

This article is the second in a series about cleaning data using Large Language Models (LLMs), with a focus on identifying errors in tabular data sets.
The sketch outlines the methodology we’ll explore in this article, which focuses on evaluating the Data Dirtiness Score of a tabular data set with minimal human involvement.
The Data Dirtiness Score
Readers are encouraged to first review the introductory article on the Data Dirtiness Score, which explains the key assumptions and demonstrates how to calculate this score.
As a quick refresher, the Data Dirtiness Score estimates the expected proportion of cells in a data set that contain errors. Here are the key hypotheses behind this metric:
- Data errors are related to violated constraints.
- If there are no expectations, there is no effect on the score.
- Data problems can be pinpointed to specific cells.
- Each data error is assigned a confidence score.
- Every cell has an equal impact on the overall score.
The initial step in this process involves identifying and cataloguing data inaccuracies present within the data set.
The Importance of Detecting Data Quality Issues Automatically
Detecting data issues is crucial in the process but challenging due to several factors:
- High Human Labelling Cost: Identifying data errors often needs significant input from data professionals (like scientists, engineers, and analysts) or subject matter experts (SMEs). This requires a lot of time and is expensive.
- Lack of Enthusiasm Among Data Practitioners for this Grunt Work: It’s no secret that many in the field view data cleaning as a less appealing aspect of their work. Seen as a precursor to more engaging activities such as modelling, building modern data stacks or answering business queries, data cleaning often falls lower on the priority list, leading to procrastination or, in some cases, completely ignored until critical issues arise.
- SME Limitations: SMEs have valuable knowledge but might lack technical skills like SQL or programming. While no-code and low-code tools help to some extent, they haven’t been fully adopted and might not cover all data management aspects, such as version control.
- The Expertise Gap: Effective data cleaning transcends basic skill sets, requiring specialised expertise. The lack of training and the general disinterest in data preparation mean that many practitioners may only identify superficial errors, missing more complex issues that require a deeper understanding of data cleaning.
Despite the inherent challenges, advancements in the field of Large Language Models (LLMs) offer promising solutions for automating the identification of straightforward data issues and uncovering more intricate data quality problems.
Data Error Detection powered by LLMs
Large language models are becoming invaluable tools in automating the detection of data quality issues, serving as an efficient starting point for a productive human-in-the-loop iterative process. Models, such as those discussed in papers like Jellyfish: A Large Language Model for Data Preprocessing, Can language models automate data wrangling? and Large Language Models as Data Preprocessors, demonstrate their potential to automate constraint generation and data error detection. This automation doesn’t replace human intervention but rather enhances it, allowing for the review and adjustment of automated constraints by either addressing issues directly or modifying confidence scores to reflect the uncertainty inherent in data error detection.
LLMs are particularly well-suited for detecting data quality issues due to their extensive training on a diverse range of internet content, including a vast array of domain knowledge and numerous examples of code reviews related to data quality issues. This training enables LLMs to identify data errors based on textual content without the need for explicitly defined rules. By converting tabular data sets into plain text (called serialisation), LLMs can scrutinise data much like a team of experienced humans, leveraging their “compressed” internet knowledge to pinpoint errors. This extensive training allows them to identify potential errors in human-readable data sets, such as CSV files, with a level of intuition that mimics human expertise. Moreover, any gaps in domain-specific knowledge can be bridged through techniques like Retrieval-Augmented Generation (RAG) or by tailoring the model’s prompts to the specific nature of the data set.
Another key advantage of employing LLMs in data error detection is their ability to handle the inherent uncertainty associated with data quality issues. Not all errors are straightforward, and even experts can sometimes disagree on what constitutes a data issue. LLMs can assign confidence scores to their findings, like a human does based on a mix of intuition and experience, reflecting the estimated likelihood of an error.
