Evaluating the evolution and application of language models on real world tasks

In the realm of education, the best exams are those that challenge students to apply what they’ve learned in new and unpredictable ways, moving beyond memorizing facts to demonstrate true understanding. Our evaluations of language models should follow the same pattern. As we see new models flood the AI space everyday whether from giants like OpenAI and Anthropic, or from smaller research teams and universities, its critical that our model evaluations dive deeper than performance on standard benchmarks. Emerging research suggests that the benchmarks we’ve relied on to gauge model capability are not as reliable as we once thought. In order for us to champion new models appropriately, our benchmarks must evolve to be as dynamic and complex as the real-world challenges we’re asking these models and emerging AI agent architectures to solve.
In this article we will explore the complexity of language model evaluation by answering the following questions:
- How are language models evaluated today?
- How reliable are language models that excel on benchmarks?
- Can language models and AI agents translate knowledge into action?
- Why should language models (or foundation models) master more than text?
So, how are language models evaluated today?
Today most models either Large Language Models (LLMs) or Small Language Models (SLMs) are evaluated on a common set of benchmarks including the Massive Multitask Language Understanding (MMLU), Grade School Math (GSM8K), and Big-Bench Hard (BBH) datasets amongst others.
To provide a deeper understanding of the types of tasks each benchmark evaluates, here are some sample questions from each dataset:
- MMLU: Designed to measure information the model learned during pre-training across a variety of STEM and humanities based subjects and difficulty levels from elementary to advanced professional understanding using multiple choice questions.
Example college medicine question in MMLU: “In a genetic test of a newborn, a rare genetic disorder is found that has X-linked recessive transmission. Which of the following statements is likely true regarding the pedigree of the disorder? A. All descendants on the maternal side will have the disorder B. Females will be approximately twice as affected as males in their family. C. All daughters of an affected male will be affected. D. There will be equal distribution of males and females affected.” (Correct answer is C) [2] - GSM8K: Language models typically struggle to solve math questions, the GSM8K dataset evaluates a models ability to reason and solve math problems using 8.5k diverse grade school math problems.
Example: “Dean’s mother gave him $28 to go to the grocery store. Dean bought 6 toy cars and 5 teddy bears. Each toy car cost $12 and each teddy bear cost $1. His mother then feels generous and decides to give him and extra $10. How much money does Dean have left?” [3] - BBH: This dataset consists of 23 tasks from the Big Bench dataset which language models have traditionally struggled to solve. These tasks generallly require multi step reasoning to successfully complete the task.
Example: “If you follow these instructions, do you return to the starting point? Turn left. Turn right. Take 5 steps. Take 4 steps. Turn around. Take 9 steps. Options: — Yes — No” [4]
Anthropic’s recent announcement of Claude-3 shows their Opus model surpassing GPT-4 as the leading model on a majority of the common benchmarks. For example, Claude-3 Opus performed at 86.8% on MMLU, narrowly surpassing GPT-4 which scored 86.4%. Claude-3 Opus also scored 95% on GSM8K and 86.8% on BBH compared to GPT-4’s 92% and 83.1% respectively [1].
While the performance of models like GPT-4 and Claude on these benchmarks is impressive, these tasks are not always representative of the types of challenges business want to solve. Additionally, there is a growing body of research suggesting that models are memorizing benchmark questions rather than understanding them. This does not necessarily mean that the models aren’t capable of generalizing to new tasks, we see LLMs and SLMs perform amazing feats everyday, but it does mean we should reconsider how we’re evaluating, scoring, and promoting models.
How reliable are language models that excel on benchmarks?
Research from Microsoft, the Institute of Automation CAS, and the University of Science and Technology, China demonstrates how when asking various language models rephrased or modified benchmark questions, the models perform significantly worse than when asked the same benchmark question with no modification. For the purposes of their research as exhibited in the paper, DyVal 2, the researchers took questions from benchmarks like MMLU and modified them by either rephrasing the question, adding an extra answer to the question, rephrasing the answers, permuting the answers, or adding extra content to the question. When comparing model performance on the “vanilla” dataset compared to the modified questions they saw a decrease in performance, for example GPT-4 scored 84.4 on the vanilla MMLU questions and 68.86 on the modified MMLU questions [5].

