Unlocking efficient text classification with pre-trained models: a case study using OpenAI’s GPT-3.5-turbo

Traditionally, any natural language processing text classification project would start with gathering instances, defining their respective labels, and training a classification model, such as a logistic regression model, to classify the instances. Currently, the models available in OpenAI can be directly used for classification tasks that would typically require collecting a substantial amount of labeled data to train the model. These pre-trained models can be used for multiple text-processing tasks, including classification, summarization, spell-checking, and keyword identification.
We don’t require any labeled data or the need to train a model. Simple, right?
ChatGPT provides a graphical interface for the models implemented by OpenAI. However, what if we want to run those models directly in Python? Well, the available alternative is the OpenAI API, which allows us to access their models from a programming environment. In this article, we will describe with a brief example how we can access the API to detect whether an SMS is spam or not. To accomplish this, we will utilize one of the Open AI models, specifically the GPT-3.5-turbo model.
Creating an Open AI Account
The initial step to access the OpenAI API involves creating an account on OpenAI to obtain the API key required for accessing the models. Upon creating the account, we’ll have $5 of credit at our disposal, which, as we will later observe, will allow us to conduct numerous tests.
In this example, we’ll utilize the free version of OpenAI, which comes with limitations on requests per minute and per day. Adhering to these limits is crucial to avoid Rate Limit Errors. The values for these two parameters are set at 3 requests per minute and 200 per day. While this naturally imposes constraints, particularly for large-scale projects, it suffices for the purposes of this article’s example.
Accessing OpenAI with Python
Once we have created the account, we can access the OpenAI models available for the free version from Python using the OpenAI library. First, we create a function called chat_with_gpt to access the GPT-3.5-turbo model. The input to this function will be the prompt, which we will design later on.
Designing the Prompt
The next step is to create the prompt that we will provide to the GPT-3.5-turbo model. In this particular case, we are interested in two things. Firstly, a value between 0 and 1 indicating the probability of the SMS being spam or not, and secondly, an explanation of the model’s reasoning behind that decision. Additionally, we desire the result in JSON format so that we can later convert it into a dataframe. Below is the template we will use for these predictions.
Reading the SMS Spam Collection Dataset
Now, we need some messages to test how well the OpenAI model predicts whether a message is spam or not. For this purpose, we will use the SMS Spam Collection dataset available on the UCI Machine Learning Repository.
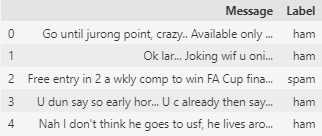
We read the data and convert it into a DataFrame. As observed, the dataset consists of two columns: one containing the messages and the second containing the corresponding labels. ham indicates that the message is not spam, while spam indicates that it is.
Utilizing the GPT-3.5-turbo Model for Spam Detection in Messages
Now, we will use the model to detect whether the messages are spam or not and evaluate how well the pre-trained OpenAI model can predict this problem. As mentioned at the beginning of the article, there are significant limitations regarding the number of requests per minute and per day that we can make with the free version. The dataset contains 5,574 instances, but to test the model, we will only use the first 50 instances. If you have a paid version of OpenAI, you can increase the number of messages tested as the time limitations are much lower.
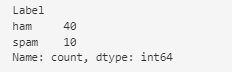
Before making predictions with the model, we have verified that our dataset of 50 instances contains both messages that are spam and messages that are not. In total, there are 40 non-spam messages and 10 spam messages.
Finally, we proceed to make the prediction. As shown below, we have kept track of the available credits and tokens at all times. Additionally, we have implemented a sleep function in the code for 60 seconds to ensure compliance with the restrictions regarding the number of requests.
The message provided by the model with the prediction has been stored in a variable called prediction. This message is a JSON file with the following structure: { “spam”: “0.1”, “reasoning”: “The message seems to be a typical promotional message about a buffet offer and does not contain any typical spam keywords or characteristics. The probability of this message being spam is low.” }.

The predictions yield a value between 0 and 1. A value of 0 indicates that the message is not spam, while a value of 1 indicates that it is. To assign the labels, we will use a threshold of 0.5, meaning that a score higher than 0.5 by the model will categorize the message as spam.

Now, all that’s left is to compare the actual labels with the predicted labels and assess how well the GPT-3.5-turbo model has performed the predictions.
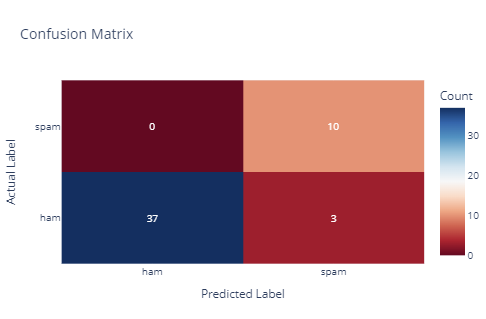
Above is the confusion matrix of the model.
- For messages that are not spam (ham), the model correctly predicted 37 of them as not spam (true negatives), but misclassified 3 of them as spam (false positives).
- For messages that are spam, the model correctly predicted 10 of them as spam (true positives), with no observed false negatives in this case.
The model demonstrates good sensitivity in detecting spam messages, with a few false positives indicating potential areas for improvement in its precision. As shown, the model achieved a 94% accuracy rate, correctly classifying 47 out of 50 instances.
Since we’ve requested the model to provide us with information regarding its reasoning for classifying a message as spam or not, we can examine why it misclassified 3 messages that do not belong to the spam category. Below are the explanations provided by the model:
- The message contains unusual language and grammar mistakes commonly associated with spam messages. It also mentions sensitive topics like AIDS, which is a common tactic used in spam messages to evoke emotions and prompt a response. Therefore, there is a high probability of this message being spam.
- The message contains suggestive and inappropriate content, which is a common characteristic of spam messages. Additionally, the use of improper grammar and language may indicate that this message is spam. Therefore, the probability of this message being spam is high.
- The message contains suggestive content related to personal attributes, which is a common characteristic of spam messages. Additionally, the use of explicit language increases the likelihood of this message being considered spam.
Messages with inappropriate content or numerous spelling errors tend to be classified as spam.
Project Summary
Traditionally, projects requiring text classification began with labeled databases and a model that needed training. The emergence of pre-trained Language Models (LLMs) now offers the possibility of classifying a multitude of texts without the need to train a model beforehand, as these models have already been trained for many use cases. In this article, we have explained how to utilize the OpenAI API to access the GPT-3.5-turbo model and determine whether a set of messages is spam or not. The model was able to classify 94% of the instances correctly, which indicates a high level of accuracy. In the future, it could be worthwhile to evaluate other OpenAI models and explore different prompts that may yield better performance. By the way, the execution of the project only costed $0.007.
Utilizing the OpenAI API for Detection of SMS Spam Messages was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Utilizing the OpenAI API for Detection of SMS Spam Messages
Go Here to Read this Fast! Utilizing the OpenAI API for Detection of SMS Spam Messages