

Harnessing AI to Classify Macroeconomic Sentiment and Addressed Agents
This post was co-authored with Vincent P. Marohl and is based on the paper Pfeifer, M. and Marohl, V.P. (2023) “CentralBankRoBERTa: A Fine-Tuned Large Language Model for Central Bank Communications”, Journal of Finance and Data Science https://doi.org/10.1016/j.jfds.2023.100114.
How do communications about economic policies affect economic outcomes? What is the central bank saying about small business, the housing sector or government finances? In this article we explore CentralBankRoBERTa, a state-of-the-art economic agent classifier that distinguishes five basic macroeconomic agents and binary sentiment classifier that identifies the emotional content of sentences in macroeconomic communications. We train our model on over 12,000 manually labeled sentences from communications of the U.S. Federal Reserve System, the European Central Bank and global members of the Bank of International Settlements.
LLMs for Economics
Advances in LLMs have made it much easier to fine-tune for specific applications. All that is needed to obtain state-of-the-art classification performance is extensive training data for the specific application domain. Thus far, no LLM could generate sentiment labels for macroeconomic topics. After all, what constitutes a ‘positive’ macroeconomic sentence?
We have developed CentralBankRoBERTa. The model is based on the RoBERTa architecture and classifies sentences for economic sentiment. It also classifies who is most concerned. The model has initially been conceptualized for central bank communications, a subfield of economics that aims to quantify the economic impact of words.
The advantage of central bank communications is that one has to think about what constitutes a positive economic signal to whom. For example, the sentence “wages are rising beyond expectations” may be labeled as positive for households, who receive wages, and negative for firms, who pay wages.
CentralBankRoBERTa classifies sentences based on what is good for whom. We distinguish five different macroeconomic agents: households, firms, the financial sector, government and the central bank itself. The agent-signal dynamic allows the model to classify whether a sentence emits a positive or negative signal without further numeric context.
Paying attention to context and audiences is key in text analysis, especially for complex subjects like economic policy. This is because the way a message is received can differ greatly based on the audience and situation. CentralBankRoBERTa highlights the importance of this by accurately identifying economic sentiments according to the specific audience and context.
Applications
The wide ranging responsibilities of the central bank make the model generally applicable. After all, it does not matter whether a central banker or a CEO expresses good or bad news for firms or other economic agents. This is also true for finance ministers, hedge fund managers, journalists and other economic players whose views on the economy contribute to shaping it.
Next, we show how CentralBankRoBERTa can help analyze the effect of narratives on the economy by studying business and monetary policy messages. Any relevant text data can be used for this. Here, we use a dataset of U.S. public companies’ earnings call transcripts and SEC filings. We then clean this data with regex and label each sentence using CentralBankRoBERTa to obtain a sentiment score as described in more detail in the next section.
The final dataset contains about 2000 U.S. based public firms, with each about 20 years of quarterly text data. To see how they track, we also label a text dataset of speeches from the Fed. We select only those sentences by the Fed that speak about firms, so that we do not pick unrelated information.
We find that state-level average firm sentiment closely tracks the business cycle. Regional Fed communications, as shown below in the case of Texas, also closely track the business cycle.
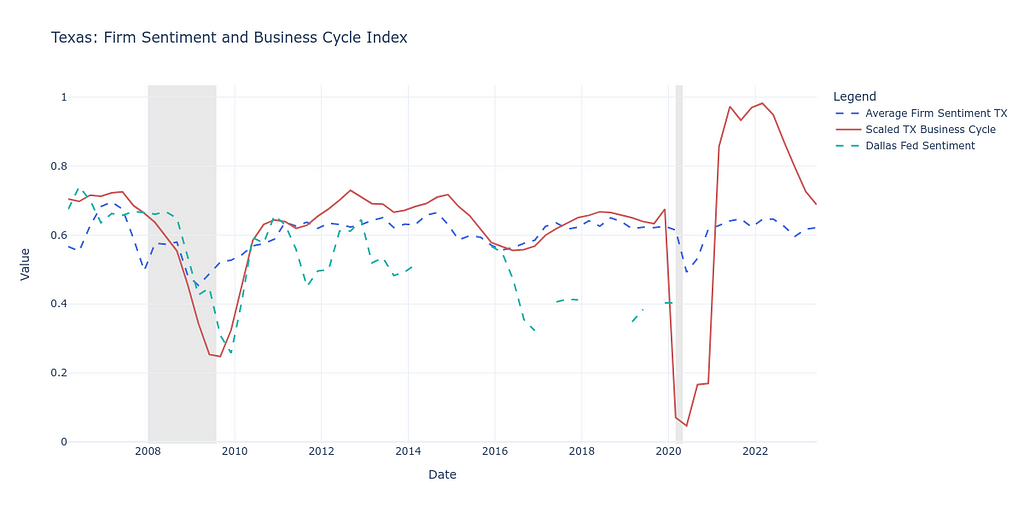
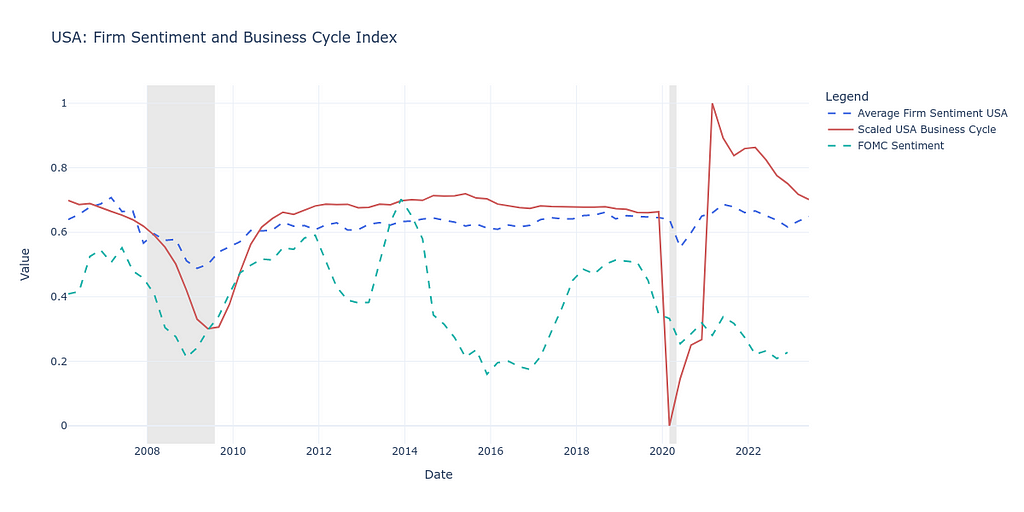
This descriptive analysis of firm sentiments using CentralBankRoBERTa provides a glimpse into the relationship between economic narratives and the market dynamics of businesses. Especially downturns, such as during the Great Recession of 2008 and the COVID-19 pandemic, are accurately captured by business and FOMC sentiment.
