_expense_func
)
def report_func(report: str = None):
return f"Reported: {report}"
report_tool = Tool(
name="report_tool",
model=ReportTool,
function=report_func
)
tools = [add_expense_tool, report_tool]
Next we define our helper function, that each take client response as input an help to interact with out tools.
def get_tool_from_response(response, tools=tools):
tool_name = response.choices[0].message.tool_calls[0].function.name
for t in tools:
if t.name == tool_name:
return t
raise ValueError(f"Tool {tool_name} not found in tools list.")
def parse_function_args(response):
message = response.choices[0].message
return json.loads(message.tool_calls[0].function.arguments)
def run_tool_from_response(response, tools=tools):
tool = get_tool_from_response(response, tools)
tool_kwargs = parse_function_args(response)
return tool.run(**tool_kwargs)
Now, we can execute our client with our new tools and use the run_tool_from_response function.
response = client.chat.completions.create(
model=model_name,
messages=messages,
tools=[tool.openai_tool_schema for tool in tools]
)
tool_result = run_tool_from_response(response, tools=tools)
print(tool_result)
content='Missing values: gross_amount, date' success=False
Perfectly, we now see our tool indicating that missing values are present. Thanks to our trick of sending all parameters as optional, we now avoid hallucinated parameters.
3. Building the Agent Workflow
Our process, as it stands, doesn’t yet represent a true agent. So far, we’ve only executed a single API tool call. To transform this into an agent workflow, we need to introduce an iterative process that feeds the results of tool execution back to the client. The basic process should like this:
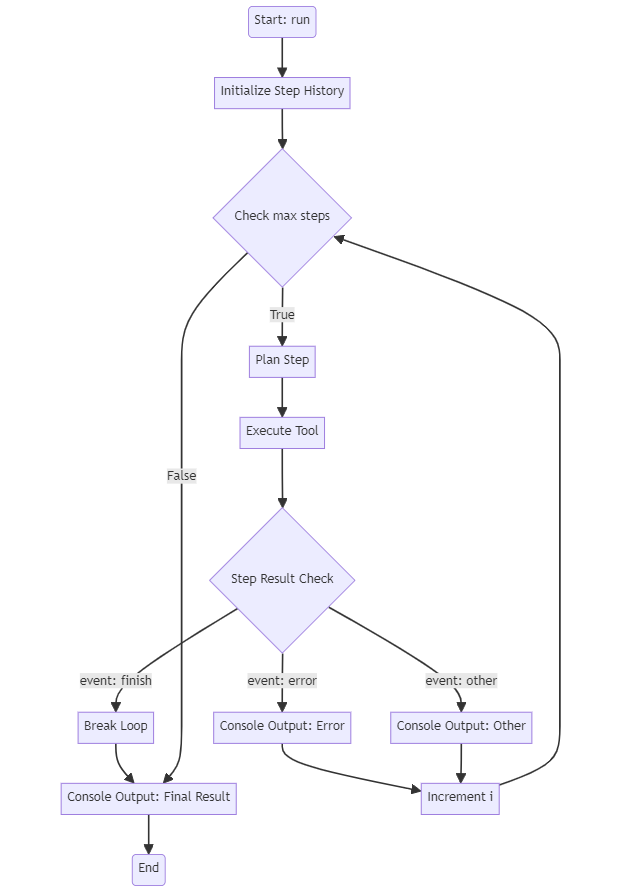
Let’s get started by creating a new OpenAIAgent class:
class StepResult(BaseModel):
event: str
content: str
success: bool
class OpenAIAgent:
def __init__(
self,
tools: list[Tool],
client: OpenAI,
system_message: str = SYSTEM_MESSAGE,
model_name: str = "gpt-3.5-turbo-0125",
max_steps: int = 5,
verbose: bool = True
):
self.tools = tools
self.client = client
self.model_name = model_name
self.system_message = system_message
self.step_history = []
self.max_steps = max_steps
self.verbose = verbose
def to_console(self, tag: str, message: str, color: str = "green"):
if self.verbose:
color_prefix = Fore.__dict__[color.upper()]
print(color_prefix + f"{tag}: {message}{Style.RESET_ALL}")
Like our ToolResultobject, we’ve defined a StepResult as an object for each agent step. We then defined the __init__ method of the OpenAIAgent class and a to_console() method to print our intermediate steps and tool calls to the console, using colorama for colorful printouts. Next, we define the heart of the agent, the run() and the run_step() method.
