

A practical tutorial for setting up a local dev environment using Docker Container

Motivation
An essential part of a data scientist’s daily work involves managing and maintaining a development environment. Our work goes considerably more smoothly when the development environment is kept up-to-date and closely reflects the production environment; when it isn’t, things start to get messy. Proficiency with the CI/CD pipeline and devops can be quite advantageous in a larger environment. Providing developments that are simple to integrate and put into production is a data scientist’s first priority.
This is where containers come into play; by encapsulating our development environment, they allow us to save time and effort.
In this blog post, I would provide a step-by-step guidance on how to set up a docker environment. I’ll be using a Linux environment, with a Python version 3.8, connected to a Git repo of your choice. To illustrate, I created a repo with an algorithm that determines whether a given text is more likely to be AI generated or written by a human.
Who could benefit from working on a docker container environment?
You probably don’t need to use containers if you’re a developer working on a side project and don’t care about deploying it to production. However, this one is a necessity if you are part of a team that uses the CI/CD pipeline.
I can think of few daily examples why containerization is rather important:
- Assume for the moment that you are working on several projects with varying dependencies and environment settings. Without using containers, it can be very challenging to switch between them.
- A new developer is joining the team and you want him to easily set up a working environment. Without containers, he or she will have to work on their local machine which probably doesn’t have the same requirements and properties as the other team members have.
- You had some tests or changes with your dependencies which are now not compatible with each other. In this case, rolling back the changes will be a time-consuming task. Alternatively, you may just create a new container and resume normal operations.
What is a container?
The concept of containers was first introduced in the 1970’s. Imagine a container as an isolated working environment — a server that we can define from scratch. We can decide what will be the properties of this server such as the operating system, python interpreter version and library dependencies. The server is sustained by relying on your machine resources. Another property of the container is that it doesn’t have access to our storage, unless we explicitly grant it permission. A good practice is to mount a folder we want to be included in our container scope.
In a nutshell, working with containers include the following steps:
1. Define the container environment using Dockerfile
2. Creating a docker image based on the Dockerfile
3. Creating a container based on docker image
This process can be easily shared among the team members and containers can be recreated over and over as needed.
What is Dockerfile?
As said above, a container is a capsulated environment for running our algorithms. This environment is supported by the docker extension responsible for supporting containerization.
In order to do so, we first need to define a dockerfile which specifies our system requirements. Think of the dockerfile as a document or a ‘recipe’ which defines our container template, which is called the docker image.
Here is an example for a dockerfile we will use as part of this tutorial:
FROM ubuntu:20.04
# Update and install necessary dependencies
RUN apt-get update &&
apt-get install -y python3-pip python3.8 git &&
apt-get clean
# Set working directory
WORKDIR /app
# Copy the requirements file and install dependencies
COPY requirements.txt .
RUN pip3 install --no-cache-dir -r requirements.txt
# Install transformers separately without its dependencies
RUN pip3 install --no-cache-dir transformers
This dockerfile contains several important steps:
(1) We import base images for having an Ubuntu environment.
(2) we install pip, python and git. The apt-get is a linux command for package handling.
(3) We set our workdir name (in this example it is /app)
(4) We install our requirements detailed in the requirements.txt file
Dockerfile provides us with a lot of flexibility. For instance, my repo relies on the transformers library without its dependencies, so I installed it separately (the last row in the Dockerfile).
Note — Working with containers offers many benefits in terms of speed and agility, yet there are drawbacks as well. Safety is one of them. Container images uploaded by untrusted resources might contain malicious content. Make sure you are using a trusted source and that your container is configured properly. Another option is to employ security tools like snyk, which scan your docker image for any potential vulnerabilities.

Set up a Container
Preliminary Prerequisites
Before we create a docker container, we first need to make sure our local working environment is ready. Let’s make sure we have the following checklist:
1. VS Code as our code editor : https://code.visualstudio.com/
2. Git for version control management: https://git-scm.com/downloads
3. Github user: https://github.com/
4. https://www.docker.com/
After you complete all these prerequisites, make sure to sign in to the docker app you have installed. This will enable us to create a docker container and track it’s status
Step 1 — Cloning the Repo
To begin, let’s select a repo to work with. Here I provided a repo containing an algorithm which estimates whether a text is AI generated by combining both the model’s perplexity value given a text and the number of spelling errors. Higher perplexity implies that it is more difficult for LLM to predict the next word, hence wasn’t generated by a human.
