Mechanistic Interpretability on prediction of repeated tokens
The development of large-scale language models, especially ChatGPT, has left those who have experimented with it, myself included, astonished by its remarkable linguistic prowess and its ability to accomplish diverse tasks. However, many researchers, including myself, while marveling at its capabilities, also find themselves perplexed. Despite knowing the model’s architecture and the specific values of its weights, we still struggle to comprehend why a particular sequence of inputs leads to a specific sequence of outputs.
In this blog post, I will attempt to demystify GPT2-small using mechanistic interpretability on a simple case: the prediction of repeated tokens.
Mechanistic Interpretability
Traditional mathematical tools for explaining machine learning models aren’t entirely suitable for language models.
Consider SHAP, a helpful tool for explaining machine learning models. It’s proficient at determining which feature significantly influenced the prediction of a good quality wine. However, it’s important to remember that language models make predictions at the token level, while SHAP values are mostly computed at the feature level, making them potentially unfit for tokens.
Moreover, Language Models (LLMs) have numerous parameters and inputs, creating a high-dimensional space. Computing SHAP values is costly even in low-dimensional spaces, and even more so in the high-dimensional space of LLMs.
Despite tolerating the high computational costs, the explanations provided by SHAP can be superficial. For instance, knowing that the term “potter” most influenced the output prediction due to the earlier mention of “Harry” doesn’t provide much insight. It leaves us uncertain about the part of the model or the specific mechanism responsible for such a prediction.
Mechanistic Interpretability offers a different approach. It doesn’t just identify important features or inputs for a model’s predictions. Instead, it sheds light on the underlying mechanisms or reasoning processes, helping us understand how a model makes its predictions or decisions.
Prediction of repeated tokens by GPT2-Small
We will be using GPT2-small for a simple task: predicting a sequence of repeated tokens. The library we will use is TransformerLens, which is designed for mechanistic interpretability of GPT-2 style language models.
gpt2_small: HookedTransformer = HookedTransformer.from_pretrained("gpt2-small")
We use the code above to load the GPT2-Small model and predict tokens on a sequence generated by a specific function. This sequence includes two identical token sequences, followed by the bos_token. An example would be “ABCDABCD” + bos_token when the seq_len is 3. For clarity, we refer to the sequence from the beginning to the seq_len as the first half, and the remaining sequence, excluding the bos_token, as the second half.
def generate_repeated_tokens(
model: HookedTransformer, seq_len: int, batch: int = 1
) -> Int[Tensor, "batch full_seq_len"]:
'''
Generates a sequence of repeated random tokens
Outputs are:
rep_tokens: [batch, 1+2*seq_len]
'''
bos_token = (t.ones(batch, 1) * model.tokenizer.bos_token_id).long() # generate bos token for each batch
rep_tokens_half = t.randint(0, model.cfg.d_vocab, (batch, seq_len), dtype=t.int64)
rep_tokens = t.cat([bos_token,rep_tokens_half,rep_tokens_half], dim=-1).to(device)
return rep_tokens
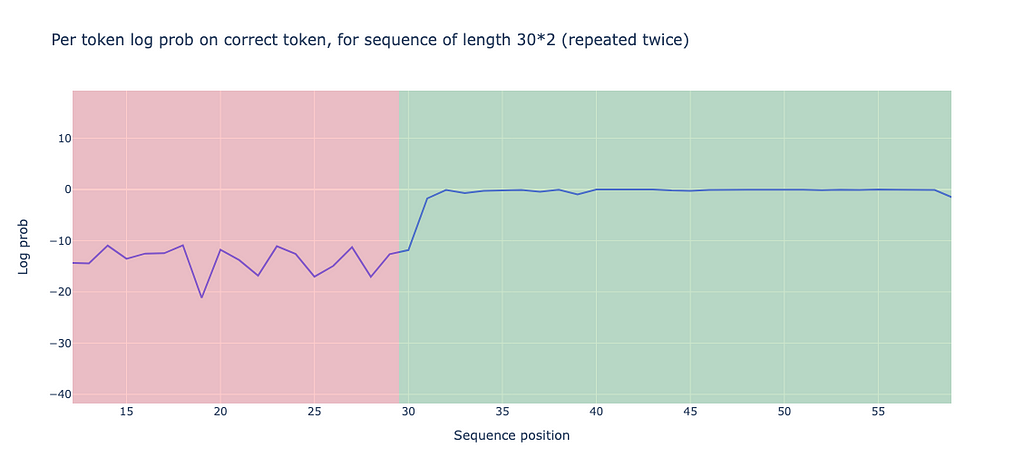
When we allow the model to run on the generated token, we find an interesting observation: the model performs significantly better on the second half of the sequence than on the first half. This is measured by the log probabilities on the correct tokens. To be precise, the performance on the first half is -13.898, while the performance on the second half is -0.644.
We can also calculate prediction accuracy, defined as the ratio of correctly predicted tokens (those identical to the generated tokens) to the total number of tokens. The accuracy for the first half sequence is 0.0, which is unsurprising since we’re working with random tokens that lack actual meaning. Meanwhile, the accuracy for the second half is 0.93, significantly outperforming the first half.
