
Challenging and realistic datasets for temporal graph learning
In recent years, significant advances have been made in machine learning on static graphs, accelerated by the availability of public datasets and standardized evaluation protocols, such as the widely adopted Open Graph Benchmark (OGB). However, many real-world systems such as social networks, transportation networks, and financial transaction networks evolve over time with nodes and edges constantly added or deleted. They are often modeled as temporal graphs. Until now, progress in temporal graph learning has been held back by the lack of large high-quality datasets, as well as the lack of proper evaluation thus leading to over-optimistic performance.

To address this, we present Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation for machine learning on temporal graphs. Inspired by the success of OGB, TGB automates dataset downloading and processing as well as evaluation protocols, and allows users to compare model performance using a leaderboard. We hope TGB would become a standardized benchmark for the temporal graph community and facilitate the development of novel methods and improve the understanding of large temporal networks.

- Website: https://tgb.complexdatalab.com/
- Paper: https://arxiv.org/abs/2307.01026
- Github: https://github.com/shenyangHuang/TGB
This post is based on our paper Temporal Graph Benchmark for Machine Learning on Temporal Graphs (NeurIPS 2023 Datasets and Benchmarks Track) and was co-authored with Emanuele Rossi. Find more temporal graph work from my website. Want to learn more about temporal graphs? Join the Temporal Graph Reading Group and Temporal Graph Learning Workshop @ NeurIPS 2023 to learn more about state-of-the-art TG research.
Table of Contents:
- Motivation
- Problem Setting
- Dataset Details
- Dynamic Link Property Prediction
- Dynamic Node Property Prediction
- Get Started with TGB
- Conclusion and Future Work
Motivation
In the last few years, the field of machine learning for static graphs has experienced a significant boost, largely due to the advent of public datasets and established benchmarks like the Open Graph Benchmark (OGB), the Long Range Graph Benchmark, and the TDC Benchmark. However, many real-world systems such as social networks, transportation networks, and financial transaction networks are temporal: they evolve over time. Until now, the advancement in temporal graphs has been significantly hampered by the lack of large, high-quality datasets and comprehensive evaluation frameworks. This scarcity, coupled with evaluation limitations, has resulted in almost perfect AP or AUROC scores across models on popular datasets such as Wikipedia and Reddit, leading to an over-optimistic assessment of model performance and a challenge in differentiating between competing models.
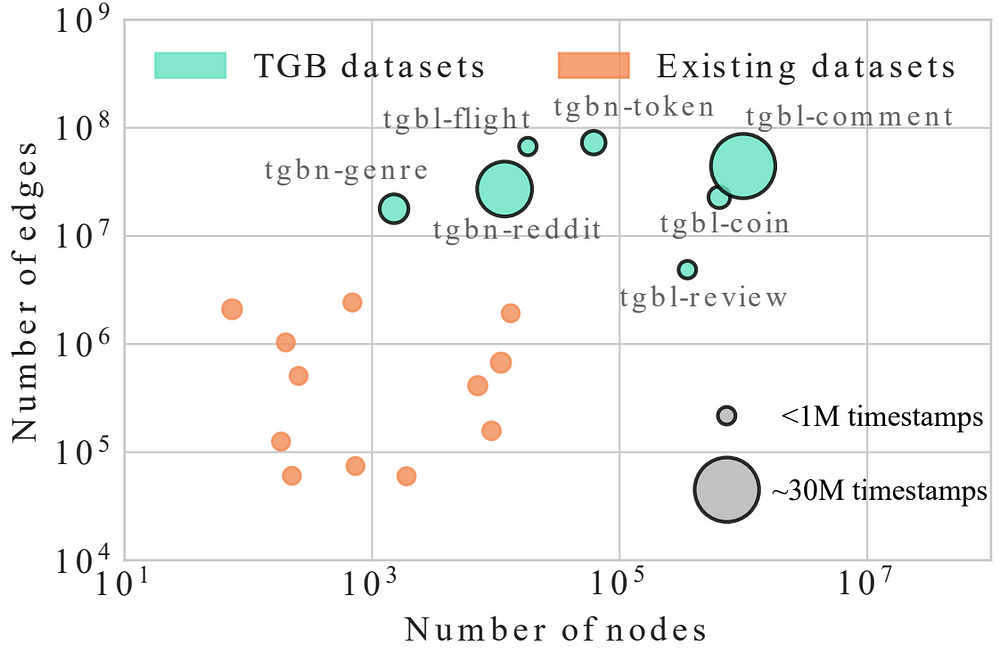
Lack of datasets. Common TG datasets only contain a few million edges, significantly smaller than the scale seen in real temporal networks. Furthermore, these datasets are mostly restricted to the domain of social and interaction networks. As network properties often vary significantly across domains, it is important to benchmark on a variety of domains as well. Lastly, there is a lack of datasets for node-level tasks, causing most of the methods to only focus on link prediction. To solve this challenge, TGB contains nine datasets from five distinct domains which are orders of magnitude larger in terms of the number of nodes, edges and timestamps. In addition, TGB proposes four datasets for the novel node affinity prediction task.
