How do we communicate effectively with LLMs?
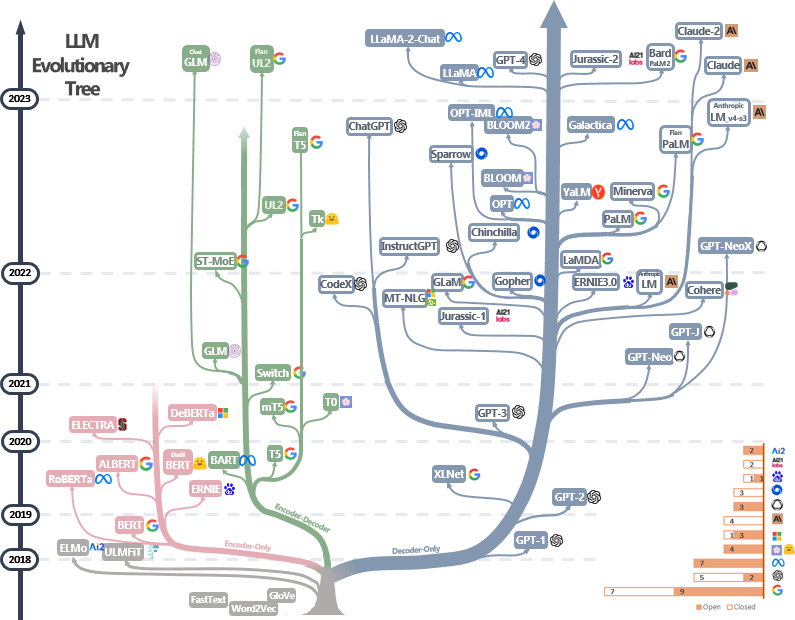
Unless you’ve been completely disconnected from the buzz on social media and in the news, it’s unlikely that you’d have missed the excitement around Large Language Models (LLMs).
{kind=link}
LLMs have become ubiquitous, with new models being released almost daily. They’ve also been made more accessible to the general public, thanks to a thriving open-source community that has played a crucial role in reducing memory requirements and developing efficient fine-tuning methods for LLMs, even with limited compute resources.
One of the most exciting use cases for LLMs is their remarkable ability to excel at tasks they were not explicitly trained for, using just a task description and, optionally, a few examples. You can now get a capable LLM to generate a story in the style of your favorite author, summarize long emails into concise ones, and develop innovative marketing campaigns by describing your task to the model without needing to fine-tune it. But how do you best communicate your requirements to the LLM? This is where prompting comes in.
Table of Contents:
- What is Prompting?
- Why is Prompting Important?
- Exploring different prompting strategies
- How can we implement these techniques?
4.1. Prompting Llama 2 7B-Chat with a Zero-Shot Prompt
4.2. Prompting Llama 2 7B-Chat with a Few-Shot Prompt
4.3. What happens if we don’t adhere to the chat template?
4.4. Prompting Llama 2 7B-Chat with CoT Prompting
4.5. Failure Modes in CoT for Llama 2
4.6. Prompting GPT-3.5 with a Zero-Shot Prompt
4.7. Prompting GPT-3.5 with a Few-Shot Prompt
4.8. Prompting GPT-3.5 with CoT Prompting - Conclusion and Takeaways
- Reproducibility
- References
What is Prompting?
Prompting, or Prompt Engineering, is a technique used to design inputs or prompts that guide artificial intelligence models — particularly those in natural language processing and image generation — to produce specific, desired outputs. Prompting involves structuring your requirements into an input format that effectively communicates the desired outcomes to the model, thereby obtaining the intended output.
Large Language Models (LLMs) demonstrate an ability for in-context learning [2] [3]. This means these models can understand and execute various tasks based solely on task descriptions and examples provided to the model through a prompt without requiring specialized fine-tuning for each new task. Prompting is significant in this context as it is the primary interface between the user and the model to harness this ability. A well-defined prompt helps define the nature and expectations of the task to the LLM, along with how to provide the output in a utilizable manner to the user.
You might be inclined to think that prompting an LLM shouldn’t be that hard; after all, it’s just about describing your requirements to the model in natural language, right? In practice, it isn’t as straightforward. You will discover that different LLMs have varying strengths. Some might better adhere to your desired output format, while others may necessitate more detailed instructions. The task you wish the LLM to perform could be complex, requiring elaborate and precise instructions. Therefore, devising a suitable prompt often entails a lot of experimentation and benchmarking.
Why is Prompting important?
In practice, LLMs are sensitive to how the input is structured and provided to them. We can analyze this along various axes to better understand the situation:
- Adhering to Prompt Formats: LLMs often utilize varying prompt formats to accept user input. This is typically done when models are instruction-tuned or optimized for chat use cases [4] [5]. At a high level, most prompt formats include the instruction and the input. The instruction describes the task to be performed by the model, while the input contains the text on which the task needs to be executed. Let’s take the Alpaca Instruction format, for example (taken from https://github.com/tatsu-lab/stanford_alpaca):
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Given the models are instruction-tuned using a template like this, the model is expected to perform optimally when a user prompts it using the same format.
2. Describing output formats for parseability: Having provided a prompt to the model, you’d want to extract what you need from the model’s output. Ideally, these outputs should be in a format you can effortlessly parse through programming methods. Depending on the task, such as text classification, this might involve leveraging regular expressions (regex) to sift through the LLM’s output. In contrast, you might prefer a format like JSON for your output for tasks requiring more fine-grained data like Named Entity Recognition (NER).
