

The playbook for selecting right optimization strategy guided by clear business objectives to better meet the needs of customers.
Generating human-like text and speech was once only possible in science fiction. But the rapid evolution of Large Language Models (LLMs) like GPT-3 and PaLM has brought this vision closer to reality, unlocking a range of promising business applications from chatbots to content creation.
Yet, the general-purpose foundation models often fail to meet the needs of industry use cases. Businesses have different requirements for their generative AI applications — from performance, cost, latency to explainability. Moreover, the nature and quantity of the data available for model training can differ significantly. It is therefore important for product teams to outline key business criteria for their generative AI application and select the right toolkit of optimization techniques to meet these needs.
In this post, we outline a framework for identifying and prioritizing strategic focus areas for your generative AI application. We will also explore popular optimization methods and discuss their unique strengths, ideal applications, and trade-offs in meeting the application requirements. With the right optimization strategy guided by clear business objectives, companies can develop custom AI solutions that balance the priorities critical to their success. Let’s dive in!
Framework to Assess Business Needs & Constraints
To tailor the strategy for optimizing LLMs effectively, product teams should start by building a deep understanding of the business objectives and the constraints within which they’re operating. Assess and prioritize the key dimensions listed below for your business use case:
1. Performance Goal: Define the measure and level of performance your AI needs to achieve. This could be combination of factual accuracy, alignment with human values, or other task-specific metrics.
Questions to Consider: What are the best dimensions for measuring performance? What is the minimum acceptable performance bar? How does performance align with user expectations in your industry?
2. Latency Targets: Determine the maximum response time that your application can afford without negatively impacting user experience. This could be especially important when LLMs are deployed in time-sensitive or resource-constrained scenarios (e.g., voice assistant, edge devices).
Questions to Consider: How does latency impact user satisfaction and retention? What are industry standards for response time?
3. Cost Efficiency: Evaluate the cost of operating AI with the expected ROI. Higher initial costs may be justified when they lead to substantial savings, revenue growth, or strategic benefits that outweigh investment.
Questions to Consider: How does the cost of operating LLMs impact your budget? How does the ROI compare with the cost of AI deployment?
4. Explainability & Trust: Determine if there is a need to ensure that the AI decisions are easily understood by users, which is critical for building trust, especially in fields with stringent regulatory demands.