Similarly, research from the Department of Computer Science at the University of Arizona indicates that there is a significant amount of data contamination in language models [6]. Meaning that the information in the benchmarks is becoming part of the models training data, effectively making the benchmark scores irrelevant since the models are being tested on information they are trained on.
Additional research from Fudan University, Tongji University, and Alibaba highlights the need for self-evolving dynamic evaluations for AI agents to combat the issues of data contamination and benchmark memorization [7]. These dynamic benchmarks will help prevent models from memorizing or learning information during pre-training that they’d later be tested on. Although a recurring influx of new benchmarks may create challenges when comparing an older model to a newer model, ideally these benchmarks will mitigate issues of data contamination and make it easier to gauge how well a model understands topics from training.
When evaluating model capability for a particular problem, we need to grasp both how well the model understands information learned during pretraining and how well it can generalize to novel tasks or concepts beyond it’s training data.
Can language models and AI agents translate knowledge into action?
As we look to use models as AI agents to perform actions on our behalf, whether that’s booking a vacation, writing a report, or researching new topics for us, we’ll need additional benchmarks or evaluation mechanisms that can assess the reliability and accuracy of these agents. Most businesses looking to harness the power of foundation models require giving the model access to a variety of tools integrated with their unique data sources and require the model to reason and plan when and how to use the tools available to them effectively. These types of tasks are not represented in many traditional LLM benchmarks.

To address this gap, many research teams are creating their own benchmarks and frameworks that evaluate agent performance on tasks involving tool use and knowledge outside of the model’s training data. For example, the authors of AgentVerse evaluated how well teams of agents could perform real world tasks involving event planning, software development, and consulting. The researchers created their own set of 10 test tasks which were manually evaluated to determine if the agents performed the right set of actions, used the proper tools, and got to an accurate result. They found that teams of agents who operated in a cycle with defined stages for agent recruitment, task planning, independent task execution, and subsequent evaluation lead to superior outcomes compared to independent agents [8].
Beyond single modalities and into the real world. Why should language models (or foundation models) master more than text?
In my opinion the emerging agent architectures and benchmarks are a great step towards understanding how well language models will perform on business oriented problems, but one limitation is that most are still text focused. As we consider the world and the dynamic nature of most jobs, we will need agent systems and models that evaluate both performance on text based tasks as well as visual and auditory tasks together. The AlgoPuzzleVQA dataset is one example of evaluating models on their ability to both reason, read, and visually interpret mathematical and algorithmic puzzles [9].
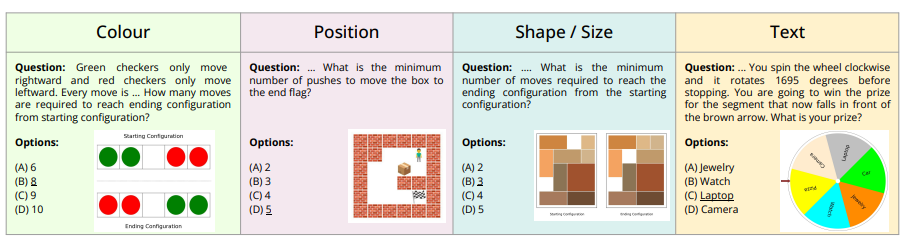
While businesses may not be interested in how well a model can solve a puzzle, it is still a step in the right direction for understanding how well models can reason about multimodal information.
Conclusion
As we continue adopting foundation models in our daily routines and professional endeavors, we need additional evaluation options that mirror real world problems. Dynamic and multimodal benchmarks are one key component of this. However, as we introduce additional agent frameworks and architectures with many AI agents collaborating to solve a problem, evaluation and comparison across models and frameworks becomes even more challenging. The true measure of foundation models lies not in their ability to conquer standardized tests, but in their capacity to understand, adapt, and act within the complex and often unpredictable real world. By changing how we evaluate language models, we challenge these models to evolve from text-based intellects and benchmark savants to comprehensive thinkers capable of tackling multifaceted (and multimodal) challenges.
Interested in discussing further or collaborating? Reach out on LinkedIn!
Are Language Models Benchmark Savants or Real-World Problem Solvers? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Are Language Models Benchmark Savants or Real-World Problem Solvers?
Go Here to Read this Fast! Are Language Models Benchmark Savants or Real-World Problem Solvers?