Simplistic Evaluation. Dynamic link prediction was commonly framed as a binary classification task: positive (true) edges have a label of one, while negative (non-existing) edges have a label of zero. When evaluating, one negative edge per positive one was sampled by keeping the source node fixed and choosing the destination node uniformly at random. This evaluation only considers a small amount of easy to predict negative edges, leading to inflated model performance with many models obtaining >95% AP on Wikipedia and Reddit (Poursafaei et al. 2022, Rossi et al. 2020, Wang et al. 2021, Souza et al. 2022). In TGB we treat the link prediction task as a ranking problem and make the evaluation more robust. We show that the improved evaluation results in more realistic performance and highlights clear gaps between different models.
Problem Setting
In TGB, we focus on continuous time temporal graphs, as defined by Kazemi et al. 2020. In this setting, we denote temporal graphs as timestamped edge streams consisting of triplets of (source, destination, , timestamp). Note that temporal edges can be weighted, directed, while both nodes and edges can optionally have features.
Additionally, we consider the streaming setting, where a model can incorporate new information at inference time. In particular, when predicting a test edge at time t, the model can access[1] all edges occurred before t, including test edges. However, back-propagation and weight updates with the test information are not permitted.
Dataset Details
TGB contains nine datasets, seven of which are curated for this work while two are from previous literature. The datasets are temporally split into training, validation and test sets with ratio of 70/15/15. Datasets are categorized based on their number of edges: small (<5 million), medium (5–25 million) and large (> 25 million).

TGB datasets also have distinct domains and time granularities (from UNIX timestamp to annually). Lastly, dataset statistics are highly diverse too. For example, the Surprise Index, defined by the ratio of test edges never observed in the training set, varies significantly across datasets. Many TGB datasets also contain many novel nodes in the test set which requires inductive reasoning.
TGB datasets are also tied to real world tasks. For example, tgbl-flight dataset is a crowd sourced international flight network from 2019 to 2022 where the airports are modeled as nodes while edges are flights between airports for a given day. The task is to predict whether a flight will happen between two specific airports on a future date. This is useful for forecasting potential flight disruptions such as cancellation and delays. For instance, during the COVID-19 pandemic, many flight routes were canceled to combat the spread of COVID-19. The prediction of the global flight network is also important for studying and forecasting the spread of disease such as COVID-19 to new regions as seen in Ding et al. 2021. Detailed dataset and task descriptions are provided in Section 4 of the paper.
Dynamic Link Property Prediction
The goal of dynamic link property prediction is to predict the property (often the existence) of a link between a node pair at a future timestamp.
Negative Edge Sampling. In real applications, the true edges are not known in advance. Therefore, a large number of node pairs are queried, and onlypairs with the highest scores are treated as edges. Motivated by this, we frame the link prediction task as a ranking problem and sample multiple negative edges per each positive edge. In particular, for a given positive edge (s,d,t), we fix the source node s and timestamp t and sample q different destination nodes d. For each dataset, q is selected based on the trade-off between evaluation completeness and test set inference time. Out of the q negative samples, half are sampled uniformly at random, while the other half are historic negative edges (edges that were observed in the training set but are not present at time t).
Performance metric. We use the filtered Mean Reciprocal Rank (MRR) as the metric for this task, as it is designed for ranking problems. The MRR computes the reciprocal rank of the true destination node among the negative or fake destinations and is commonly used in recommendation systems and knowledge graph literature.