Induction Circuits
Finding induction head
The observation above might be explained by the existence of an induction circuit. This is a circuit that scans the sequence for prior instances of the current token, identifies the token that followed it previously, and predicts that the same sequence will repeat. For instance, if it encounters an ‘A’, it scans for the previous ‘A’ or a token very similar to ‘A’ in the embedding space, identifies the subsequent token ‘B’, and then predicts the next token after ‘A’ to be ‘B’ or a token very similar to ‘B’ in the embedding space.

This prediction process can be broken down into two steps:
- Identify the previous same (or similar) token. Every token in the second half of the sequence should “pay attention” to the token ‘seq_len’ places before it. For instance, the ‘A’ at position 4 should pay attention to the ‘A’ at position 1 if ‘seq_len’ is 3. We can call the attention head performing this task the “induction head.”
- Identify the following token ‘B’. This is the process of copying information from the previous token (e.g., ‘A’) into the next token (e.g., ‘B’). This information will be used to “reproduce” ‘B’ when ‘A’ appears again. We can call the attention head performing this task the “previous token head.”
These two heads constitute a complete induction circuit. Note that sometimes the term “induction head” is also used to describe the entire “induction circuit.” For more introduction of induction circuit, I highly recommend the article In-context learning and induction head which is a master piece!
Now, let’s identify the attention head and previous head in GPT2-small.
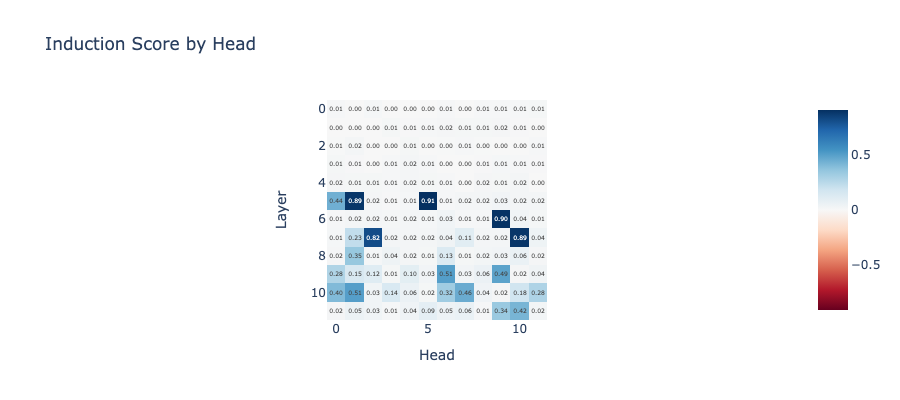
The following code is used to find the induction head. First, we run the model with 30 batches. Then, we calculate the mean value of the diagonal with an offset of seq_len in the attention pattern matrix. This method lets us measure the degree of attention the current token gives to the one that appears seq_len beforehand.
def induction_score_hook(
pattern: Float[Tensor, "batch head_index dest_pos source_pos"],
hook: HookPoint,
):
'''
Calculates the induction score, and stores it in the [layer, head] position of the `induction_score_store` tensor.
'''
induction_stripe = pattern.diagonal(dim1=-2, dim2=-1, offset=1-seq_len) # src_pos, des_pos, one position right from seq_len
induction_score = einops.reduce(induction_stripe, "batch head_index position -> head_index", "mean")
induction_score_store[hook.layer(), :] = induction_score
seq_len = 50
batch = 30
rep_tokens_30 = generate_repeated_tokens(gpt2_small, seq_len, batch)
induction_score_store = t.zeros((gpt2_small.cfg.n_layers, gpt2_small.cfg.n_heads), device=gpt2_small.cfg.device)
rep_tokens_30,
return_type=None,
pattern_hook_names_filter,
induction_score_hook
)]
)
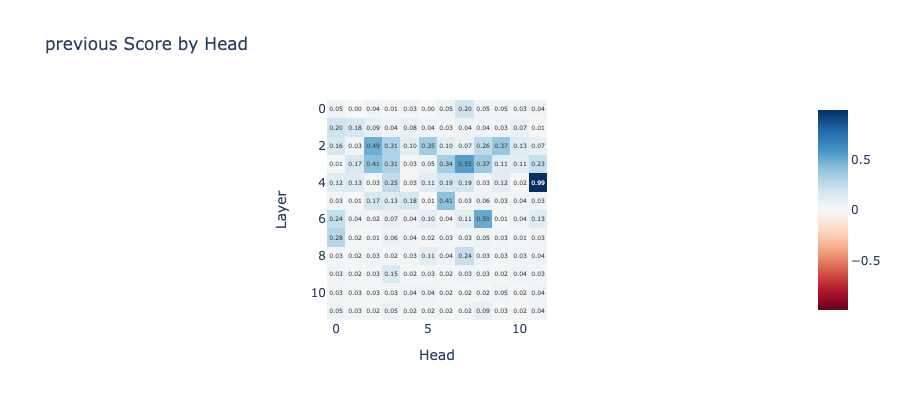
Now, let’s examine the induction scores. We’ll notice that some heads, such as the one on layer 5 and head 5, have a high induction score of 0.91.