However, the more you work with LLMs, the faster you learn that obtaining parseable outputs can be challenging. LLMs often struggle to deliver outputs precisely in the format requested by the user. While strategies like few-shot prompting can significantly mitigate this issue, achieving consistent, programmatically parsable outputs from LLMs demands careful experimentation and adaptation.
3. Prompting for optimal performance: LLMs are quite sensitive to how the task is described. A prompt that is not well-crafted or leaves too much room for interpretation can lead to subpar performance. Imagine explaining a task to someone — the clearer and more detailed your explanation, the better the understanding on the other end. However, there is no magic formula for arriving at the ideal prompt. This requires careful experimentation and evaluation of different prompts to select the best-performing prompt.
Exploring different prompting strategies
Hopefully, you’re convinced you need to take prompting seriously by this point. If prompting is a toolkit, what are the tools we can leverage?
Zero-shot Prompting: Zero-shot prompting [2] [3] involves instructing an LLM to perform a task described solely in the prompt without providing examples. The term “zero-shot” signifies that the model must rely entirely on the task description in the prompt, as it receives no specific demonstrations related to the task.

In many cases, zero-shot prompting can suffice for instructing an LLM to perform your desired task. However, zero-shot prompting may have limitations if your task is too ambiguous, open-ended, or vague. Suppose you want an LLM to rank an answer on a scale from 1 to 5. Although the model could perform this task with a zero-shot prompt, two possible problems can arise here:
- The LLM might not have an objective understanding of what each number on the scoring scale signifies. It may struggle to decide when to assign a score of 3 or 4 to an answer if the task description lacks nuance.
- The LLM could have its own concept of scoring from 1 to 5, which might contradict your personal scoring rubrics. You might prioritize the factuality of an answer when scoring it, but the model could evaluate the answer based on how well it is written.
To ground the model in your scoring expectations, you can provide a few examples of answers and how you might score them. Now, the model has more context and reference on how to score documents, thereby narrowing the ambiguity in the task. This brings us to few-shot prompting.
Few-shot Prompting: Few-shot prompting enriches the task description with a small number of example inputs and their corresponding outputs [3]. This technique enhances the model’s understanding by including several example pairs illustrating the task.
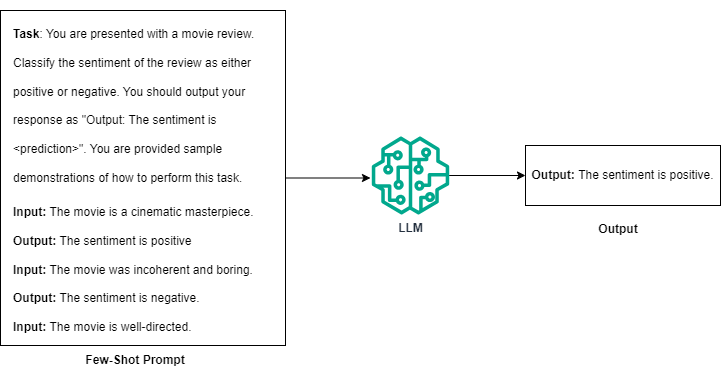
For instance, to guide an LLM in sentiment classification of movie reviews, you would present a few reviews along with their sentiment ratings. The primary benefit of few-shot over zero-shot prompting is the ability to demonstrate examples of how to perform the task instead of expecting the LLM to perform the task with just a description.
Chain of Thought: Chain of Thought (CoT) prompting [6] is a technique that enables LLMs to solve complex problems by breaking them down into simpler, intermediate steps. This approach encourages the model to “think aloud,” making its reasoning process transparent and allowing the LLM to solve reasoning problems more effectively. As mentioned by the authors of the work [6], CoT mimics how humans try to solve reasoning problems by decomposing the problem into simpler steps and solving them one at a time rather than jumping directly to the answer.
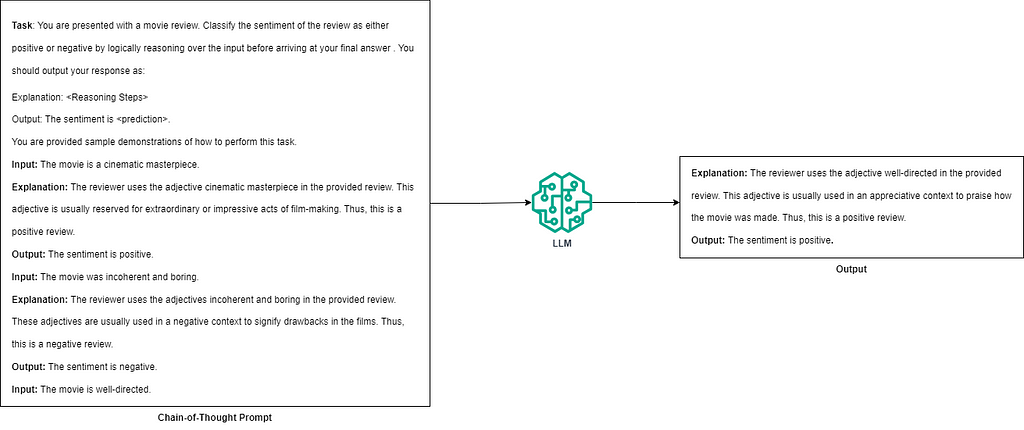
CoT prompting is typically implemented as a few-shot prompt, where the model receives a task description and examples of input-output pairs. These examples include reasoning steps that systematically lead to the correct answer, demonstrating how to process the information. Thus, to perform CoT prompting effectively, users need high-quality demonstration examples. However, this can be challenging for tasks requiring specialized domain expertise. For instance, using an LLM for medical diagnosis based on a patient’s history would necessitate the assistance of domain experts, such as doctors or physicians, to articulate the correct reasoning steps. Moreover, CoT is particularly effective in models with a sufficiently large parameter scale. According to the paper [6], CoT is most effective for the 137B parameter LaMBDA [7], the 175B parameter GPT-3 [3], and the 540B parameter PaLM [8] models. This limitation can restrict its applicability for smaller-scale models.