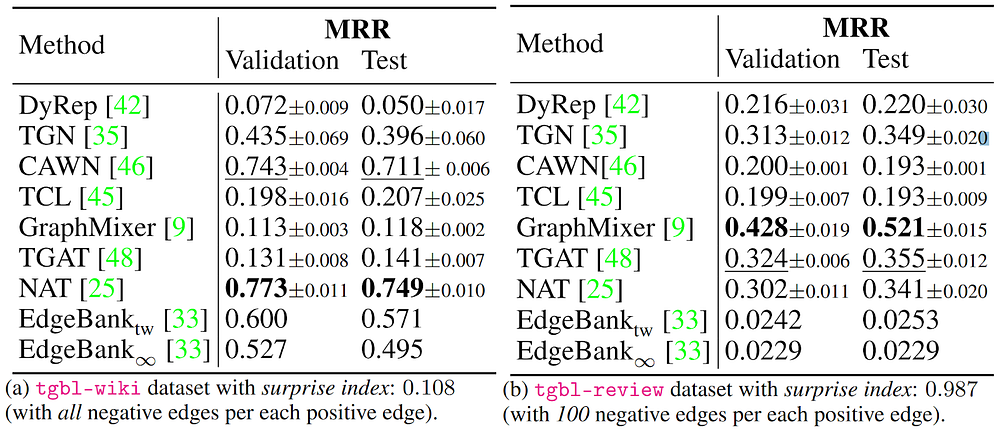
Results on small datasets. On the small tgbl-wiki and tgbl-reviewdatasets, we observe that the best performing models are quite different. In addition, the top performing models on tgbl-wiki such as CAWN and NAT have a significant reduction in performance on tgbl-review. One possible explanation is that the tgbl-reviewdataset has a much higher surprise index when compared to the tgbl-wikidataset. The high surprise index shows that a high ratio of test set edges is never observed in the training set thus tgbl-reviewrequires more inductive reasoning. In tgbl-review, GraphMixer and TGAT are the best performing models. Due to their smaller size, we are able to sample all possible negatives for tgbl-wikiand one hundred negatives for tgbl-reviewper positive edge.
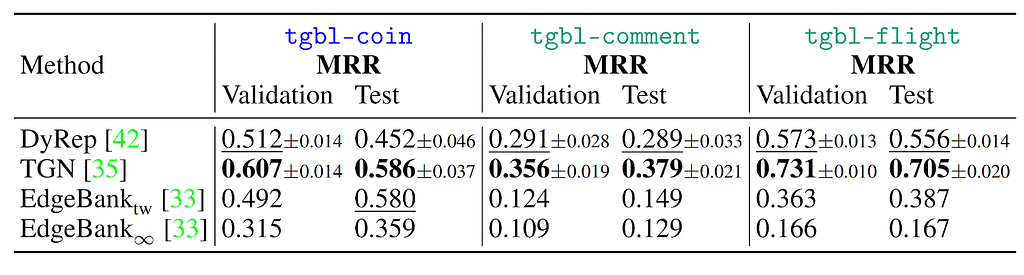
Most methods run out of GPU memory for these datasets thus we compare TGN, DyRep and Edgebank on these datasets due to their lower GPU memory requirement. Note that some datasets such as tgbl-commentor tgbl-flightspanning multiple years thus potentially resulting in distribution shift over its long time span.
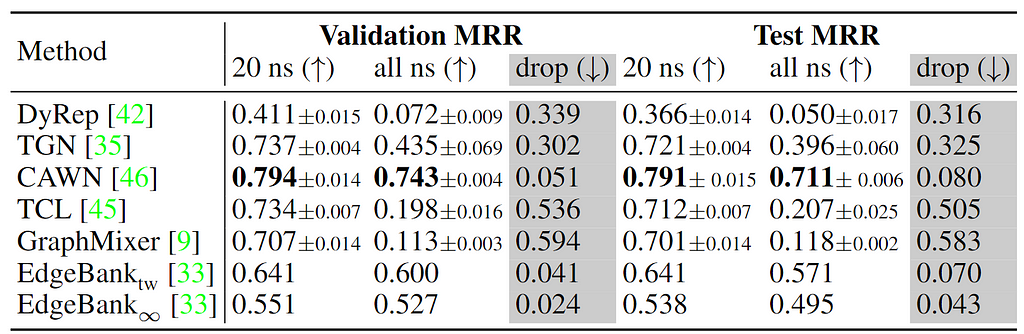
Insights. As seen above in tgbl-wiki, the number of negative samples used for evaluation can significantly impact model performance: we see a significant performance drop across most methods, when the number of negative samples increases from 20 to all possible destinations. This verifies that indeed, more negative samples are required for robust evaluation. Curiously, methods such as CAWN and Edgebank have relatively minor drop in performance and we leave it as future work to investigate why certain methods are less impacted.
