

My personal take on justifying the existence of Data Mesh
A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation.
When I heard the words ‘decentralised data architecture’, I was left utterly confused at first! In my then limited experience as a Data Engineer, I had only come across centralised data architectures and they seemed to be working very well. So, I was left wondering what was it that we wanted to solve using a decentralised data architecture? Or were we creating a new problem that did not ever exist in the first place?
Where did I look?
The obvious answer — Data Mesh by Zhamak Dehghani.
A great book that takes you on a journey of an organisation that implements this concept and overcomes some unique challenges. A highly recommended read for those who may be keen to learn more about it.
But in order to justify why this concept came into existence, I thought it’d be great to look back in time and understand the evolution of the data landscape. So here goes my overly-simplified take.
Evolution of the data landscape
1980s — Inception
- Relational databases came into existence.
- Organizations began to use relational databases for ‘everything’.
- Databases were overwhelmed with transactional and analytical workloads.
Result:
- Data warehouse was born.
Early 1990s — Scale
- Analytical workloads started to get complex.
- Data volumes started to grow.
- Performance needed improvement.
Result:
- The concept of Massively Parallel Processing (MPP) was introduced — data distributed across clusters.

Late 1990s to Early 2000s – Productize
- Demand for reporting kept growing.
- Architectures became complex.
- Business units required data relevant to their analysis.
Result:
- Companies started to sell pre-configured data warehouses as products.
- The concept of `Data Marts` was introduced.

2004 to 2010 — The elephant enters the room
- New wave of applications emerged — Social Media, Software observability, etc.
- New data formats emerged — JSON, Avro, Parquet, XML etc.
Result:
- Hadoop & NoSQL frameworks emerged.
- Data lakes were introduced to store the new data formats.

2010 to 2020 – The Cloud Data Warehouse
- Enterprises now wanted quick data analytics without yesterday’s constraints of flexibility, processing power and scale.
- Examples include: Amazon Redshift, Google BigQuery, Snowflake, Azure Synapse Analytics, Databricks etc.
Result:
- Cloud data warehouse offerings emerged as preferred solutions for relational and semi-structured data.
So what was missing?