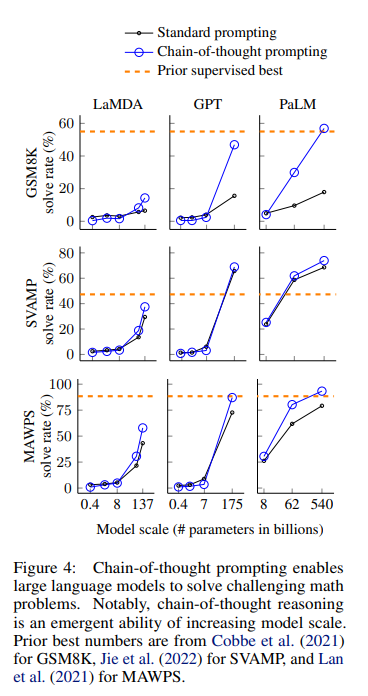
Another aspect of CoT prompting that sets it apart from standard prompting is that the model needs to generate significantly more tokens before arriving at the final answer. While not necessarily a drawback, this is a factor to consider if you are compute-bound at inference time.
If you want a deeper overview, I recommend OpenAI’s prompting resources, available at https://platform.openai.com/docs/guides/prompt-engineering/strategy-write-clear-instructions.
How can we implement these techniques?
All code and resources related to this article are made available at this Github repository, under the introduction_to_prompting folder. Feel free to pull the repository and run the notebooks directly to run these experiments. Please let me know if you have any feedback or observations or if you notice any mistakes!
We can explore these techniques on a sample dataset to make understanding easier. To this end, we will work with the MedQA dataset [9], which contains questions testing medical and clinical knowledge. We will specifically utilize the USMLE questions from this dataset. This task is ideal for analyzing various prompting techniques, as answering the questions requires knowledge and reasoning. We will test the capabilities of Llama-2 7B [10] and GPT-3.5 [11] on this dataset.
Let’s first download the dataset. The MedQA dataset can be downloaded from this link. After downloading the dataset, we can parse and begin processing the questions. The test set contains a total of 1,273 questions. We randomly sample 300 questions from the test set to evaluate the models and select 3 random examples from the training set as our few-shot demonstrations for the model.
import json
import random
random.seed(42)
def read_jsonl_file(file_path):
"""
Parses a JSONL (JSON Lines) file and returns a list of dictionaries.
Args:
file_path (str): The path to the JSONL file to be read.
Returns:
list of dict: A list where each element is a dictionary representing
a JSON object from the file.
"""
jsonl_lines = []
with open(file_path, 'r', encoding="utf-8") as file:
for line in file:
json_object = json.loads(line)
jsonl_lines.append(json_object)
return jsonl_lines
def write_jsonl_file(dict_list, file_path):
"""
Write a list of dictionaries to a JSON Lines file.
Args:
- dict_list (list): A list of dictionaries to write to the file.
- file_path (str): The path to the file where the data will be written.
"""
with open(file_path, 'w') as file:
for dictionary in dict_list:
# Convert the dictionary to a JSON string and write it to the file.
json_line = json.dumps(dictionary)
file.write(json_line + 'n')
# read the contents of the train and test set
train_set = read_jsonl_file("data_clean/questions/US/4_options/phrases_no_exclude_train.jsonl")
test_set = read_jsonl_file("data_clean/questions/US/4_options/phrases_no_exclude_test.jsonl")
# subsample test set samples and few-shot samples
test_set_subsampled = random.sample(test_set, 300)
few_shot_examples = random.sample(test_set, 3)
# dump the sampled questions and few-shot samples as jsonl files
write_jsonl_file(test_set_subsampled, "USMLE_test_samples_300.jsonl")
write_jsonl_file(few_shot_examples, "USMLE_few_shot_samples.jsonl")
Prompting Llama 2 7B-Chat with a Zero-Shot Prompt
The Llama series of models were released by Meta. They are a decoder-only family of LLMs spanning parameter counts from 7B to 70B. The Llama-2 series of models comes in two variants: the base version and the chat/instruction-tuned variant. For this exercise, we’ll work with the chat-version of the Llama 2-7B model.
Let’s see how well we can prompt the Llama model to answer these medical questions. We load the model into memory:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from tqdm import tqdm
questions = read_jsonl_file("USMLE_test_samples_300.jsonl")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.bfloat16).cuda()
model.eval()
If you’re working with Nvidia Ampere GPUs, you can load the model using torch.bfloat16. It offers speedups to inference and utilizes lesser GPU memory than normal FP16/FP32.
First, let’s now craft a basic prompt for our task:
PROMPT = """You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response"""
Our prompt is straightforward. It includes information about the nature of the task and provides instructions on the format for the output. We’ll see how effectively this prompt works in practice.
The Llama-2 chat models have a particular chat template to be followed for prompting them.