Questions to Consider: Is your industry regulated, requiring transparency in AI’s decisions? How does explainability affect user trust and adoption?
5. External Knowledge: Assess if your AI needs access to external data sources to remain relevant and provide accurate responses.
Questions to Consider: Does your AI need real-time data to make decisions?
6. Data Availability: The nature and quantity of data available for training your AI could widely impact optimization strategy.
Questions to Consider: Do you have access to a large dataset for training, or will you need to use synthetic or augmented data? How often will you need to update the training data to keep the AI relevant?
Presented below is a table outlining three distinct use cases for generative AI applications, with a corresponding evaluation of priorities for each dimension within the framework:
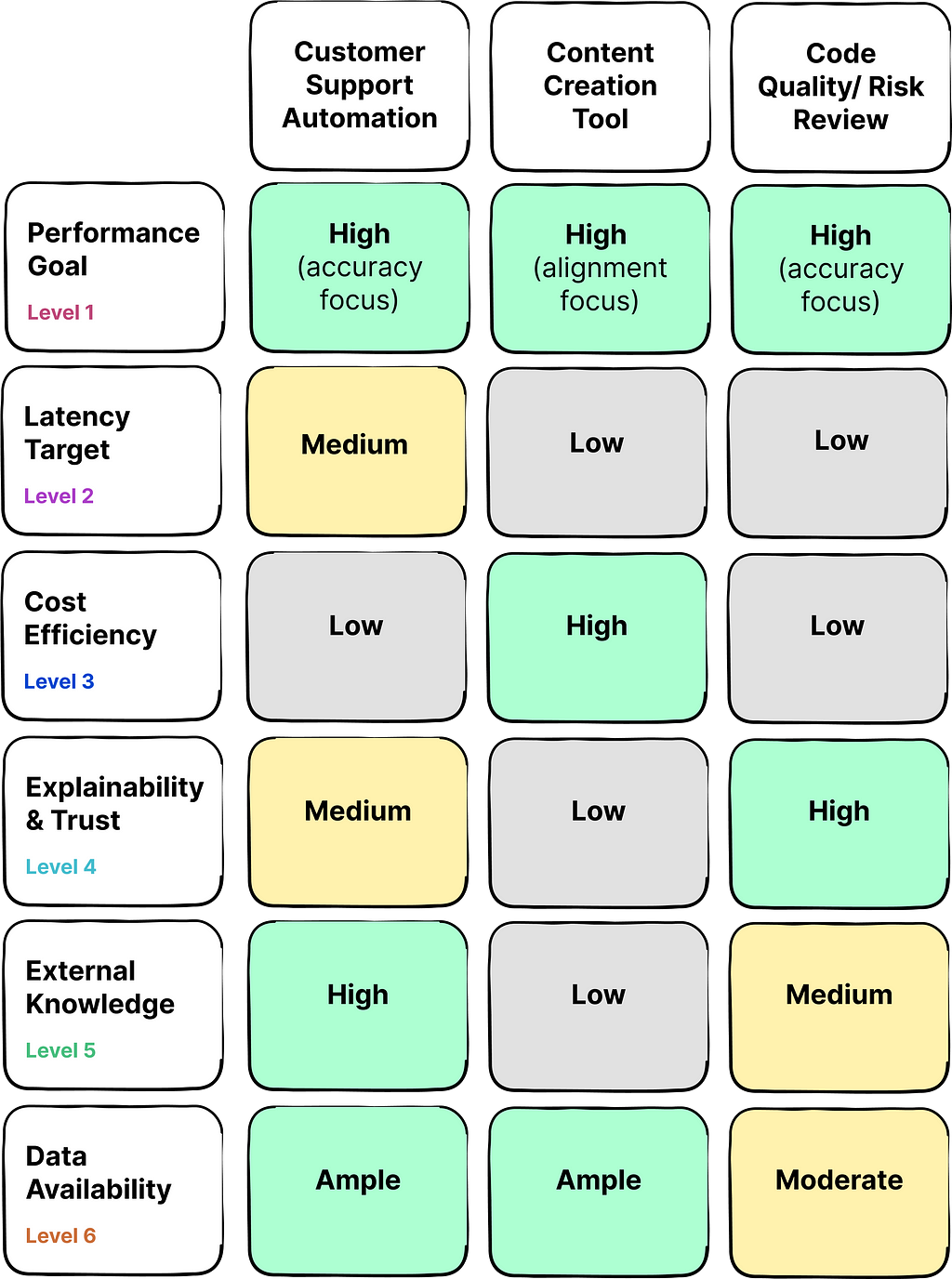
As you can see, the priorities and constrains can vary widely across different use cases.
For instance, consider a company aiming to develop a customer support chatbot to ease the workload on human staff. In this scenario, accuracy performance and external data integration are of high priority to deliver responses that are not only factually correct but also up-to-date. While latency holds some significance, users may be willing to tolerate brief delays. Typically, such a company will have access to an extensive archive of past customer support interactions that can be used for training models.
In contrast, the critical application of AI for assessing software code quality and risk demands a increased focus on factual accuracy and explainability of the AI’s insights, often due to the potential consequences of errors. Cost and latency are secondary considerations in this context. This use case could benefit from external data integration in some cases, and it usually faces constraints regarding the availability of rich training datasets.
A solid understanding of strategic priorities and constraints associated with the use case can help teams develop a tailored strategy for optimizing LLMs to meet the unique needs of the users.
Diving Deeper Into LLM Optimization Techniques
This section delves into the various optimization techniques, highlighting their objectives, ideal use-cases, and inherent trade-offs, particularly in the light of balancing the business goals discussed above.
Techniques Table Breakdown:

1. Prompt Engineering:
Execution Complexity: Low
When to Use: For reshaping response and quick improvement without altering the model. Start with this technique to maximize a pre-trained model’s effectiveness before trying more complex optimization methods.
What it entails: Prompt engineering involves crafting the input query to a model in a way that elicits the desired output. It requires understanding how the model responds to different types of instructions but doesn’t require retraining the model or altering its architecture. This method merely optimizes the way the existing model accesses and applies its pre-trained knowledge, and does not enhance the model’s intrinsic capabilities.