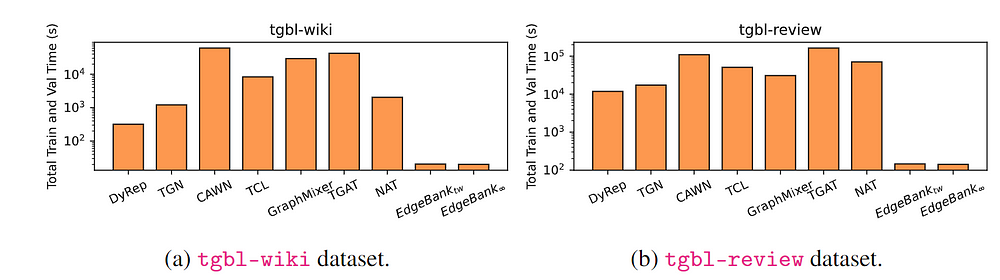
Next, we observe up to two orders of magnitude difference in training and validation time of TG methods, with the heuristic baseline Edgebank always being the fastest (as it is implemented simply as a hashtable). This shows that improving the model efficiency and scalability is an important future direction such that novel and existing models can be tested on large datasets provided in TGB.
Dynamic Node Property Prediction
The goal of dynamic node property prediction is to predict the property of a node at any given timestamp t. As there is a lack of large public TG datasets with dynamic node labels, we introduce the node affinity prediction task to investigate node level tasks on temporal graphs. If you would like to contribute a novel dataset with node labels, please reach out to us.
Node affinity prediction. This task considers the affinity of a subset of nodes (e.g., users) towards other nodes (e.g. items) as its property, and how the affinity naturally changes over time. This task is relevant for example in recommendation systems, where it is important to provide personalized recommendations for a user by modeling their preference towards different items over time. Here, we use the Normalized Discounted Cumulative Gain of the top 10 items (NDCG@10) to compare the relative order of the predicted items to that of the ground truth. The label is generated by counting the frequency of user interaction with different items over a future period.

Results. For this task, we compare TG models with two simple heuristics: persistence forecast, predicting the most recent observed node label for the current time and moving average, the average over node labels in the past few steps. The key observation here is that on this task, simple heuristics such as persistence forecast and moving average are strong contenders to TG methods and in most cases, outperforming them. This highlights the need to develop more TG methods for node-level tasks in the future.
Get Started with TGB

How to use TGB? The above shows the ML pipeline in TGB. You can automatically download datasets and processes them into numpy, PyTorchand PyGcompatible data formats. Users only need to design their own TG models which can be easily tested via TGB evaluators to standardize evaluation. Lastly, the public and online TGB leaderboards help researchers track recent progress in the temporal graph domain. You can install the package easily:
pip install py-tgb
Finally, you can submit your model performance to the TGB leaderboard. We ask that you provide link to your code and a paper describing your approach for reproducibility. To submit, please fill in the google form.
Conclusion and Future Work
To enable realistic, reproducible, and robust evaluation for machine learning on temporal graphs, we present the Temporal Graph Benchmark, a collection of challenging and diverse datasets. With TGB datasets and evaluation, we found that model performance varies significantly across datasets, thus demonstrating the necessity to evaluate on a diverse range of temporal graph domains. In addition, on the node affinity prediction task, simple heuristics outperform TG methods thus motivating the development of more node-level TG models in the future.
Integration into PyG. Matthias Fey (Kumo.AI), Core lead of PyG, announced at the Stanford Graph Learning Workshop 2023 that TGB will be integrated into future versions of PyG. Stay tuned!
TGX library. We are currently developing an utility and visualization Python library for temporal graphs, named TGX. TGX supports 20 built in temporal graph datasets from TGB and Poursafaei et al. 2022.
Community Feedback and Dataset Contributions. TGB is a community driven project and we would like to thank all the community members who provided suggestions to us via email or Github issues. If you have any suggestions or want to contribute new datasets to TGB, please reach out to us via email or create an issue on Github. We are looking for large scale datasets, especially those for dynamic node or graph classification tasks.
Temporal Graph Benchmark was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Temporal Graph Benchmark