<s>[INST] <<SYS>>
You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response
<</SYS>>
A 21-year-old male presents to his primary care provider for fatigue. He reports that he graduated from college last month and returned 3 days ago from a 2 week vacation to Vietnam and Cambodia. For the past 2 days, he has developed a worsening headache, malaise, and pain in his hands and wrists. The patient has a past medical history of asthma managed with albuterol as needed. He is sexually active with both men and women, and he uses condoms “most of the time.” On physical exam, the patient’s temperature is 102.5°F (39.2°C), blood pressure is 112/66 mmHg, pulse is 105/min, respirations are 12/min, and oxygen saturation is 98% on room air. He has tenderness to palpation over his bilateral metacarpophalangeal joints and a maculopapular rash on his trunk and upper thighs. Tourniquet test is negative. Laboratory results are as follows:
Hemoglobin: 14 g/dL
Hematocrit: 44%
Leukocyte count: 3,200/mm^3
Platelet count: 112,000/mm^3
Serum:
Na+: 142 mEq/L
Cl-: 104 mEq/L
K+: 4.6 mEq/L
HCO3-: 24 mEq/L
BUN: 18 mg/dL
Glucose: 87 mg/dL
Creatinine: 0.9 mg/dL
AST: 106 U/L
ALT: 112 U/L
Bilirubin (total): 0.8 mg/dL
Bilirubin (conjugated): 0.3 mg/dL
Which of the following is the most likely diagnosis in this patient?
Options:
A. Chikungunya
B. Dengue fever
C. Epstein-Barr virus
D. Hepatitis A [/INST]
The task description should be provided between the <<SYS>> tokens, followed by the actual question the model needs to answer. The prompt is concluded with a [/INST] token to indicate the end of the input text.
The role can be one of “user”, “system”, or “assistant”. The “system” role provides the model with the task description, and the “user” role contains the input to which the model needs to respond. This is the same convention we will utilize later on when interacting with GPT-3.5. It is equivalent to creating a fictional multi-turn conversation history provided to Llama-2, where each turn corresponds to an example demonstration and an ideal output from the model.
Sounds complicated? Thankfully, the Huggingface Transformers library supports converting prompts to the chat template. We will utilize this functionality to make our lives easier. Let’s start with helper functionalities to process the dataset and create prompts.
def create_query(item):
"""
Creates the input for the model using the question and the multiple choice options.
Args:
item (dict): A dictionary containing the question and options.
Expected keys are "question" and "options", where "options" is another
dictionary with keys "A", "B", "C", and "D".
Returns:
str: A formatted query combining the question and options, ready for use.
"""
query = item["question"] + "nOptions:n" +
"A. " + item["options"]["A"] + "n" +
"B. " + item["options"]["B"] + "n" +
"C. " + item["options"]["C"] + "n" +
"D. " + item["options"]["D"]
return query
def build_zero_shot_prompt(system_prompt, question):
"""
Builds the zero-shot prompt.
Args:
system_prompt (str): Task Instruction
content (dict): The content for which to create a query, formatted as
required by `create_query`.
Returns:
list of dict: A list of messages, including a system message defining
the task and a user message with the input question.
"""
messages = [{"role": "system", "content": system_prompt},
{"role": "user", "content": create_query(question)}]
return messages
This function constructs the query to provide to the LLM. The MedQA dataset stores each question as a JSON element, with the questions and options provided as keys. We parse the JSON and construct the question along with the choices.
Let’s start obtaining outputs from the model. The current task involves answering the provided medical question by selecting the correct answer from various options. Unlike creative tasks such as content writing or summarization, which may require the model to be imaginative and creative in its output, this is a knowledge-based task designed to test the model’s ability to answer questions based on knowledge encoded in its parameters. Therefore, we will use greedy decoding while generating the answer. Let’s define a helper function for parsing the model responses and calculating accuracy.
pattern = re.compile(r"([A-Z]).s*(.*)")
def parse_answer(response):
"""
Extracts the answer option from the predicted string.
Args:
- response (str): The string to search for the pattern.
Returns:
- str: The matched answer option if found or an empty string otherwise.
"""
match = re.search(pattern, response)
if match:
letter = match.group(1)
else:
letter = ""
return letter
def calculate_accuracy(ground_truth, predictions):
"""
Calculates the accuracy of predictions compared to ground truth labels.
Args:
- ground_truth (list): A list of true labels.
- predictions (list): A list of predicted labels.
Returns:
- float: The accuracy of predictions as a fraction of correct predictions over total predictions.
"""
return sum([1 if x==y else 0 for x,y in zip(ground_truth, predictions)]) / len(ground_truth)
ground_truth = []
for item in questions:
ans_options = item["options"]
correct_ans_option = ""
for key,value in ans_options.items():
if value == item["answer"]:
correct_ans_option = key
break
ground_truth.append(correct_ans_option)
zero_shot_llama_answers = []
for item in tqdm(questions):
zero_shot_prompt_messages = build_zero_shot_prompt(PROMPT, item)
prompt = tokenizer.apply_chat_template(zero_shot_prompt_messages, tokenize=False)
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=10, do_sample=False)
# https://github.com/huggingface/transformers/issues/17117#issuecomment-1124497554
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
zero_shot_llama_answers.append(gen_text.strip())
zero_shot_llama_predictions = [parse_answer(x) for x in zero_shot_llama_answers]
print(calculate_accuracy(ground_truth, zero_shot_llama_predictions))
We get a performance of 36% in the zero-shot setting. Not a bad start, but let’s see if we can push this performance further.
Prompting Llama 2 7B-Chat with a Few-Shot Prompt
Let’s now provide task demonstrations to the model. We use the three randomly sampled questions from the training set and append them to the model as task demonstrations. Fortunately, we can continue using the chat-template support provided by the Transformers library and the tokenizer to append our few-shot examples with minimal code changes.
def build_few_shot_prompt(system_prompt, content, few_shot_examples):
"""
Builds the few-shot prompt using provided examples.
Args:
system_prompt (str): Task description for the LLM
content (dict): The content for which to create a query, similar to the
structure required by `create_query`.
few_shot_examples (list of dict): Examples to simulate a hypothetical
conversation. Each dict must have "options" and an "answer".
