Lingua Franca — Entity-Aware Machine Translation Approach for Question Answering over Knowledge Graphs
Towards a lingua franca for knowledge graph question answering systems
TLDR
Machine Translation (MT) can enhance existing Question Answering (QA) systems, which have limited language capabilities, by enabling them to support multiple languages. However, there is one major drawback of MT — often, it fails at translating named entities that are not translatable word-by-word. For example, the German title of the movie “The Pope Must Die” is “Ein Papst zum Küssen”, which has the literal translation: “A Pope to Kiss”. As the correctness of the named entities is crucial for QA systems, such a challenge has to be handled properly. In this article, we present our entity-aware MT approach called “Lingua Franca”. It takes advantage of knowledge graphs in order to use information stored there to ensure the correctness of named entities’ translations. And yes, it works!
The Challenge
Achieving high-quality translations depends significantly on accurately translating named entities (NEs) within sentences. Various methods have been proposed to enhance the translation of NEs, including approaches that integrate knowledge graphs (KGs) to improve entity translation, recognizing the pivotal role of entities in overall translation quality within the context of QA. It is important to note that the quality of NE translation is not an isolated objective; it has broader implications for systems involved in tasks such as information retrieval (IR) or knowledge graph-based question answering (KGQA). In this article, we will delve into a detailed discussion of machine translation (MT) and KGQA.
The significance of KGQA systems lies in their ability to provide factual answers to users based on structured data (see figure below).
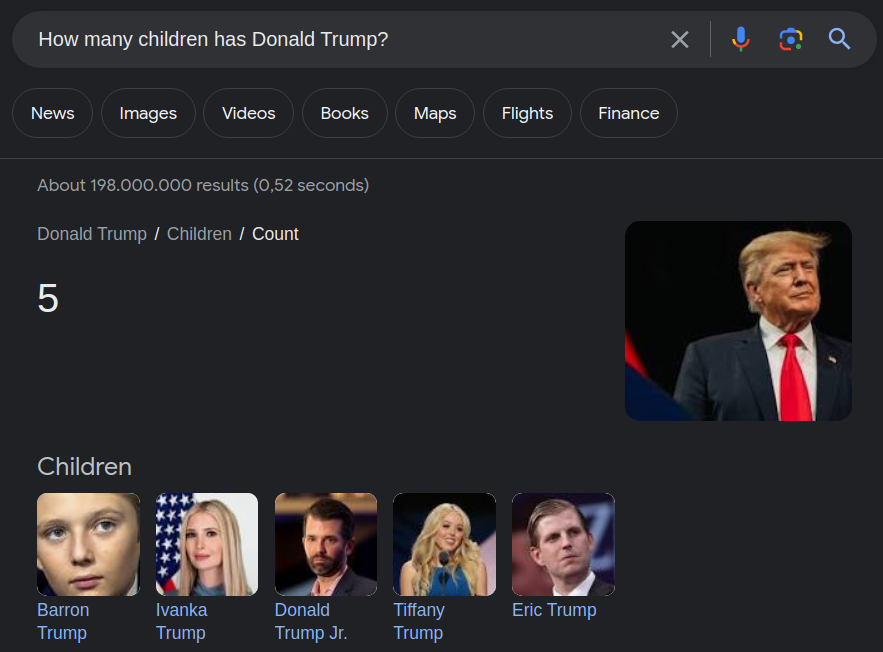
KGQA systems are core components in modern search engines enabling them to give direct answers to their users (Google Search, screenshot by author).
Additionally, multilingual KGQA systems play a crucial role in addressing the “digital language divide” on the Web. For instance, Germany-related Wikipedia articles, especially those dedicated to cities or people, contain more information in the German language than in other languages — this information imbalance can be handled by the multilingual KGQA system that is, by the way, the core of all modern search engines.
One of the options for enabling the KGQA system to answer questions in different languages is to use MT. However, an off-the-shelf MT faces notable challenges when it comes to translating NEs, as numerous entities are not readily translatable and demand background knowledge for accurate interpretation. For instance, consider the German title of the movie “The Pope Must Die,” which is “Ein Papst zum Küssen.” The literal translation, “A Pope to Kiss,” underscores the need for contextual understanding beyond a straightforward translation approach.
Given the limitations of conventional MT methods in translating entities, the combination of KGQA systems with MT often results in distorted NEs, significantly reducing the likelihood of accurate question answering. Therefore, there is a need for an enhanced approach to incorporate background knowledge about NEs in multiple languages.
Our Approach
This article introduces and implements a novel approach for Named-Entity Aware Machine Translation (NEAMT) aimed at enhancing the multilingual capabilities of KGQA systems. The central concept of NEAMT involves augmenting the quality of MT by incorporating information from a knowledge graph (e.g. Wikidata and DBpedia). This is achieved through the utilization of the “entity-replacement” technique.