Our small example underscores the potential of text data to enrich economic models. Sentiment trends expressed in text data can influence economic dynamics, however they are notoriously difficult to capture. Tools like CentralBankRoBERTa may assist researchers and policymakers in filling the
gap between the study of narratives and their effects on economic events
as Robert Shiller, the recipient of the 2013 Nobel Memorial Prize in Economics wrote in his book Narrative Economics (2019). Shiller emphasizes how stories, or narratives, spread like viruses through society, directly influencing spending, saving, and investing decisions. Understanding the power of narratives offers a new dimension to economic analysis, suggesting that beyond traditional economic indicators, attention to the prevailing stories and their emotional resonance can offer predictive insights into market movements and economic shifts. Integrating narrative analysis into economic models, therefore, could enhance our ability to anticipate and respond to future economic challenges, making it a vital tool for economists, policymakers, and investors alike.
How to use
CentralBankRoBERTa is easy-to-use. To interface with the Hugging Face pipeline for both classification models, first, import the pipeline from the transformers package. Then, load the model using the model’s name on Hugging Face. Create an input sentence and pass it to the classifier. If you want to classify an entire data set, we have a sample script with additional code on github. CentralBankRoBERTa works best on a sentence-level, so we recommend users to parse large texts into individual sentences. For example, in the minutes of the last Federal Open Market Committee (FOMC) meeting, we can find the following view,
The staff provided an update on its assessment of the stability of the U.S. financial system and, on balance, characterized the system’s financial vulnerabilities as notable.
Given this sentence to our agent classifier, the model is 96.6% confident the sentence pertains to the “Financial Sector.” Similarly, the sentiment classifier output shows a 80.9% probability of the sentence being “negative.”
Employing sentiment-classifier:
from transformers import pipeline
# Load the SentimentClassifier model
agent_classifier = pipeline("text-classification", model="Moritz-Pfeifer/CentralBankRoBERTa-sentiment-classifier")
# Choose your input
input_sentence = "The early effects of our policy tightening are also becoming visible, especially in sectors like manufacturing and construction that are more sensitive to interest rate changes."
# Perform sentiment analysis
sentiment_result = agent_classifier(input_sentence)
print("Sentiment:", sentiment_result[0]['label'])
Employing agent classifier:
from transformers import pipeline
# Load the AgentClassifier model
agent_classifier = pipeline("text-classification", model="Moritz-Pfeifer/CentralBankRoBERTa-agent-classifier")
# Choose your input
input_sentence = "We used our liquidity tools to make funding available to banks that might need it."
# Perform agent classification
agent_result = agent_classifier(input_sentence)
print("Agent Classification:", agent_result[0]['label'])
Future Directions
CentralBankRoBERTa is an LLM that allows to label text for macroeconomic sentiment on unprecedented granularity. It also represents the first economic agent classifier. The model’s broad training data allows for general macroeconomic applications, and can be used for economic, financial and policy research. We hope you feel inspired by the possibilities opened by this model, and want to leave you with some possible future directions of research enabled by this LLM:
● FOMC Press Conference: Can we anticipate financial market movements caused by Fed communications using CentralBankRoBERTa? How about a firms’ earning calls?
● Newspaper Text: What is the press thinking about the economy? Is the news biased towards one economic group?
● Online Forums: Using CentralBankRoBERTa, can we forecast economic trends from online discussion forums?
● Audience classifier: What politicians are most friendly towards which economic group?
Further Resources
- The publication of our model in the Journal of Finance and Data Science:
Pfeifer, M. and Marohl, V.P. (2023) “CentralBankRoBERTa: A Fine-Tuned Large Language Model for Central Bank Communications”, Journal of Finance and Data Science https://doi.org/10.1016/j.jfds.2023.100114
- A seminar in which we explain the details of our model:
- The model pipelines on Hugging Face:
- Moritz-Pfeifer/CentralBankRoBERTa-agent-classifier · Hugging Face
- Moritz-Pfeifer/CentralBankRoBERTa-sentiment-classifier · Hugging Face
CentralBankRoBERTa: an LLM for Macroeconomics was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
CentralBankRoBERTa: an LLM for Macroeconomics
Go Here to Read this Fast! CentralBankRoBERTa: an LLM for Macroeconomics