Returns:
list of dict: A list of messages, simulating a conversation with
few-shot examples, followed by the current user query.
"""
messages = [{"role": "system", "content": system_prompt}]
for item in few_shot_examples:
ans_options = item["options"]
correct_ans_option = ""
for key, value in ans_options.items():
if value == item["answer"]:
correct_ans_option = key
break
messages.append({"role": "user", "content": create_query(item)})
messages.append({"role": "assistant", "content": "The answer is " + correct_ans_option + "."})
messages.append({"role": "user", "content": create_query(content)})
return messages
few_shot_prompts = read_jsonl_file("USMLE_few_shot_samples.jsonl")
Let’s visualize what our few-shot prompt looks like.
<s>[INST] <<SYS>>
You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response
<</SYS>>
A 30-year-old woman presents to the clinic because of fever, joint pain, and a rash on her lower extremities. She admits to intravenous drug use. Physical examination reveals palpable petechiae and purpura on her lower extremities. Laboratory results reveal a negative antinuclear antibody, positive rheumatoid factor, and positive serum cryoglobulins. Which of the following underlying conditions in this patient is responsible for these findings?
Options:
A. Hepatitis B infection
B. Hepatitis C infection
C. HIV infection
D. Systemic lupus erythematosus (SLE) [/INST] The answer is B. </s><s>[INST] A 10-year-old child presents to your office with a chronic cough. His mother states that he has had a cough for the past two weeks that is non-productive along with low fevers of 100.5 F as measured by an oral thermometer. The mother denies any other medical history and states that he has been around one other friend who also has had this cough for many weeks. The patient's vitals are within normal limits with the exception of his temperature of 100.7 F. His chest radiograph demonstrated diffuse interstitial infiltrates. Which organism is most likely causing his pneumonia?
Options:
A. Mycoplasma pneumoniae
B. Staphylococcus aureus
C. Streptococcus pneumoniae
D. Streptococcus agalactiae [/INST] The answer is A. </s><s>[INST] A 44-year-old with a past medical history significant for human immunodeficiency virus infection presents to the emergency department after he was found to be experiencing worsening confusion. The patient was noted to be disoriented by residents and staff at the homeless shelter where he resides. On presentation he reports headache and muscle aches but is unable to provide more information. His temperature is 102.2°F (39°C), blood pressure is 112/71 mmHg, pulse is 115/min, and respirations are 24/min. Knee extension with hips flexed produces significant resistance and pain. A lumbar puncture is performed with the following results:
Opening pressure: Normal
Fluid color: Clear
Cell count: Increased lymphocytes
Protein: Slightly elevated
Which of the following is the most likely cause of this patient's symptoms?
Options:
A. Cryptococcus
B. Group B streptococcus
C. Herpes simplex virus
D. Neisseria meningitidis [/INST] The answer is C. </s><s>[INST] A 21-year-old male presents to his primary care provider for fatigue. He reports that he graduated from college last month and returned 3 days ago from a 2 week vacation to Vietnam and Cambodia. For the past 2 days, he has developed a worsening headache, malaise, and pain in his hands and wrists. The patient has a past medical history of asthma managed with albuterol as needed. He is sexually active with both men and women, and he uses condoms “most of the time.” On physical exam, the patient’s temperature is 102.5°F (39.2°C), blood pressure is 112/66 mmHg, pulse is 105/min, respirations are 12/min, and oxygen saturation is 98% on room air. He has tenderness to palpation over his bilateral metacarpophalangeal joints and a maculopapular rash on his trunk and upper thighs. Tourniquet test is negative. Laboratory results are as follows:
Hemoglobin: 14 g/dL
Hematocrit: 44%
Leukocyte count: 3,200/mm^3
Platelet count: 112,000/mm^3
Serum:
Na+: 142 mEq/L
Cl-: 104 mEq/L
K+: 4.6 mEq/L
HCO3-: 24 mEq/L
BUN: 18 mg/dL
Glucose: 87 mg/dL
Creatinine: 0.9 mg/dL
AST: 106 U/L
ALT: 112 U/L
Bilirubin (total): 0.8 mg/dL
Bilirubin (conjugated): 0.3 mg/dL
Which of the following is the most likely diagnosis in this patient?
Options:
A. Chikungunya
B. Dengue fever
C. Epstein-Barr virus
D. Hepatitis A [/INST]
The prompt is quite long, given that we append three demonstrations. Let’s now run Llama-2 with the few-shot prompt and get the results:
few_shot_llama_answers = []
for item in tqdm(questions):
few_shot_prompt_messages = build_few_shot_prompt(PROMPT, item, few_shot_prompts)
prompt = tokenizer.apply_chat_template(few_shot_prompt_messages, tokenize=False)
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=10, do_sample=False)
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
few_shot_llama_answers.append(gen_text.strip())
few_shot_llama_predictions = [parse_answer(x) for x in few_shot_llama_answers]
print(calculate_accuracy(ground_truth, few_shot_llama_predictions))
We now get an overall accuracy of 41.67%. Not bad, nearly 6% improvement over zero-shot prompting with the same model!
What happens if we don’t adhere to the chat template?
Earlier, I observed that it is advisable to structure our prompt according to the prompt template that was used to fine-tune an LLM originally. Let’s verify if not adhering to the chat template hurts our performance. We create a function that builds a few-shot prompt using the same examples without adhering to the chat format.
def build_few_shot_prompt_wo_chat_template(system_prompt, content, few_shot_examples):
"""
Builds the few-shot prompt using provided examples, bypassing the chat-template
for Llama-2.