The challenge of generalising error detection across diverse data sets and potential issues is considerable. Traditional methods often resort to an extensive set of decision rules or a combination of specialised machine learning models to address various scenarios, such as checking the validity of addresses and phone numbers or anomaly detection. This is where LLMs shine, offering a more adaptable and less labour-intensive alternative. Their ability to understand and identify a wide range of data quality issues without extensive rule-based systems or domain-specific models makes them an invaluable tool. The analogy with the advantages of Machine Learning approaches over traditional business rules or statistical methods is quite intriguing. The adoption of machine learning has been driven by its relative ease of use and adaptability across different use cases, requiring less domain-specific knowledge and time to implement.
Next, we will demonstrate this approach through a practical example.
A Case Study
In the previous article, we explored the concept of the Data Dirtiness Score using a data set example from the book Cleaning Data for Effective Data Science. The data set in question is as follows:
Student#,Last Name,First Name,Favorite Color,Age
1,Johnson,Mia,periwinkle,12
2,Lopez,Liam,blue,green,13
3,Lee,Isabella,,11
4,Fisher,Mason,gray,-1
5,Gupta,Olivia,9,102
6,,Robinson,,Sophia,,blue,,12
Data errors were already pointed out. Now, we want to explore how we can use a Large Language Model, specifically GPT-4, to automatically find these errors. This new method offers a modern way to spot issues in data sets but comes with possible risks such as privacy concerns when using external APIs. However, this can work with any LLMs, not just GPT-4, although the effectiveness might vary depending on the model’s capabilities.
Preliminary Step: Retrieve Table Annotation
To assist the model in identifying data inconsistencies, it’s beneficial to provide additional context about the data frame. This is precisely the role of a data catalog, which, although a broad topic, we will simplify to focus solely on the essential context information that a LLM requires to detect data errors when examining batches of data set rows.
The key metadata needed includes:
- An overview of the table, including its description and purpose.
- A clear understanding of each column’s meaning and type.
Given the frequent absence of data catalogs or reliable documentation in organisations, we’ll explore how to use LLMs to speed up this process. This process is known as Table Annotation, which involves identifying semantic information about table elements, including columns, their relationships, and the entities within the cells. For further details, refer to sources such as Column Type Annotation using ChatGPT, Annotating Columns with Pre-trained Language Models, or SOTAB: The WDC Schema.org Table Annotation Benchmark.
Here’s the prompt I use:
Analyse the table below and provide schema annotations based on Schema.org standards.
Student#,Last Name,First Name,Favorite Color,Age
1,Johnson,Mia,periwinkle,12
2,Lopez,Liam,blue,green,13
3,Lee,Isabella,,11
4,Fisher,Mason,gray,-1
5,Gupta,Olivia,9,102
6,,Robinson,,Sophia,,blue,,12
Follow these steps:
1. Identify the overall semantic type of the table.
2. Provide a short description of each column.
3. Annotate each column with its semantic type from Schema.org.
4. Determine the most suitable data type for each column (after data cleaning).
Summarise the table schema as follows:
- Table Semantic Type: <type>
- Column: <name>, Description: <description>, Semantic Type: <Schema.org type>, Pandas Type: <Pandas data type>
In the prompt instructions, I direct the model to analyse the provided table (or an overview of the table) and to suggest annotations following the Schema.org standards. Specifically, the output should include:
- The table’s semantic type
- A brief description of each column
- The column’s annotation type from Schema.org, where applicable
- The ideal or best-suited data types for each column, regardless of data issues in the provided text serialisation
The response is then formatted to provide a clear and structured summary that can be reused as context in subsequent prompts:
Summarise the table schema as follows:
- Table Semantic Type: <type>
- Column: <name>, Description: <description>, Semantic Type: <Schema.org type>, Pandas Type: <Pandas data type>
The table is incorporated using a {table} placeholder in the prompt. The typical method involves converting tabular data into text through serialisation, as discussed in Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding — A Survey.