The repo’s link:
GitHub – Idoleshem/setup_a_local_container
On github, Click code and copy the HTTPS address as follows:
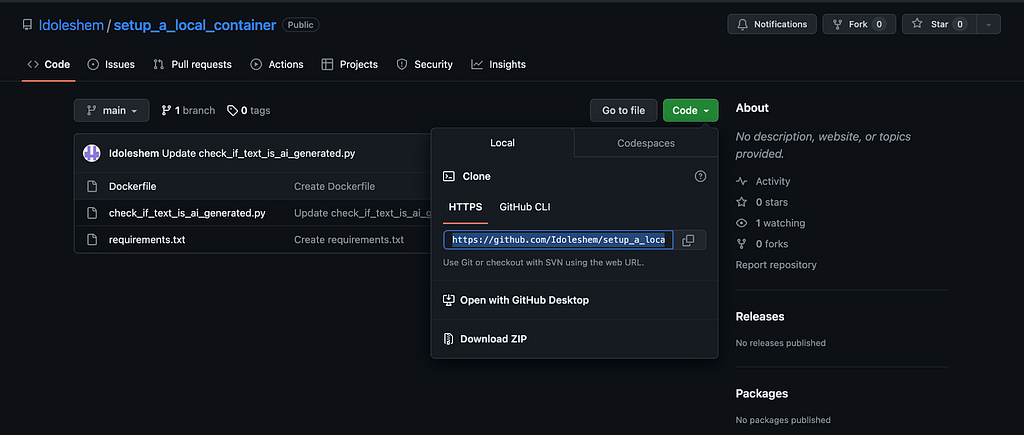
After that, open the VS Code, and clone a repo you wish to include in your container. make sure VS Code is connected to your github account. Alternatively, you can also init a new git repo.
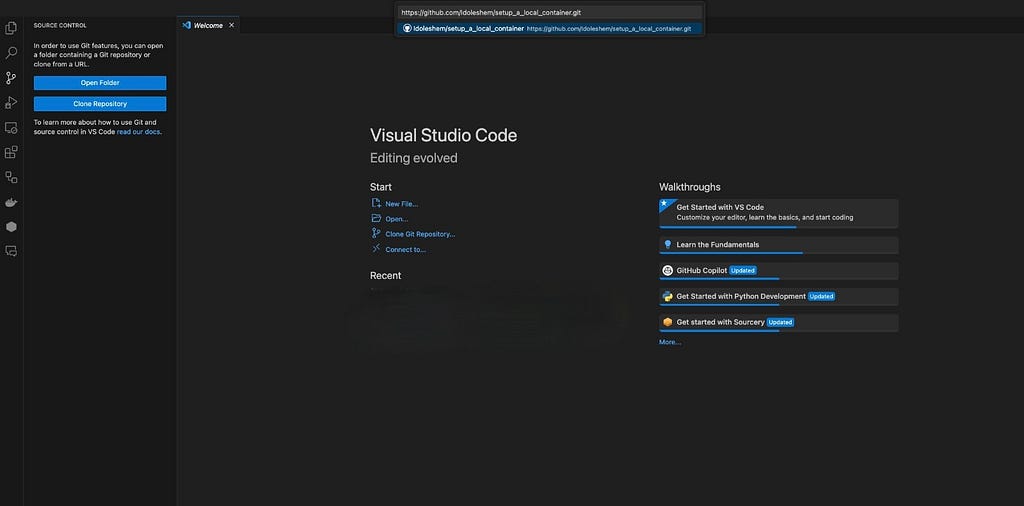
Step 2 — Create a docker image
Do this by opening the terminal and copy paste the following command:
docker build -t local_container_intro .
This might take a few moments until you see your docker image created. Click on the docker icon, the change would be reflected. Once we created the docker image we don’t need to run this command anymore. The only command we will use is docker run.
The local_container_intro is the name of the docker image, you can change it to what ever you want.