Args:
system_prompt (str): Task description for the LLM
content (dict): The content for which to create a query, similar to the
structure required by `create_query`.
few_shot_examples (list of dict): Examples to simulate a hypothetical
conversation. Each dict must have "options" and an "answer".
Returns:
str: few-shot prompt in non-chat format
"""
few_shot_prompt = ""
few_shot_prompt += "Task: " + system_prompt + "n"
for item in few_shot_examples:
ans_options = item["options"]
correct_ans_option = ""
for key, value in ans_options.items():
if value == item["answer"]:
correct_ans_option = key
break
few_shot_prompt += create_query(item) + "n" + "The answer is " + correct_ans_option + "." + "n"
few_shot_prompt += create_query(content) + "n"
return few_shot_prompt
Our prompts now look like this:
Task: You will be provided with a medical or clinical question, along with multiple possible answer choices. Pick the right answer from the choices.
Your response should be in the format "The answer is <correct_choice>". Do not add any other unnecessary content in your response
A 30-year-old woman presents to the clinic because of fever, joint pain, and a rash on her lower extremities. She admits to intravenous drug use. Physical examination reveals palpable petechiae and purpura on her lower extremities. Laboratory results reveal a negative antinuclear antibody, positive rheumatoid factor, and positive serum cryoglobulins. Which of the following underlying conditions in this patient is responsible for these findings?
Options:
A. Hepatitis B infection
B. Hepatitis C infection
C. HIV infection
D. Systemic lupus erythematosus (SLE)
The answer is B.
A 10-year-old child presents to your office with a chronic cough. His mother states that he has had a cough for the past two weeks that is non-productive along with low fevers of 100.5 F as measured by an oral thermometer. The mother denies any other medical history and states that he has been around one other friend who also has had this cough for many weeks. The patient's vitals are within normal limits with the exception of his temperature of 100.7 F. His chest radiograph demonstrated diffuse interstitial infiltrates. Which organism is most likely causing his pneumonia?
Options:
A. Mycoplasma pneumoniae
B. Staphylococcus aureus
C. Streptococcus pneumoniae
D. Streptococcus agalactiae
The answer is A.
A 44-year-old with a past medical history significant for human immunodeficiency virus infection presents to the emergency department after he was found to be experiencing worsening confusion. The patient was noted to be disoriented by residents and staff at the homeless shelter where he resides. On presentation he reports headache and muscle aches but is unable to provide more information. His temperature is 102.2°F (39°C), blood pressure is 112/71 mmHg, pulse is 115/min, and respirations are 24/min. Knee extension with hips flexed produces significant resistance and pain. A lumbar puncture is performed with the following results:
Opening pressure: Normal
Fluid color: Clear
Cell count: Increased lymphocytes
Protein: Slightly elevated
Which of the following is the most likely cause of this patient's symptoms?
Options:
A. Cryptococcus
B. Group B streptococcus
C. Herpes simplex virus
D. Neisseria meningitidis
The answer is C.
A 21-year-old male presents to his primary care provider for fatigue. He reports that he graduated from college last month and returned 3 days ago from a 2 week vacation to Vietnam and Cambodia. For the past 2 days, he has developed a worsening headache, malaise, and pain in his hands and wrists. The patient has a past medical history of asthma managed with albuterol as needed. He is sexually active with both men and women, and he uses condoms “most of the time.” On physical exam, the patient’s temperature is 102.5°F (39.2°C), blood pressure is 112/66 mmHg, pulse is 105/min, respirations are 12/min, and oxygen saturation is 98% on room air. He has tenderness to palpation over his bilateral metacarpophalangeal joints and a maculopapular rash on his trunk and upper thighs. Tourniquet test is negative. Laboratory results are as follows:
Hemoglobin: 14 g/dL
Hematocrit: 44%
Leukocyte count: 3,200/mm^3
Platelet count: 112,000/mm^3
Serum:
Na+: 142 mEq/L
Cl-: 104 mEq/L
K+: 4.6 mEq/L
HCO3-: 24 mEq/L
BUN: 18 mg/dL
Glucose: 87 mg/dL
Creatinine: 0.9 mg/dL
AST: 106 U/L
ALT: 112 U/L
Bilirubin (total): 0.8 mg/dL
Bilirubin (conjugated): 0.3 mg/dL
Which of the following is the most likely diagnosis in this patient?
Options:
A. Chikungunya
B. Dengue fever
C. Epstein-Barr virus
D. Hepatitis A
Let’s now evaluate Llama 2 with these prompts and observe how it performs:
few_shot_llama_answers_wo_chat_template = []
for item in tqdm(questions):
prompt = build_few_shot_prompt_wo_chat_template(PROMPT, item, few_shot_prompts)
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=10, do_sample=False)
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
few_shot_llama_answers_wo_chat_template.append(gen_text.strip())
few_shot_llama_predictions_wo_chat_template = [parse_answer(x) for x in few_shot_llama_answers_wo_chat_template]
print(calculate_accuracy(ground_truth, few_shot_llama_predictions_wo_chat_template))
We achieve an accuracy of 36%. This is nearly 6% lower than our earlier few-shot score. This reinforces our previous argument that it is crucial to structure our prompts according to the template used to fine-tune the LLM we intend to work with. Prompt templates matter!
Prompting Llama 2 7B-Chat with CoT Prompting
Let’s conclude by evaluating CoT prompting. Remember, our dataset includes questions designed to test medical knowledge through the USMLE exam. Such questions often require both factual recall and conceptual reasoning to answer. This makes it a perfect task for testing how well CoT works.