Here is a sample response from GPT-4:
- Table Semantic Type: Person
- Column: Student#, Description: Unique identifier for each student, Semantic Type: identifier, Pandas Type: int
- Column: Last Name, Description: Family name of the student, Semantic Type: familyName, Pandas Type: string
- Column: First Name, Description: Given name of the student, Semantic Type: givenName, Pandas Type: string
- Column: Favorite Color, Description: Preferred color of the student, Semantic Type: color (custom), Pandas Type: string (or list if cleaned for multiple values)
- Column: Age, Description: Age of the student, Semantic Type: age, Pandas Type: int (after cleaning invalid entries)
Responses may vary slightly but are generally consistent for such a straightforward example. The aim here is to accelerate the initial process rather than fully automate it. Thus, this can be seen as a preliminary draft, which can then be refined with insights from our knowledge and external context from subject matter experts (SMEs).
Now, with some context about the table, let’s explore how to automatically identify data quality issues.
Sniffing Data Errors with LLMs
To start, I suggest a prompt that will help identify data quality issues in a given table.
Task: Analyse the provided table to identify and document data quality issues.
Below are common data quality issues to guide your analysis. However, you may also identify other relevant issues:
- Ingestion errors
- Typecasting issues
- Duplicates
- Date parsing issues
- Character encoding problems
- Missing values
- Typos/spelling mistakes
- Anomalies/outliers
- Conversion errors and inconsistent units
- Privacy concerns (e.g., exposed PII)
- Domain-specific errors (e.g., invalid formats for addresses, phone numbers, emails)
Instructions:
1. Examine silently the table and its metadata.
2. Line by line, identify potential data quality issues without coding.
3. Document each issue, including:
- Nature and description of the issue
- Expected correct state
- Violated constraint
- Confidence level in your assessment using ordinal categories: `low`, `medium`, `high` and `certain`.
- Specific location of the issue in the table (use 'None' for table-wide issues): Index and Column names.
Provided Data:
Table:
,Student#,Last Name,First Name,Favorite Color,Age
0,1,Johnson,Mia,periwinkle,12
1,2,Lopez,Liam,blue,green,13
2,3,Lee,Isabella,,11
3,4,Fisher,Mason,gray,-1
4,5,Gupta,Olivia,9,102
5,6,,Robinson,,Sophia,,blue,,12
Metadata:
- Table Semantic Type: Person
- Column: Student#, Description: Unique identifier for each student, Semantic Type: identifier, Pandas Type: int or string
- Column: Last Name, Description: Family name of the student, Semantic Type: familyName, Pandas Type: string
- Column: First Name, Description: Given name of the student, Semantic Type: givenName, Pandas Type: string
- Column: Favorite Color, Description: Preferred color of the student, Semantic Type: color (custom), Pandas Type: string (or list if cleaned for multiple values)
- Column: Age, Description: Age of the student, Semantic Type: age, Pandas Type: int (after cleaning invalid entries)
Detected Data Issues:
The initial part of the prompt sets the task’s objective and lists examples of common data issues, such as ingestion errors, duplicates, and privacy concerns, among others. This list is not exhaustive, and you’re encouraged to add more relevant types based on your table’s context to guide the analysis.
Next, the prompt details step-by-step instructions following a Chain-of-Thoughts approach, ensuring the model methodically analyses the table and its metadata before identifying data issues line by line, mirroring human analysis. This process is meant to be conducted without coding, to maintain simplicity and broad applicability. This is crucial because, although models like GPT-4 with analytics capabilities can perform useful iterative coding sessions, relying solely on textual analysis promotes generalisation.
Upon detecting a potential data issue, the prompt instructs documenting the following details:
- The nature and description of the issue
- The expected correct state
- The violated constraint
- A confidence level in the assessment using ordinal categories: low, medium, high and certain.
- The specific location of the issue in the table, using ‘None’ for table-wide issues, with Index and Column names for reference.
The table and its metadata are provided within the prompt, with an index added to each row to aid the model in pinpointing the exact locations of errors.
For large tables, this prompt can be applied in batches to cover the entire data set, with findings aggregated to identify all data quality issues.
Here is an example of the output this prompt can generate, formatted as a report detailing identified data issues, each with a description, expected state, violated constraint, confidence level, and location.
1. Issue: Incorrect value format in "Favorite Color" column
- Nature and Description: The entry "blue,green" in the "Favorite Color" column for the second row appears to contain two colors instead of one, suggesting a possible ingestion or data entry error.