We can also display the attention pattern of this head. You will notice a clear diagonal line up to an offset of seq_len.
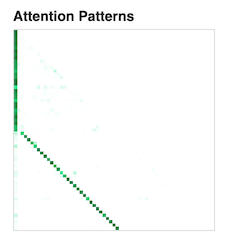
Similarly, we can identify the preceding token head. For instance, layer 4 head 11 demonstrates a strong pattern for the previous token.
How do MLP layers attribute?
Let’s consider this question: do MLP layers count? We know that GPT2-Small contains both attention and MLP layers. To investigate this, I propose using an ablation technique.
Ablation, as the name implies, systematically removes certain model components and observes how performance changes as a result.
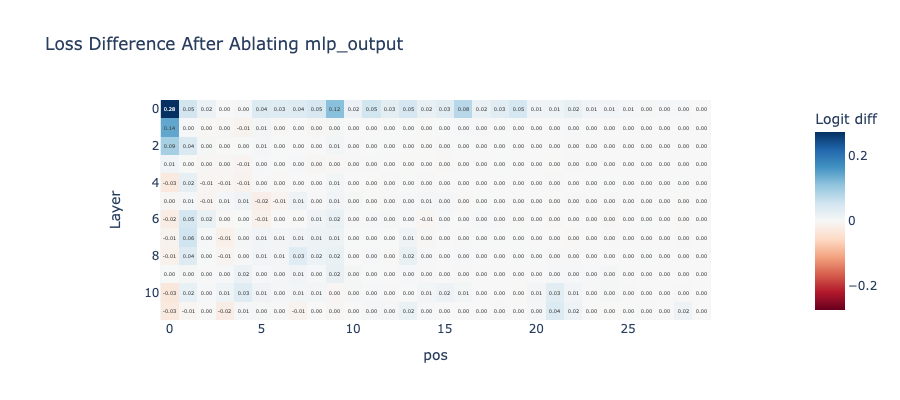
We will replace the output of the MLP layers in the second half of the sequence with those from the first half, and observe how this affects the final loss function. We will compute the difference between the loss after replacing the MLP layer outputs and the original loss of the second half sequence using the following code.
def patch_residual_component(
residual_component,
hook,
pos,
cache,
):
residual_component[0,pos, :] = cache[hook.name][pos-seq_len, :]
return residual_component
ablation_scores = t.zeros((gpt2_small.cfg.n_layers, seq_len), device=gpt2_small.cfg.device)
gpt2_small.reset_hooks()
logits = gpt2_small(rep_tokens, return_type="logits")
loss_no_ablation = cross_entropy_loss(logits[:, seq_len: max_len],rep_tokens[:, seq_len: max_len])
for layer in tqdm(range(gpt2_small.cfg.n_layers)):
for position in range(seq_len, max_len):
hook_fn = functools.partial(patch_residual_component, pos=position, cache=rep_cache)
ablated_logits = gpt2_small.run_with_hooks(rep_tokens, fwd_hooks=[
(utils.get_act_name("mlp_out", layer), hook_fn)
])
loss = cross_entropy_loss(ablated_logits[:, seq_len: max_len], rep_tokens[:, seq_len: max_len])
ablation_scores[layer, position-seq_len] = loss - loss_no_ablation
We arrive at a surprising result: aside from the first token, the ablation does not produce a significant logit difference. This suggests that the MLP layers may not have a significant contribution in the case of repeated tokens.
One induction circuit
Given that the MLP layers don’t significantly contribute to the final prediction, we can manually construct an induction circuit using the head of layer 5, head 5, and the head of layer 4, head 11. Recall that these are the induction head and the previous token head. We do it by the following code:
def K_comp_full_circuit(
model: HookedTransformer,
prev_token_layer_index: int,
ind_layer_index: int,
prev_token_head_index: int,
ind_head_index: int
) -> FactoredMatrix:
'''
Returns a (vocab, vocab)-size FactoredMatrix,
with the first dimension being the query side
and the second dimension being the key side (going via the previous token head)
'''
W_E = gpt2_small.W_E
W_Q = gpt2_small.W_Q[ind_layer_index, ind_head_index]
W_K = model.W_K[ind_layer_index, ind_head_index]
W_O = model.W_O[prev_token_layer_index, prev_token_head_index]
W_V = model.W_V[prev_token_layer_index, prev_token_head_index]
Q = W_E @ W_Q
K = W_E @ W_V @ W_O @ W_K
return FactoredMatrix(Q, K.T)
Computing the top 1 accuracy of this circuit yields a value of 0.2283. This is quite good for a circuit constructed by only two heads!
For detailed implementation, please check my notebook.
How to Interpret GPT2-Small was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
How to Interpret GPT2-Small