First, we must provide an example CoT prompt to the model to demonstrate how to reason about a question. For this purpose, we will use one of the prompts from Google’s MedPALM paper [12].

We use this five-shot prompt for evaluating the models. Since this prompt style differs slightly from our earlier prompts, let’s create some helper functions again to process them and obtain the outputs. While utilizing CoT prompting, we generate the output with a larger output token count to enable the model to “think” and “reason” before answering the question.
def create_query_cot(item):
"""
Creates the input for the model using the question and the multiple choice options in the CoT format.
Args:
item (dict): A dictionary containing the question and options.
Expected keys are "question" and "options", where "options" is another
dictionary with keys "A", "B", "C", and "D".
Returns:
str: A formatted query combining the question and options, ready for use.
"""
query = "Question: " + item["question"] + "n" +
"(A) " + item["options"]["A"] + " " +
"(B) " + item["options"]["B"] + " " +
"(C) " + item["options"]["C"] + " " +
"(D) " + item["options"]["D"]
return query
def build_cot_prompt(instruction, input_question, cot_examples):
"""
Builds the few-shot prompt for the GPT API using provided examples.
Args:
content (dict): The content for which to create a query, similar to the
structure required by `create_query`.
few_shot_examples (list of dict): Examples to simulate a hypothetical
conversation. Each dict must have "question" and an "explanation".
Returns:
list of dict: A list of messages, simulating a conversation with
few-shot examples, followed by the current user query.
"""
messages = [{"role": "system", "content": instruction}]
for item in cot_examples:
messages.append({"role": "user", "content": item["question"]})
messages.append({"role": "assistant", "content": item["explanation"]})
messages.append({"role": "user", "content": create_query_cot(input_question)})
return messages
def parse_answer_cot(text):
"""
Extracts the choice from a string that follows the pattern "Answer: (Choice) Text".
Args:
- text (str): The input string from which to extract the choice.
Returns:
- str: The extracted choice or a message indicating no match was found.
"""
# Regex pattern to match the answer part
pattern = r"Answer: (.*)"
# Search for the pattern in the text and extract the matching group
match = re.search(pattern, text)
if match:
if len(match.group(1)) > 1:
return match.group(1)[1]
else:
return ""
else:
return ""
cot_llama_answers = []
for item in tqdm(questions):
cot_prompt = build_cot_prompt(COT_INSTRUCTION, item, COT_EXAMPLES)
prompt = tokenizer.apply_chat_template(cot_prompt, tokenize=False)
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=100, do_sample=False)
gen_text = tokenizer.batch_decode(outputs.detach().cpu().numpy()[:, input_ids.shape[1]:], skip_special_tokens=True)[0]
cot_llama_answers.append(gen_text.strip())
cot_llama_predictions = [parse_answer_cot(x) for x in cot_llama_answers]
print(calculate_accuracy(ground_truth, cot_llama_predictions))
Our performance dips to 20% using CoT prompting for Llama 2–7B. This is generally in line with the findings of the CoT paper [6], where the authors mention that CoT is an emergent property for LLMs that improves with the scale of the model. That being said, let’s analyze why the performance dipped drastically.
Failure Modes in CoT for Llama 2
We sample a few of the responses provided by Llama 2 on some of the test set questions to analyze error cases:


While CoT prompting allows the model to “think” before arriving at the final answer, in most cases, the model either does not arrive at a conclusive answer or mentions the answer in a format inconsistent with our example demonstrations. A failure mode I haven’t analyzed here, but potentially worth exploring, is to check cases in the test set where the model “reasons” incorrectly and, therefore, arrives at the wrong answer. This is beyond the scope of the current article and my medical knowledge, but it is certainly something I intend to revisit later.
Prompting GPT-3.5 with a Zero-Shot Prompt
Let’s begin defining some helper functions that help us process these inputs for utilizing the GPT API. You would need to generate an API key to use the GPT-3.5 API. You can set the API key in Windows using:
setx OPENAI_API_KEY “your-api-key-here”
or in Linux using:
export OPENAI_API_KEY “your-api-key-here”
in the current session you are using.
from openai import OpenAI
import re
from tqdm import tqdm
# assuming you have already set the secret key using env variable
# if not, you can also instantiate the OpenAI client by providing the
# secret key directly like so:
# I highly recommend not doing this, as it is a best practice to not store
# the api key in your code directly or in any plain-text file for security
# reasons.
# client = OpenAI(api_key = "")
client = OpenAI()
def get_response(messages, model_name, temperature = 0.0, max_tokens = 10):
"""
Obtains the responses/answers of the model through the chat-completions API.
Args:
messages (list of dict): The built messages provided to the API.
model_name (str): Name of the model to access through the API
temperature (float): A value between 0 and 1 that controls the randomness of the output.
A temperature value of 0 ideally makes the model pick the most likely token, making the outputs (mostly) deterministic.
max_tokens (int): Maximum number of tokens that the model should generate
Returns:
str: The response message content from the model.
"""
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
This function now constructs the prompt in the format for the GPT-3.5 API. We can interact with the GPT-3.5 model through the chat-completions API provided by the library. The API requires messages to be structured as a list of dictionaries for sending to the API. Each message must specify the role and the content. The conventions followed regarding the “system”, “user”, and “assistant” roles are the same as those described earlier for the Llama-7B Chat Model.