class OpenAIAgent:
# ... __init__...
# ... to_console ...
def run(self, user_input: str):
openai_tools = [tool.openai_tool_schema for tool in self.tools]
self.step_history = [
{"role":"system", "content":self.system_message},
{"role":"user", "content":user_input}
]
step_result = None
i = 0
self.to_console("START", f"Starting Agent with Input: {user_input}")
while i < self.max_steps:
step_result = self.run_step(self.step_history, openai_tools)
if step_result.event == "finish":
break
elif step_result.event == "error":
self.to_console(step_result.event, step_result.content, "red")
else:
self.to_console(step_result.event, step_result.content, "yellow")
i += 1
self.to_console("Final Result", step_result.content, "green")
return step_result.content
In the run() method, we start by initializing the step_history, which will serve as our message memory, with the predefined system_message and the user_input. Then we start our while loop, where we call run_step during each iteration, which will return a StepResult Object. We identify if the agent finished his task or if an error occurred, which will be passed to the console as well.
class OpenAIAgent:
# ... __init__...
# ... to_console ...
# ... run ...
def run_step(self, messages: list[dict], tools):
# plan the next step
response = self.client.chat.completions.create(
model=self.model_name,
messages=messages,
tools=tools
)
# add message to history
self.step_history.append(response.choices[0].message)
# check if tool call is present
if not response.choices[0].message.tool_calls:
return StepResult(
event="Error",
content="No tool calls were returned.",
success=False
)
tool_name = response.choices[0].message.tool_calls[0].function.name
tool_kwargs = parse_function_args(response)
# execute the tool call
self.to_console(
"Tool Call", f"Name: {tool_name}nArgs: {tool_kwargs}", "magenta"
)
tool_result = run_tool_from_response(response, tools=self.tools)
tool_result_msg = self.tool_call_message(response, tool_result)
self.step_history.append(tool_result_msg)
if tool_result.success:
step_result = StepResult(
event="tool_result",
content=tool_result.content,
success=True)
else:
step_result = StepResult(
event="error",
content=tool_result.content,
success=False
)
return step_result
def tool_call_message(self, response, tool_result: ToolResult):
tool_call = response.choices[0].message.tool_calls[0]
return {
"tool_call_id": tool_call.id,
"role": "tool",
"name": tool_call.function.name,
"content": tool_result.content,
}
Now we’ve defined the logic for each step. We first obtain a response object by our previously tested client API call with tools. We append the response message object to our step_history. We then verify if a tool call is included in our response object, otherwise, we return an error in our StepResult. Then we log our tool call to the console and run the selected tool with our previously defined method run_tool_from_response(). We also need to append the tool result to our message history. OpenAI has defined a specific format for this purpose, so that the Model knows which tool call refers to which output by passing a tool_call_id into our message dict. This is done by our method tool_call_message(), which takes the response object and the tool_result as input arguments. At the end of each step, we assign the tool result to a StepResult Object, which also indicates if the step was successful or not, and return it to our loop in run().
4. Running the Agent
Now we can test our agent with the previous example, directly equipping it with a get_current_date_tool as well. Here, we can set our previously defined validate_missing attribute to False, since the tool doesn’t need any input argument.
class DateTool(BaseModel):
x: str = None
get_date_tool = Tool(
name="get_current_date",
model=DateTool,
function=lambda: datetime.now().strftime("%Y-%m-%d"),
validate_missing=False
)
tools = [
add_expense_tool,
report_tool,
get_date_tool
]
agent = OpenAIAgent(tools, client)
agent.run("I have spent 5$ on a coffee today please track my expense. The tax rate is 0.2.")
START: Starting Agent with Input:
"I have spend 5$ on a coffee today please track my expense. The tax rate is 0.2."
Tool Call: get_current_date
Args: {}
tool_result: 2024-03-15
Tool Call: add_expense_tool
Args: {'description': 'Coffee expense', 'net_amount': 5, 'tax_rate': 0.2, 'date': '2024-03-15'}
error: Missing values: gross_amount
Tool Call: add_expense_tool
Args: {'description': 'Coffee expense', 'net_amount': 5, 'tax_rate': 0.2, 'date': '2024-03-15', 'gross_amount': 6}
tool_result: Added expense: {'description': 'Coffee expense', 'net_amount': 5, 'tax_rate': 0.2, 'date': '2024-03-15', 'gross_amount': 6} to the database.