- Expected Correct State: Each cell under the "Favorite Color" column should contain only one color.
- Violated Constraint: Single value constraint.
- Confidence Level: High
- Specific Location: Index 1, Column "Favorite Color"
2. Issue: Missing value in "Favorite Color" and "Age" columns
- Nature and Description: The third row has a missing value for "Favorite Color", and the sixth row has missing values for both "Last Name" and "Favorite Color".
- Expected Correct State: No missing values in any of the columns.
- Violated Constraint: Non-null constraint.
- Confidence Level: Certain
- Specific Location: Index 2, Column "Favorite Color"; Index 5, Columns "Last Name", "Favorite Color"
3. Issue: Negative value in "Age" column
- Nature and Description: The fourth row has an age of "-1", which is not possible and indicates a data entry error.
- Expected Correct State: Age values should be positive integers.
- Violated Constraint: Age value range (greater than 0).
- Confidence Level: Certain
- Specific Location: Index 3, Column "Age"
4. Issue: Misplaced values in "Favorite Color" and "Age" columns
- Nature and Description: In the fifth row, what appears to be an age ("9") is placed in the "Favorite Color" column, and an unlikely age ("102") is in the "Age" column, suggesting a possible shifting or misplacement of values.
- Expected Correct State: Age should be a reasonable positive integer, and favorite color should be a string denoting a color.
- Violated Constraint: Data type and value range constraint.
- Confidence Level: High
- Specific Location: Index 4, Columns "Favorite Color", "Age"
5. Issue: Inconsistent formatting in row entries
- Nature and Description: The sixth row contains additional commas, which might indicate incorrect splitting or entry of the data, leading to misalignment of the values with their respective columns.
- Expected Correct State: Each row should consistently follow the format defined by the column headers without extra delimiters.
- Violated Constraint: Data format and consistency constraint.
- Confidence Level: High
- Specific Location: Index 5, Entire row
The next step is converting these identified issues into a Python object for easier calculation of the Data Dirtiness Score.
Converting Identified Data Issues into the Correct Format
This section focuses on transforming the previously identified data issues from plain text descriptions into Python objects. These objects should adhere to the structure defined by the DataIssue class:
@dataclass
class DataIssue:
type_of_issue: str
expectation: str
constraint_violated: str
confidence_score: str # `low`, `medium`, `high` or `certain`
location: List[Tuple] # Cell positions as (Index, Column). Use None for row/column-wide issues.
Here is the prompt I use:
Task: Document data table issues using the provided `DataIssue` class.
For each identified issue and its description, document it using the provided `DataIssue` class structure.
```python
from dataclasses import dataclass
from typing import List, Tuple
@dataclass
class DataIssue:
type_of_issue: str
expectation: str
constraint_violated: str
confidence_score: str # `low`, `medium`, `high` or `certain`
location: List[Tuple] # Cell positions as (Index, Column). Use None for row/column-wide issues.
Instructions:
1. Review all identified issues provided and their descriptions silently.
2. For each issue, instantiate it using the provided `DataIssue` class structure.
3. Return only the code.
4. Once the code has been validated, stop generation.
Identified issues:
{issues_found}
Your code here:
The goal is to generate Python code representing each data issue as a DataIssue object without redundant text. The identified issues are injected into the prompt using the placeholder {issues_found}.
Example output:
issue1 = DataIssue(
type_of_issue="Incorrect value format",
expectation="Each cell under 'Favorite Color' should contain only one color",
constraint_violated="Single value constraint",
confidence_score="high",
location=[(1, "Favorite Color")]
)
issue2 = DataIssue(
type_of_issue="Missing value",
expectation="No missing values in any columns",
constraint_violated="Non-null constraint",
confidence_score="certain",
location=[(2, "Favorite Color"), (5, "Last Name"), (5, "Favorite Color")]
)
issue3 = DataIssue(
type_of_issue="Negative value",
expectation="Age values should be positive integers",
constraint_violated="Age value range (greater than 0)",
confidence_score="certain",
location=[(3, "Age")]
)
issue4 = DataIssue(
type_of_issue="Misplaced values",
expectation="Age should be a reasonable positive integer, and favorite color should be a string denoting a color",
constraint_violated="Data type and value range constraint",
confidence_score="high",
location=[(4, "Favorite Color"), (4, "Age")]
)
issue5 = DataIssue(
type_of_issue="Inconsistent formatting",
expectation="Each row should consistently follow the format defined by the column headers without extra delimiters",
constraint_violated="Data format and consistency constraint",
confidence_score="high",
location=[(5, None)] # None indicates entire row issue
)
The final step involves converting the location attribute from lists of tuples to numpy arrays, which is detailed in the appendix.