As the data for the evaluation, we use the QALD-9-plus and QALD-10 datasets. Then, we use multiple components within our NEAMT framework, which are available in our repository. Finally, the approach is evaluated on two KGQA systems: QAnswer and Qanary. The detailed description of the approach is available at the figure below.
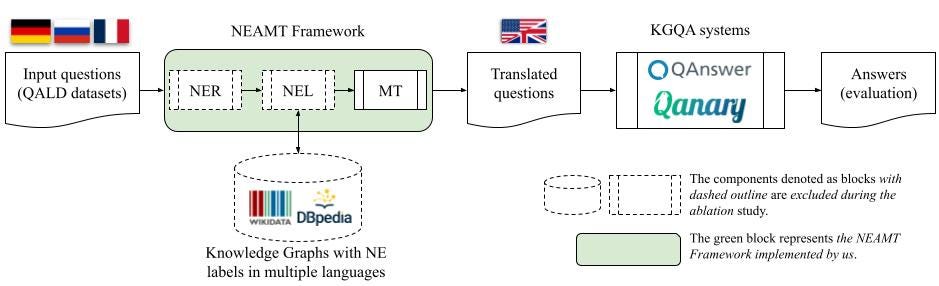
In essence, our approach, during the translation process, preserves known NEs using the entity-replacement technique. Subsequently, these entities are substituted with their corresponding labels from a knowledge graph in the target translation language. This meticulous process ensures the precise translation of questions before they are addressed by a KGQA system.
Adhering to the insights from our previous article, we designate English as the common target translation language, leading to the nomenclature of our approach as “Lingua Franca” (inspired by the meaning of “bridge” or “link” language). It is essential to note that our framework is versatile and can seamlessly adapt to any other language as the target language. Importantly, Lingua Franca extends beyond the scope of KGQA and finds applicability in various entity-oriented search applications.
The Lingua Franca approach comprises three main steps: (1) Named Entity Recognition (NER) and Named Entity Linking (NEL), (2) the application of the entity-replacement technique based on identified named entities, and (3) utilizing a machine translation tool to generate text in a target language while considering information from the preceding steps. Here, English is consistently used as the target language, aligning with related research that deems it the most optimal strategy for Question Answering (QA) quality. However, the approach is not limited to English, and other languages can be employed if necessary.
The approach is implemented as an open-source framework, allowing users to build their Named-Entity Aware Machine Translation (NEAMT) pipelines by integrating custom NER, NEL, and MT components (see our GitHub). The details of the Lingua Franca approach for all settings are illustrated in the provided example, as shown in the figure below.
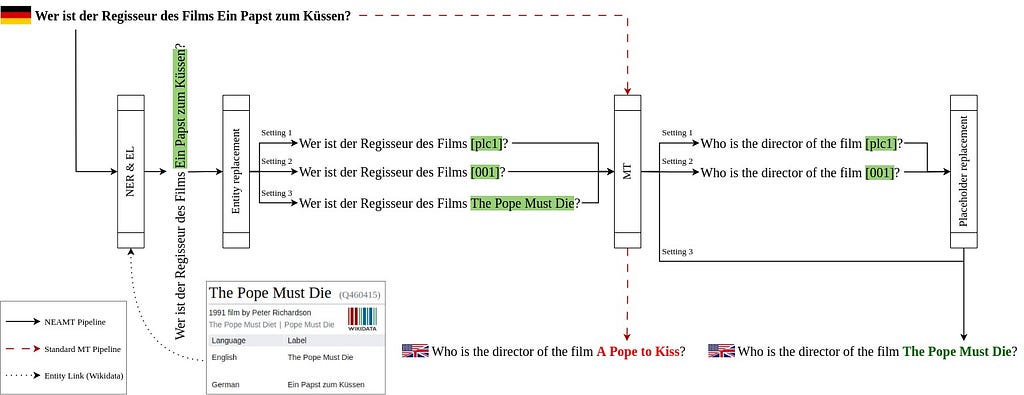
The experimental findings in this study strongly advocate for the superiority of Lingua Franca over standard MT tools when combined with KGQA systems.
Experimental Results
In evaluating each entity-replacement setting, the rate of corrupted placeholders or NE labels after processing through an MT tool was calculated. This rate serves as an indicator of the actual NE translation quality for the approach-related pipelines. The updated statistics are as follows:
- Setting 1 (string-like placeholders): 6.63% of the placeholders were lost or corrupted.
- Setting 2 (numerical placeholders): 2.89% of the placeholders were lost or corrupted.
- Setting 3 (replacing the NEs with their English labels before translation): 6.16% of the labels were corrupted.
As a result, with our approach, we can confidently assert that up to 97.11% (Setting 2) of the recognized NEs in a text were translated correctly.
We analyzed the results regarding QA quality while taking into account the following experimental components: an approach pipeline or a standard MT tool, a source language, and a KGQA benchmark. The figure below illustrates the comparison between the approach and standard MT — these results can be interpreted as an ablation study.