“It’s like adjusting the way you ask a question to a knowledgeable friend to get the best possible answer.”
Examples:
- Asking a language model to “Write a poem in the style of Shakespeare” versus “Write a poem” to elicit a response in a specific literary style.
- Providing a detailed scenario in prompt for a conversational AI to ensure the model understands its role as customer service agent.
Trade-offs:
- Trial & Error: Designing the most effective prompt requires iterations, since relationship between prompt and AI output is not always intuitive.
- Output Quality: The quality of the output is highly dependent on the design of the prompt, and there are limitations to the level of improvements that you can achieve through this method.
2. Fine-Tuning:
Execution Complexity: Medium
When to Use: Fine-tuning should be considered when you need the model to adapt to a specific domain or task that may not be well-covered by the base pre-trained model. It is a step towards increasing domain specific accuracy and creating a more specialized model that can handle domain specific data and terminology.
What it entails: Fine-tuning is the process of continuing the training of a pre-trained model on a new dataset that is representative of the target task or domain. This new dataset consists of input-output pairs that provide examples of the desired behavior. During fine-tuning, the model’s weights are updated to minimize the loss on this new dataset, effectively adapting the model to the new domain.
“Think of it as giving your friend a crash course on a topic you want them to become an expert in; showing them multiple examples of questions that may come in a test and the sample answers that they are expected to respond with.”
Examples:
- A general-purpose language model can be fine-tuned on legal documents to improve its performance for reviewing such documents.
- An image recognition model can be fine-tuned with medical imaging datasets to better identify specific diseases in X-rays or MRIs.
Trade-offs:
- Data Requirement: Fine-tuning requires a labeled dataset that is relevant to the task, which can be resource-intensive to create.
- Overfitting Risk: There is a potential risk of the model becoming too specialized to the fine-tuning data, which can decrease its ability to generalize to other contexts or datasets.
3. Retrieval-Augmented Generation (RAG):
Execution Complexity: High
When to use: RAG should be considered when there is a need for the AI model to access and incorporate external information to generate responses. This is especially relevant when the model is expected to provide up-to-date or highly specific information that is not contained within its pre-trained knowledge base.
What it entails:
RAG combines the generative capabilities of an LLM with a retrieval system. The retrieval system queries a database, knowledge base, or the internet to find information relevant to the input prompt. The retrieved information is then provided to the language model, which incorporates this context to generate a richer and more accurate response. By citing the sources used by the RAG system to generate responses, generative AI applications can offer enhanced explainability to the users.
In the coming years, this optimization technique is expected to gain widespread popularity as an increasing number of products seek to leverage their latest business data to tailor experiences for customers.
“It’s akin to your friend being able to look up information online to answer questions that are outside their immediate expertise. It’s an open book exam.”
Examples:
- In a RAG-based online chatbot, retriever can pull relevant information from a database or the internet to provide up-to-date answers.
- A homework assistant AI could use RAG to fetch the most recent scientific data to answer a student’s question about climate change.
Trade-offs:
- Complex Implementation: RAG systems require a well-integrated retrieval system, which can be challenging to set up and maintain.
- Quality of Information: The usefulness of the generated response is highly dependent on the relevance and accuracy of retrieved information. If the retrieval system’s sources are outdated or incorrect, the responses will reflect that.
- Slow Response Time: Retrieving information from external source to generate response can add latency.
4. Reinforcement Learning from Human Feedback (RLHF):
Execution Complexity: Very High
When to use: RLHF should be used when the model’s outputs need to align closely with complex human judgments and preferences.
What it entails: RLHF is a sophisticated reinforcement learning technique that refines a model’s behavior by incorporating human evaluations directly into the training process. This process typically involves collecting data from human operators who rank the outputs from AI on various quality metrics such as relevance, helpfulness, tone, etc. These data signals are then used to train a reward model, which guides the reinforcement learning process to produce outputs that are more closely aligned with human preferences.
“It’s similar to your friend learning from past conversations about what makes a discussion enjoyable, and using that knowledge to improve future interactions.”