Error: No tool calls were returned.
Tool Call: Name: report_tool
Args: {'report': 'Expense successfully tracked for coffee purchase.'}
tool_result: Reported: Expense successfully tracked for coffee purchase.
Final Result: Reported: Expense successfully tracked for coffee purchase.
Following the successful execution of our prototype agent, it’s noteworthy to emphasize how effectively the agent utilized the designated tools according to plan. Initially, it invoked the get_current_date_tool, establishing a foundational timestamp for the expense entry. Subsequently, when attempting to log the expense via the add_expense_tool, our intelligently designed tool class identified a missing gross_amount—a crucial piece of information for accurate financial tracking. Impressively, the agent autonomously resolved this by calculating the gross_amount using the provided tax_rate.
It’s important to mention that in our test run, the nature of the input expense — whether the $5 spent on coffee was net or gross — wasn’t explicitly specified. At this juncture, such specificity wasn’t required for the agent to perform its task successfully. However, this brings to light a valuable insight for refining our agent’s understanding and interaction capabilities: Incorporating such detailed information into our initial system prompt could significantly enhance the agent’s accuracy and efficiency in processing expense entries. This adjustment would ensure a more comprehensive grasp of financial data right from the outset.
Key Takeaways
- Iterative Development: The project underscores the critical nature of an iterative development cycle, fostering continuous improvement through feedback. This approach is paramount in AI, where variability is the norm, necessitating an adaptable and responsive development strategy.
- Handling Uncertainty: Our journey highlighted the significance of elegantly managing ambiguities and errors. Innovations such as optional parameters and rigorous input validation have proven instrumental in enhancing both the reliability and user experience of the agent.
- Customized Agent Workflows for Specific Tasks: A key insight from this work is the importance of customizing agent workflows to suit particular use cases. Beyond assembling a suite of tools, the strategic design of tool interactions and responses is vital. This customization ensures the agent effectively addresses specific challenges, leading to a more focused and efficient problem-solving approach.
The journey we have embarked upon is just the beginning of a larger exploration into the world of AI agents and their applications in various domains. As we continue to push the boundaries of what’s possible with AI, we invite you to join us on this exciting adventure. By building upon the foundation laid in this article and staying tuned for the upcoming enhancements, you will witness firsthand how AI agents can revolutionize the way businesses and individuals handle their data and automate complex tasks.
Together, let us embrace the power of AI and unlock its potential to transform the way we work and interact with technology. The future of AI is bright, and we are at the forefront of shaping it, one reliable agent at a time.
Looking Ahead
As we continue our journey in exploring the potential of AI agents, the upcoming articles will focus on expanding the capabilities of our prototype and integrating it with real-world systems. In the next article, we will dive into designing a robust project structure that allows our agent to interact seamlessly with SQL databases. By leveraging the agent developed in this article, we will demonstrate how AI can efficiently manage and manipulate data stored in databases, opening up a world of possibilities for automating data-related tasks.
Building upon this foundation, the third article in the series will introduce advanced query features, enabling our agent to handle more complex data retrieval and manipulation tasks. We will also explore the concept of a routing agent, which will act as a central hub for managing multiple subagents, each responsible for interacting with specific database tables. This hierarchical structure will allow users to make requests in natural language, which the routing agent will then interpret and direct to the appropriate subagent for execution.
To further enhance the practicality and security of our AI-powered system, we will introduce a role-based access control system. This will ensure that users have the appropriate permissions to access and modify data based on their assigned roles. By implementing this feature, we can demonstrate how AI agents can be deployed in real-world scenarios while maintaining data integrity and security.
Through these upcoming enhancements, we aim to showcase the true potential of AI agents in streamlining data management processes and providing a more intuitive and efficient way for users to interact with databases. By combining the power of natural language processing, database management, and role-based access control, we will be laying the groundwork for the development of sophisticated AI assistants that can revolutionize the way businesses and individuals handle their data.
Stay tuned for these exciting developments as we continue to push the boundaries of what’s possible with AI agents in data management and beyond.
Source Code
Additionally, the entire source code for the projects covered is available on GitHub. You can access it at https://github.com/elokus/AgentDemo.
Leverage OpenAI Tool calling: Building a reliable AI Agent from Scratch was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Leverage OpenAI Tool calling: Building a reliable AI Agent from Scratch
Go Here to Read this Fast! Leverage OpenAI Tool calling: Building a reliable AI Agent from Scratch