If we look at this generic flow of data in an organisation using a centralised data architecture, we realise that there are 3 touch points for the data:
- Data Producers
- Central Data Team
- Data Consumers
Now let’s ask ourselves a few questions to start with:
- Who manages the data warehouse?
- Which team responds to data requests?
- Which team is responsible for ensuring data quality?
- Which team is expected to be the SME for data?
When I asked these questions to a bunch of people, I got one common answer across all questions (in combination with others)— option B, Central Data Team.
So we can infer that the central data team needs to:
- Manage data warehouse
- Serve data requests
- Ensure data quality
- Be SMEs for the data in the data warehouse
And the list goes on.
So what was missing?
As an enterprise continues to grow, the central data team tends to become the bottleneck in gaining actionable insights from data.
Central data teams end up having high knowledge burden and an ever increasing pressure of delivery.
This builds my case to justify the existence of the decentralised data architecture popularly known as the Data Mesh.
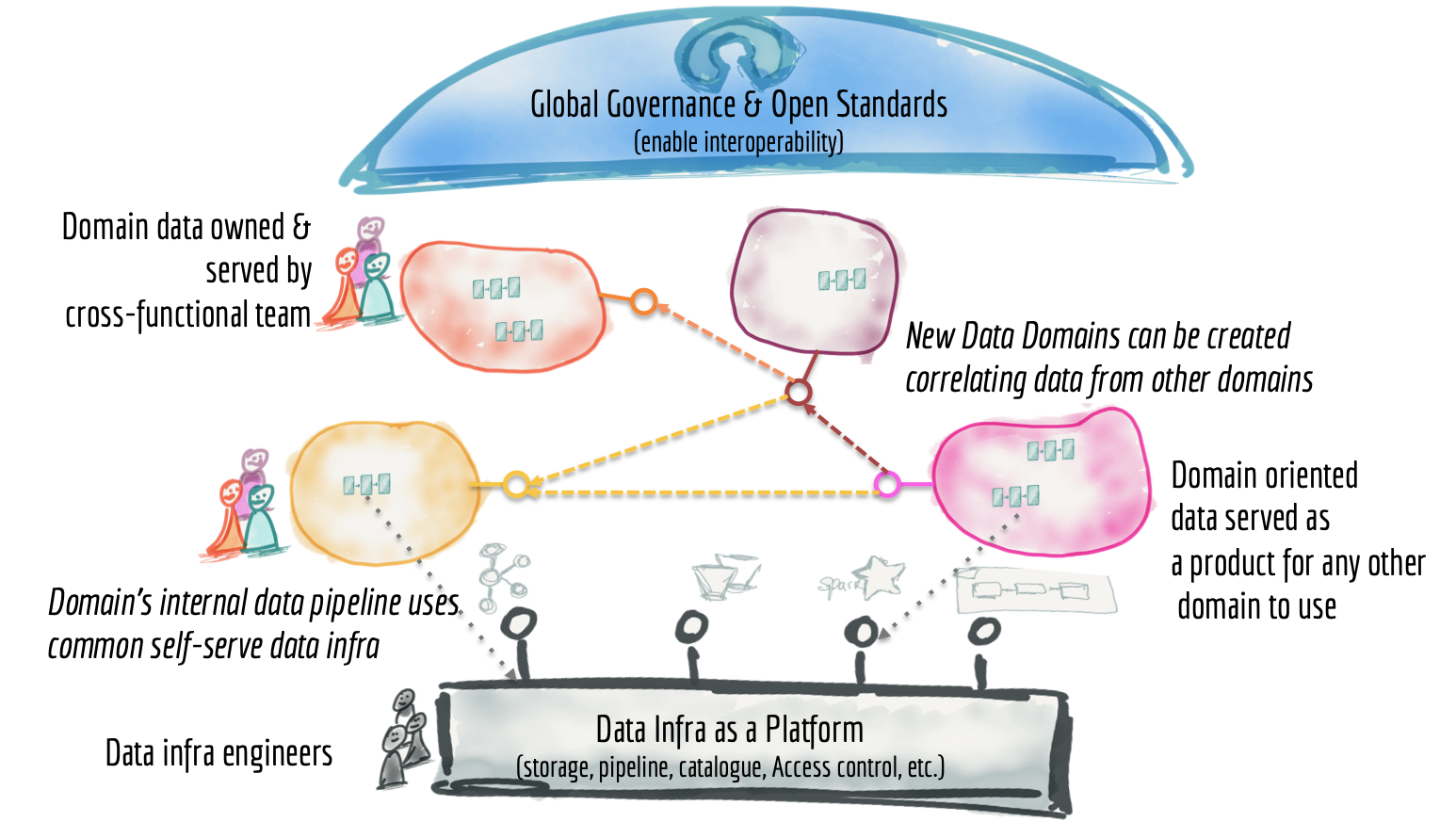
Data Mesh is a type of analytical architecture but most importantly an operating model that shifts the ownership of analytical data to teams that most intimately know and own the data — the data producers and consumers.
This image shows a high-level view of the Data Mesh Architecture:
https://martinfowler.com/articles/data-monolith-to-mesh/data-mesh.png
I won’t get into the principles or logical architecture of Data Mesh as there are many articles out there that do justice to it. Here are a few of my favorites:
References:
- https://www.oreilly.com/library/view/data-mesh/9781492092384/
- https://martinfowler.com/articles/data-monolith-to-mesh.html
- https://www.snowflake.com/wp-content/uploads/2017/09/Past-Present-Future-DW-FINAL.pdf
A Prequel to Data Mesh was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Prequel to Data Mesh

{kind=link}