Let’s now use the GPT-3.5 API to process the test set and obtain the responses. After receiving all the responses, we extract the options from the model’s responses and calculate the accuracy.
zero_shot_gpt_answers = []
for item in tqdm(questions):
zero_shot_prompt_messages = build_zero_shot_prompt(PROMPT, item)
answer = get_response(zero_shot_prompt_messages, model_name = "gpt-3.5-turbo", temperature = 0.0, max_tokens = 10)
zero_shot_gpt_answers.append(answer)
zero_shot_gpt_predictions = [parse_answer(x) for x in zero_shot_gpt_answers]
print(calculate_accuracy(ground_truth, zero_shot_gpt_predictions))
Our performance now stands at 63%. This is a significant improvement from the performance of Llama 2–7B. This isn’t surprising, given that GPT-3.5 is likely much larger and trained on more data than Llama 2–7B, along with other proprietary optimizations that OpenAI may have included to the model. Let’s see how well few-shot prompting works now.
Prompting GPT-3.5 with a Few-Shot Prompt
To provide few-shot examples to the LLM, we reuse the three examples we sampled from the training set and append them to the prompt. For GPT-3.5, we create a list of messages with examples, similar to our earlier processing for Llama 2. The inputs are appended using the “user” role, and the corresponding option is presented in the “assistant” role. We reuse the earlier function for building few-shot prompts.
This is again equivalent to creating a fictional multi-turn conversation history provided to GPT-3.5, where each turn corresponds to an example demonstration.
Let’s now obtain the outputs using GPT-3.5.
few_shot_gpt_answers = []
for item in tqdm(questions):
few_shot_prompt_messages = build_few_shot_prompt(PROMPT, item, few_shot_prompts)
answer = get_response(few_shot_prompt_messages, model_name= "gpt-3.5-turbo", temperature = 0.0, max_tokens = 10)
few_shot_gpt_answers.append(answer)
few_shot_gpt_predictions = [parse_answer(x) for x in few_shot_gpt_answers]
print(calculate_accuracy(ground_truth, few_shot_gpt_predictions))
We’ve managed to push the performance from 63% to 67% using few-shot prompting! This is a significant improvement, highlighting the value of providing task demonstrations to the model.
Prompting GPT-3.5 with CoT Prompting
Let’s now evaluate GPT-3.5 with CoT prompting. We re-use the same CoT prompt and get the outputs:
cot_gpt_answers = []
for item in tqdm(questions):
cot_prompt = build_cot_prompt(COT_INSTRUCTION, item, COT_EXAMPLES)
answer = get_response(cot_prompt, model_name= "gpt-3.5-turbo", temperature = 0.0, max_tokens = 100)
cot_gpt_answers.append(answer)
cot_gpt_predictions = [parse_answer_cot(x) for x in cot_gpt_answers]
print(calculate_accuracy(ground_truth, cot_gpt_predictions))
Using CoT prompting with GPT-3.5 results in an accuracy of 71%! This represents a further 4% improvement over few-shot prompting. It appears that enabling the model to “think” out loud before answering the question is beneficial for this task. This is also consistent with the findings of the paper [6] that CoT unlocked performance improvements for larger parameter models.
Conclusion and Takeaways:
Prompting is a crucial skill for working with Large Language Models (LLMs), and understanding that there are various tools in the prompting toolkit that can help extract better performance from LLMs for your tasks depending on the context. I hope this article serves as a broad and (hopefully!) accessible introduction to this subject. However, it does not aim to provide a comprehensive overview of all prompting strategies. Prompting remains a highly active field of research, with numerous methods being introduced such as ReAct [13], Tree-of-Thought prompting [14] etc. I recommend exploring these techniques to better understand them and enhance your prompting toolkit.
Reproducibility
In this article, I’ve aimed to make all experiments as deterministic and reproducible as possible. We use greedy decoding to obtain our outputs for zero-shot, few-shot, and CoT prompting with Llama-2. While these scores should technically be reproducible, in rare cases, Cuda/GPU-related or library issues could lead to slightly different results.
Similarly, when obtaining responses from the GPT-3.5 API, we use a temperature of 0 to get results and choose only the next most likely token without sampling for all prompt settings. This makes the results “mostly deterministic”, so it is possible that sending the same prompts to GPT-3.5 again may result in slightly different results.
I have provided the outputs of the models under all prompt settings, along with the sub-sampled test set, few-shot prompt examples, and CoT prompt (from the MedPALM paper) for reproducing the scores reported in this article.
References:
All papers referred to in this blog post are listed here. Please let me know if I might have missed out any references, and I will add them!
[1] Yang, J., Jin, H., Tang, R., Han, X., Feng, Q., Jiang, H., … & Hu, X. (2023). Harnessing the power of llms in practice: A survey on chatgpt and beyond. arXiv preprint arXiv:2304.13712.
[2] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
[3] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877–1901.
[4] Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., … & Le, Q. V. (2021). Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
[5] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730–27744.
[6] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824–24837.
[7] Thoppilan, R., De Freitas, D., Hall, J., Shazeer, N., Kulshreshtha, A., Cheng, H. T., … & Le, Q. (2022). Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
[8] Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., … & Fiedel, N. (2023). Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240), 1–113.
[9] Jin, D., Pan, E., Oufattole, N., Weng, W. H., Fang, H., & Szolovits, P. (2021). What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14), 6421.
[10] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., … & Scialom, T. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
[11] https://platform.openai.com/docs/models/gpt-3-5-turbo
[12] Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., … & Natarajan, V. (2023). Large language models encode clinical knowledge. Nature, 620(7972), 172–180.
[13] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., & Cao, Y. (2022, September). ReAct: Synergizing Reasoning and Acting in Language Models. In The Eleventh International Conference on Learning Representations.
[14] Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., & Narasimhan, K. (2024). Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36.
An Introduction to Prompting for LLMs was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
An Introduction to Prompting for LLMs
Go Here to Read this Fast! An Introduction to Prompting for LLMs