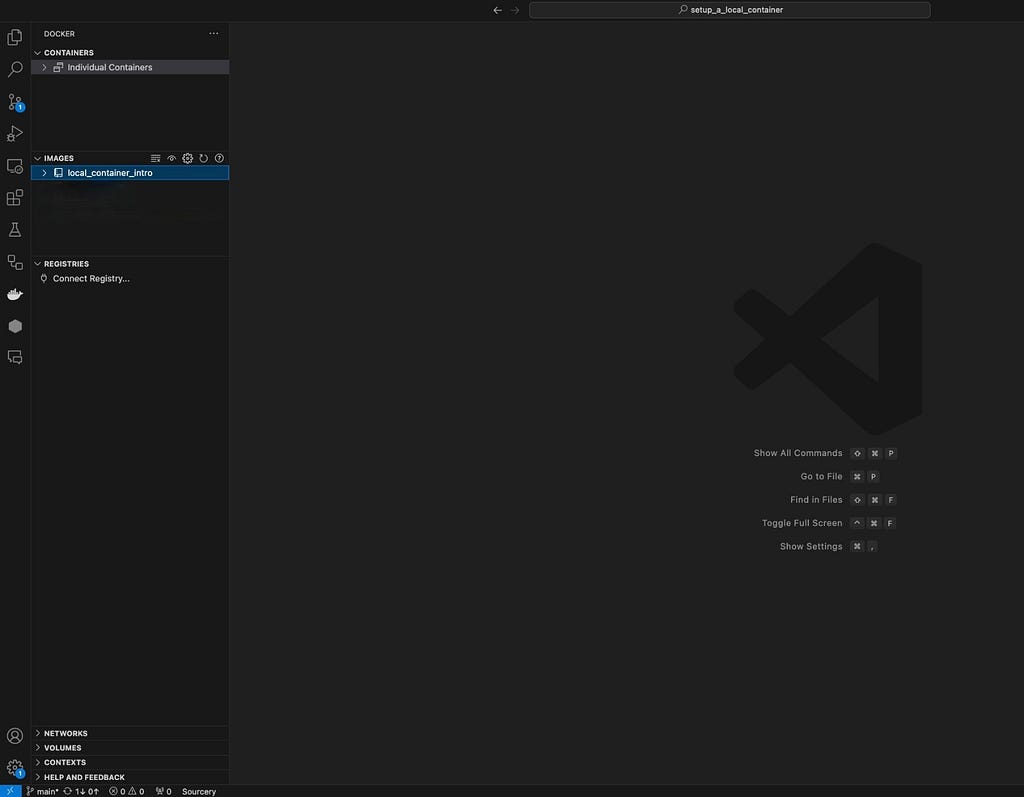
Once the docker image was created, you can see it in the IMAGES window.
Step 3 — create a docker container
To grant the container access to the repository you cloned, remember to include your project path in the docker run command. We will use the following command to create the container, giving it the name “local_container_instance”:
docker run -it --name local_container_instance -v /pate/to/your/project/folder :/project local_container_intro
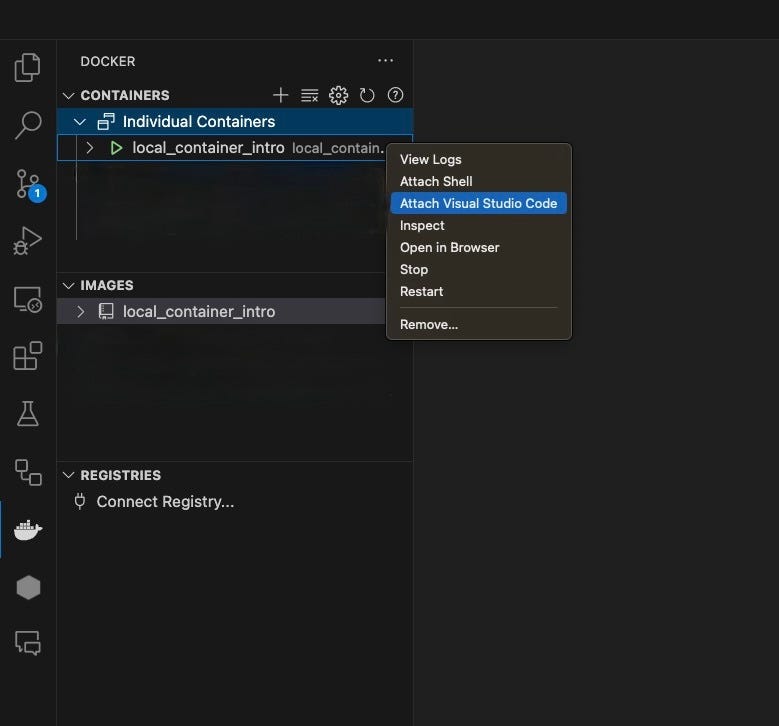
You can view the container in the CONTAINERS window after it has been created. In order to actually use it, click “attach visual studio code”. This will open a new window which reflects your containerized environment. This environment includes your code and on the bottom left you can see your container name. Open the terminal and run “pip list” and see whether all the dependencies are installed. Make sure to install any Python extensions that may be required for your container.
That’s it, all that is left to do is start developing 🙂
To recap, this blog post provided a step-by-step guide on setting up a local container. I highly recommend using containers and leverage their high flexibility and convenience in development.
Intro to Docker Containers for Data Scientists was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Intro to Docker Containers for Data Scientists
Go Here to Read this Fast! Intro to Docker Containers for Data Scientists