With all elements in place, we can now calculate the Data Dirtiness Score.
Calculation of the Data Dirtiness Score and Comparison with Ground Truth
Let’s revisit the function from the previous article, compute_data_dirtiness_score, which uses a list of DataIssue objects mentioned earlier.
compute_data_dirtiness_score(data_issues)
Data Dirtiness Score: 28.33%
Using the GPT-4 model, we estimated the score to be around 28% for this sample. This is fairly close to the “ground truth” score of 31.87%.
To understand the discrepancy between these scores, let’s delve into more detailed metrics on data issue detection. In addition to the overall score, we have matrices of cell issue probabilities for both the ground truth and the model’s estimates.
Below is the ground truth matrix, with columns and indices added for clarity:
Student# Last Name First Name Favorite Color Age
0 0.00 0.0 0.00 0.00 0.00
1 0.00 0.0 0.00 0.75 0.00
2 0.00 0.0 0.00 1.00 0.00
3 0.00 0.0 0.00 0.00 1.00
4 0.00 0.0 0.00 0.75 0.75
5 0.75 1.0 0.75 1.00 0.75
And here is the matrix of probabilities estimated by the model:
Student# Last Name First Name Favorite Color Age
0 0.0 0.0 0.00 0.0000 0.00
1 0.0 0.0 0.00 0.7500 0.00
2 0.0 0.0 0.00 1.0000 0.00
3 0.0 0.0 0.00 0.0000 1.00
4 0.0 0.0 0.25 0.8125 0.75
5 1.0 1.0 1.00 1.0000 1.00
Though the matrices appear similar at first glance, we can apply threshold-based metrics such as accuracy, recall, precision, and F1-score to get a clearer picture. These metrics provide a straightforward evaluation of the model’s performance by considering a cell problematic if the model’s likelihood exceeds 0. Here are the metrics obtained:
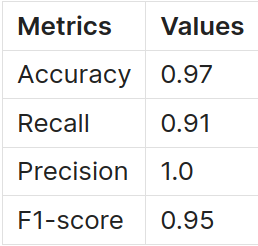
The model correctly identified 91% of problematic cells (recall), and all of its error predictions were accurate (precision).
The model missed one particular issue: “The Favorite Color and First Name fields might be swapped, considering Olivia can be both a name and a colour.” This was deemed improbable with a low confidence score, suggesting Olivia is more likely the First Name rather than the Favorite Color. Consequently, even though this potential issue was overlooked, its minimal confidence score lessened its impact on the overall Data Dirtiness Score. This explains why the two scores are relatively close despite this omission.
In summary, this approach, based on large language models (LLMs), offers a method for detecting data quality issues in a data frame. While this method may not yet be fully automated and might need manual adjustments, it’s hoped that it will expedite the detection of data errors and the calculation of the Data Dirtiness Score for tabular data sets.
Next Steps and Challenges
I use a two-step process to generate the issues as code. This is done because I have found this adds more stability over a one-in-all solution, i.e. scanning data set and metadatas and outputs data issues directly in right code format. This doesn’t imply it’s impossible, but I’ve chosen to divide this step into two phases to improve robustness for the time being.
An issue we face concerns managing large data sets, both in terms of the number of rows and columns. Despite recent advancements, LLMs still face limitations regarding the input context window and the length of generated content. These constraints limit the size of the table that can be serialised into the prompt for analysis and the length of the data issue report produced by the model. How to divide a data frame based on its size and the model’s capabilities is a question that arises.