Examples:
- A social media platform could use RLHF to train a moderation bot that not only identifies inappropriate content but also responds to users in a way that is constructive and sensitive to context.
- A virtual assistant could be fine-tuned using RLHF to provide more personalized and context-aware responses to user requests.
Trade-offs:
- High Complexity: RLHF involves complex, resource-intensive processes, including human feedback gathering, reward modeling, and reinforcement learning.
- Quality Risk: There’s a risk of bias in the feedback data, which can lead to affect model quality. Ensuring consistent quality of human feedback and aligning the reward model with desired outcomes can be difficult.
5. Knowledge Distillation
Execution Complexity: Moderate to High
When to use: Knowledge distillation is used when you need to deploy sophisticated models on devices with limited computational power or in applications where response time is critical.
What it entails: It’s a compression technique where a smaller, more efficient model (known as the student) is trained to replicate the performance of a larger, more complex model (the teacher). The training goes beyond just learning the correct answers (hard targets), and involves the student trying to produce similar probabilities as the teacher’s predictions (soft targets). This approach enables the student model to capture the nuanced patterns and insights that teacher model has learned.
“This is similar to distilling the wisdom of a seasoned expert into a concise guidebook that a novice can use to make expert-level decisions without going through years of experience.”
Examples:
- A large-scale language model could be distilled into a smaller model that runs efficiently on smartphones for real-time language translation.
- An image recognition system used in autonomous vehicles can be distilled into a light model that can run on vehicle’s onboard computer.
Trade-offs:
- Performance vs. Size: The distilled model may not always match the performance of the teacher model, leading to a potential decrease in accuracy or quality.
- Training Complexity: The distillation process is time-consuming and involves careful experimentation to ensure the student model learns effectively. It requires a deep understanding of models’ architectures and the ability to translate knowledge from one to another.
Now let’s take a look at a real-world example in action.
Example: Customer Support Chatbot
Let’s revisit the use case of building customer support chatbot to reduce workload on human support staff. The requirements/ constraints included:
- Performance: High Priority (Emphasis on Factual Accuracy)
- External Knowledge: High Priority
- Latency Targets: Medium Priority
- Cost Efficiency: Low Priority
- Explainability & Trust: Medium Priority
- Data Availability: Ample (Past Conversations Data)
With the clear understanding of business context and priorities, product builders can devise the most effective optimization strategy.
LLM Optimization Decision Steps:
- Prompt Engineering should serve as the first step to improve chatbot’s initial understanding and response capabilities. However, this alone is unlikely to suffice for specialized domain accuracy.
- Fine-Tuning the model with historic customer conversation data is critical for boosting chatbot’s accuracy performance, and making the model adept at handling, nuanced industry-specific inquiries.
- Incorporating Retrieval-Augmented Generation (RAG) is vital for providing users up-to-date product information and relevant web links.
- While a certain degree of latency is tolerable, monitoring and potentially optimizing response times will still be advisable. Optimization strategies here could include caching common queries to speed up responses and using prompt engineering strategically to reduce unnecessary external data retrievals.
As you can see, a combination of strategies is often necessary to meet the specific demands of a use case. Flexibility in optimization strategies can be crucial, as requirements can change over time, and systems need to balance multiple requirements simultaneously.
Conclusion
Optimizing LLMs for a business use case is both an art and a science, which requires a deep understanding of the underlying technology and the objectives at hand. As AI continues to evolve, the choice of optimization techniques will become increasingly strategic, influencing not only the performance of individual applications but also the overall trajectory of AI’s role in society.
Whether you’re optimizing for speed, accuracy, cost, or transparency, the techniques discussed above offer a toolkit for enhancing LLMs to meet the demands of tomorrow’s generative AI powered business applications. By thoughtfully applying these methods, we can create AI that’s not only effective but also responsible and attuned to the nuanced needs of users.
Thanks for reading! If these insights resonate with you or spark new thoughts, let’s continue the conversation. Share your perspectives in the comments below or connect with me on LinkedIn.
Framework for Optimizing Generative AI to Meet Business Needs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Framework for Optimizing Generative AI to Meet Business Needs
Go Here to Read this Fast! Framework for Optimizing Generative AI to Meet Business Needs