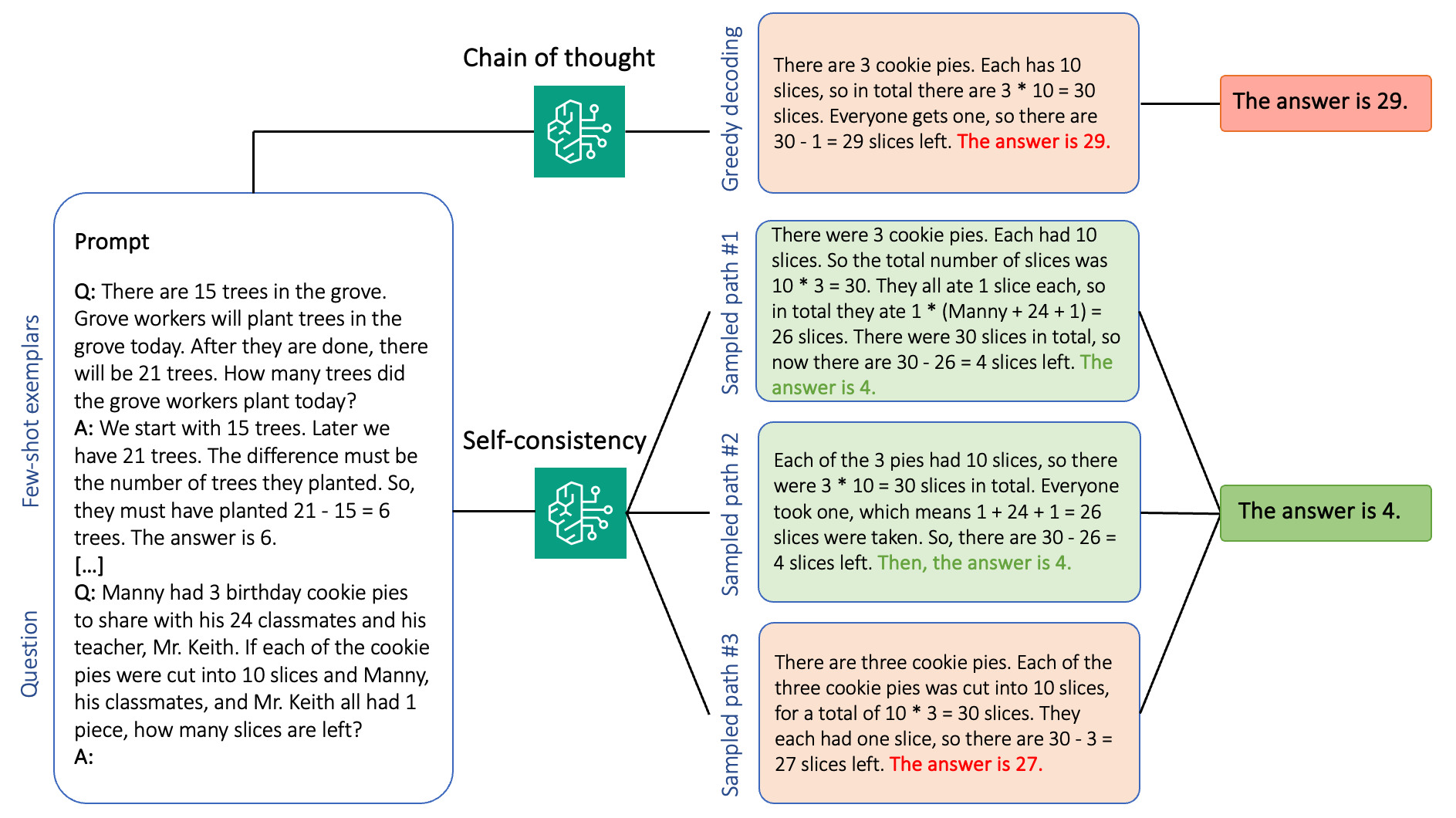

With the batch inference API, you can use Amazon Bedrock to run inference with foundation models in batches and get responses more efficiently. This post shows how to implement self-consistency prompting via batch inference on Amazon Bedrock to enhance model performance on arithmetic and multiple-choice reasoning tasks.
Originally appeared here:
Enhance performance of generative language models with self-consistency prompting on Amazon Bedrock