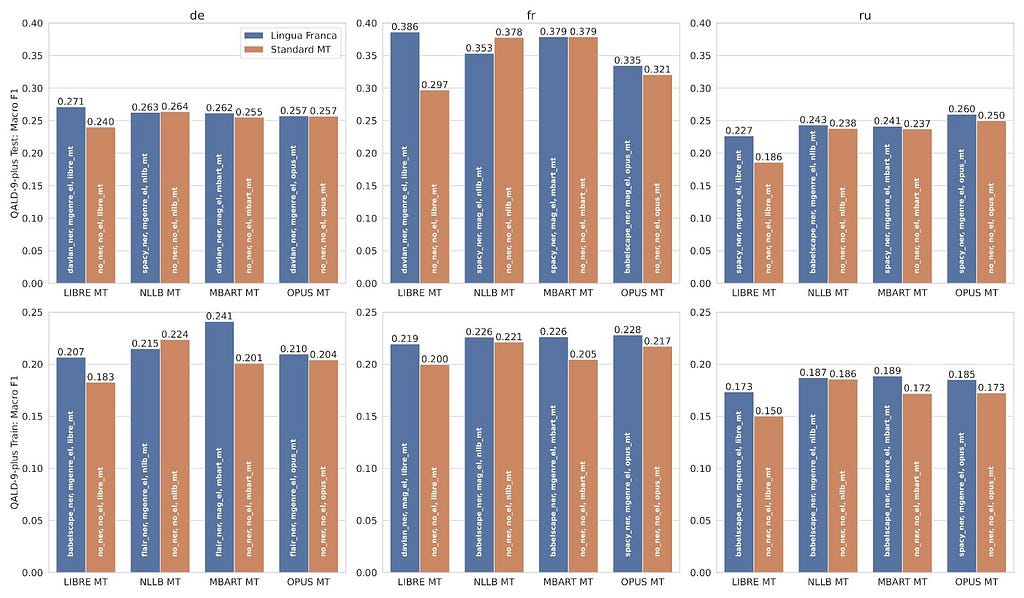
The grouped bar plot illustrates the Macro F1 score (obtained using Gerbil-QA) concerning each language and split. In the context of the ablation study, each group consists of two bars: the first one pertains to the best approach proposed by us, while the second bar reflects the performance of a standard MT tool (baseline).
We observed that in the majority of the experimental cases (19 out of 24) the KGQA systems that were using our approach outperformed the ones that used standard MT tools. To verify the statement above, we conducted the Wilcoxon signed-rank test on the same data. Based on the test results (p-value = 0.0008, with α = 0.01), we rejected the null hypothesis which denotes that the QA quality results have no difference, i.e., while combining KGQA with standard MT and while combining KGQA with the approach. Therefore, we conclude that the approach, which relies on our NEAMT framework, significantly improves the QA quality while answering multilingual questions in comparison to standard MT tools.
The reproducibility of the experiments was ensured by repeating them and calculating the Pearson’s correlation coefficient between all the QA quality metrics. The resulting coefficient of 0.794 corresponds to the borderline value between strong and very strong correlation. Therefore, we assume that our experiments are reproducible.
Conclusion
This paper introduces the NEAMT approach called Lingua Franca. Designed to enhance multilingual capabilities and improve QA quality in comparison to standard MT tools, Lingua Franca is tailored for use with KGQA systems in order to enlarge the scope of its possible users. The implementation and evaluation of Lingua Franca utilize a modular NEAMT framework developed by the authors, with detailed information provided in the section on Experiments. The key contributions of the paper include: (1) being the first, to the best of our knowledge, to combine the NEAMT approach (i.e., Lingua Franca) with KGQA; (2) presenting an open-source modular framework for NEAMT, allowing the research community to build their own MT pipelines; and (3) conducting a comprehensive evaluation and ablation study to demonstrate the effectiveness of the Lingua Franca approach.
For future work, we aim to expand our experimental setup to encompass a broader range of languages, benchmarks, and KGQA systems. To address damaged placeholders in the entity-replacement process, we plan to fine-tune the MT models using this data. Additionally, a more detailed error analysis, focusing on error propagation, will be conducted.
Do not forget to check our full research paper and the GitHub repository.
Acknowledgments
This research has been funded by the Federal Ministry of Education and Research, Germany (BMBF) under Grant numbers 01IS17046 and 01QE2056C, as well as the Ministry of Culture and Science of North Rhine-Westphalia, Germany (MKW NRW) under Grant Number NW21–059D. This research also was funded within the research project QA4CB — Entwicklung von Question-Answering-Komponenten zur Erweiterung des Chatbot-Frameworks.
Lingua Franca — Entity-Aware Machine Translation Approach for Question Answering over Knowledge… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Lingua Franca — Entity-Aware Machine Translation Approach for Question Answering over Knowledge…