In certain scenarios, the lack of general context can be problematic, such as when identifying duplicate rows in a database or detecting spelling errors without a broad understanding of the column values. For instance, in cases where duplicates are not straightforward, a common approach is Entity Matching. This technique is particularly useful in data cleaning processes and has seen advancements through the use of Large Language Models. Relevant research in this area includes studies like Entity Matching using Large Language Models and Can Foundation Models Wrangle Your Data?, along with Large Language Models as Data Preprocessors and Jellyfish: A Large Language Model for Data Preprocessing.
Ensemble methods in machine learning, which involve combining multiple models, can enhance performance and stability. This approach can be applied by running several LLMs simultaneously to identify issues in a data set. It’s beneficial to vary the prompts and settings for each LLM to ensure a diverse range of insights. Additionally, assigning specific error types, like spelling mistakes, to individual models can make the process more efficient. While this method can lead to more reliable results by dividing the task into smaller parts, it also increases both the cost and the complexity of the software. By gathering all the identified data issues, we can improve our chances of finding errors (increasing recall) but might also identify more false errors (decreasing precision). However, reviewing these identified errors is generally less time-consuming than finding them in the first place.
The ability of LLMs to interact directly with databases, similar to the code analysis capability in ChatGPT-4, opens up a wider range of possibilities for detecting data errors. A challenge here is automating this process, as the model may deviate from its intended path without sufficient guidance.
Despite all the challenges, it is already quite promising what we can achieve with such as simple approach. With more work on engineering, I hope we can very soon provide a more robust solution to cover larger data sets and fully automate the detection process.
The next article will discuss automated data repair or, at the very least, suggest solutions for repair pending validation.
References
- Data Dirtiness Score
- Jellyfish: A Large Language Model for Data Preprocessing
- Can language models automate data wrangling?
- Large Language Models as Data Preprocessors
- Column Type Annotation using ChatGPT
- Annotating Columns with Pre-trained Language Models
- SOTAB: The WDC Schema.org Table Annotation Benchmark
- Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding — A Survey
- Entity Matching using Large Language Models
Appendix
The section explains how to transform the location attribute of a DataIssue object, which comes from a LLM, into a different format. This transformation changes a list of tuples, which represent cell positions, into a numpyarray. This array acts as a mask for those cell positions.
Here’s a basic example using the Students data set:
create_mask_from_list_of_cell_positions(
shape=dataset_shape,
list_of_cell_positions=[(4, 'Favorite Color'), (4, 'Age')],
columns=columns
)
array([[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 0]], dtype=int8)
Below are the function definitions:
def validate_cell_position(
cell_position: Union[
Tuple[int, int], Tuple[None, int], Tuple[int, None], Tuple[None, None]
],
columns: List[str] = None,
) -> Tuple[int, int]:
"""
Validate the cell position and convert column names to indices if necessary.
"""
if not isinstance(cell_position, tuple):
raise ValueError("Cell position must be a tuple")
# Convert column name to index if columns are provided
if isinstance(cell_position[1], str):
if columns is None:
raise ValueError(
"Column names must be provided to create a mask based on column names"
)
column_index = columns.index(cell_position[1])
return (cell_position[0], column_index)
return cell_position
def set_mask_values(mask: np.ndarray, cell_position: Tuple[int, int]):
"""
Set values in the mask based on the cell position.
"""
row_index, col_index = cell_position
if row_index is None:
mask[:, col_index] = 1
elif col_index is None:
mask[row_index, :] = 1
else:
mask[row_index, col_index] = 1
def create_mask_from_list_of_cell_positions(
shape: Tuple[int, int],
list_of_cell_positions: List[Tuple],
columns: List[str] = None,
) -> np.ndarray:
"""
Create a mask array based on a list of cell positions.
"""
mask = np.zeros(shape=shape, dtype=np.int8)
for cell_position in list_of_cell_positions:
validated_position = validate_cell_position(cell_position, columns)
set_mask_values(mask, validated_position)
return mask
Automated Detection of Data Quality Issues was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Automated Detection of Data Quality Issues
Go Here to Read this Fast! Automated Detection of Data Quality Issues