

Get more out of your music data
Labeled audio data is chronically scarce in Music AI. In this post, I will share some tips on building strong models under these circumstances.
Compared to other fields like Computer Vision or Natural Language Processing (NLP), finding suitable public datasets for Music AI is often difficult. Whether you want to do mood recognition, noise detection, or instrument tagging: you will likely struggle to find the right data.
However, data scarcity affects not only hobby programmers and students. Aspiring music tech startups and even established music companies have the exact same problem. In the age of AI, many are desperately trying to gather proprietary data assets for machine learning purposes.
With that said, let us dive into my top 3 tips to get more out of your music data.
Tip 1: Apply Natural Data Augmentation

If you are a data scientist, you have probably heard about data augmentation. The basic idea is to take existing examples in our dataset and alter them slightly to produce new synthetic training examples. This is best illustrated with images. For instance, if our dataset contains an image of a cat, we can easily create new synthetic cats by shifting and rotating the original cat image.

Data augmentation is particularly effective for smaller datasets. If your dataset has only 100 images of cats, the odds that all possible angles and rotations are represented properly are low. These blind spots in the dataset will automatically translate to blind spots in the AI’s perception and judgment. By synthetically creating alterations of existing images, we can mitigate this risk.
Data Augmentation is Different in Music AI
While data augmentation is a game-changer in Computer Vision, it is less straightforward in Music AI. The most common input to Music AI models is the spectrogram (learn more here). But have you tried rotating and shifting a spectrogram?
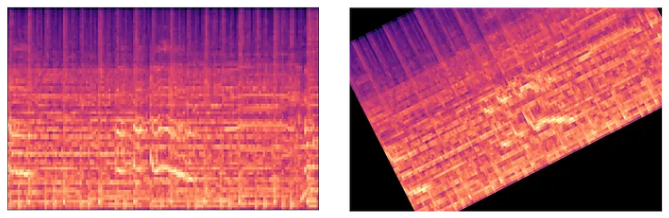
It is easy to see that the same tricks from Computer Vision cannot be applied directly to music AI. But why is this example so ridiculous? The answer is that, in contrast to the cat example, this kind of augmentation is not natural for a spectrogram.
An augmentation is natural when the changes made represent alterations that the model might encounter in real-world applications. While rotating a spectrogram certainly alters the data, visually, it is nonsensical and would never occur in practice. Instead, we need to find natural alterations specifically for music data.
Using Effects for Natural Audio Augmentation
The most common natural music data augmentation involves applying effects to the audio signal. There are a bunch of effects that every musician knows from their DAW:
- Time stretching
- Pitch shifting
- Compressors, Limiters, Distortion
- Reverb, Echo, Chorus
- and many more…
These effects can be applied to any piece of music, altering the data while preserving its main musical characteristics. If you want to know how to implement this in practice, check my article about this topic:
Natural Audio Data Augmentation Using Spotify’s Pedalboard
Data augmentation is not only used in many Music AI research papers, but I have also had great results with it myself. When data is scarce, data augmentation can push your model from unusable to acceptable. Even with higher data volumes, it adds that extra bit of reliability that can be crucial in production.
When implementing music data augmentation in practice, it is important to keep these three things in mind:
- Stay natural. Listen to your data after augmentation and make sure it still sounds natural. Otherwise, your model might learn false patterns.
- Not every training example should be augmented. To make sure that your model primarily learns from real, unaltered music, augmented examples should only be a portion of your training data (20–30%). You can also use sample weighting during training to adjust the impact of your augmented examples on the model.
- Don’t augment your validation and test data. Augmentations help the model learn generalizable patterns. Your validation and test data should be unaltered to enable accurate benchmarks on real examples.
Time to boost your model effectiveness with data augmentation!
Tip 2: Use Smaller Models and Input Data

Bigger = Better?
In AI, bigger is often better — if there is enough data to feed these large models. However, with limited data, bigger models are more prone to overfitting. Overfitting occurs when the model memorizes patterns from the training data that do not generalize well to real-world data examples. But there is another way to approach this that I find even more compelling in this context.
Suppose you have a small dataset of spectrograms and are deciding between a small CNN model (100k parameters) or a large CNN (10 million parameters). Remember that every model parameter is effectively a best-guess number derived from the training dataset. If we think of it this way, it is obvious that it is easier for a model to get 100k parameters right than it is to nail 10 million.
In the end, both arguments lead to the same conclusion:
If data is scarce, consider building smaller models that focus only on the essential patterns.
But how can we achieve smaller models in practice?
Don’t Crack Walnuts with a Sledgehammer
My learning journey in Music AI has been dominated by deep learning. Up until a year ago, I had solved almost every problem using large neural networks. While this makes sense for complex tasks like music tagging or instrument recognition, not every task is that complicated.
For instance, a decent BPM estimator or key detector can be built without any machine learning by analyzing the time between onsets or by correlating chromagrams with key profiles, respectively.
Even for tasks like music tagging, it doesn’t always have to be a deep learning model. I’ve achieved good results in mood tagging through a simple K-Nearest Neighbor classifier over an embedding space (e.g. CLAP).
While most state-of-the-art methods in Music AI are based on deep learning, alternative solutions should be considered under data scarcity.
Pay Attention to the Data Input Size
More important than the choice of models is usually the choice of input data. In Music AI, we rarely use raw waveforms as input due to their data inefficiency. By transforming waveforms into (mel)spectrograms, we can decrease the input data dimensionality by a factor of 100 or more. This matters because large data inputs typically require larger and/or more complex models to process them.
To minimize the size of the model input, we can take two routes
- Using smaller music snippets
- Using more compressed/simplified music representations.
Using Smaller Music Snippets
Using smaller music snippets is especially effective if the outcome we are interested in is global, i.e. applies to every section of the song. For example, we can assume that the genre of a track remains relatively stable over the course of the track. Because of that, we can easily use 10-second snippets instead of full tracks (or the very common 30-second snippets) for a genre classification task.
This has two advantages:
- Shorter snippets result in fewer data points per training example, allowing you to use smaller models.
- By drawing three 10-second snippets instead of one 30-second snippet, we can triple the number of training observations. All in all, this means that we can build less data-hungry models and, at the same time, feed them more training examples than before.
However, there are two potential dangers here. Firstly, the snippet size must be long enough so that a classification is possible. For example, even humans struggle with genre classification when presented with 3-second snippets. We should choose the snippet size carefully and view this decision as a hyperparameter of our AI solution.
Secondly, not every musical attribute is global. For example, if a song features vocals, this doesn’t mean that there are no instrumental sections. If we cut the track into really short snippets, we would introduce many falsely-labelled examples into our training dataset.
Using More Efficient Music Representations
If you studied Music AI ten years ago (back when all of this was called “Music Information Retrieval”), you learned about chromagrams, MFCCs, and beat histograms. These handcrafted features were designed to make music data work with traditional ML approaches. With the rise of deep learning, it might seem like these features have been entirely replaced by (mel)spectrograms.
Spectrograms compress music into images without much information loss, making them ideal in combination with computer vision models. Instead of engineering custom features for different tasks, we can now use the same input data representation and model for most Music AI problems — provided you have tens of thousands of training examples to feed these models with.
When data is scarce, we want to compress the information as much as possible to make it easier for the model to extract relevant patterns from the data. Consider these four music representations below and tell me which one helps you identify the musical key the fastest.
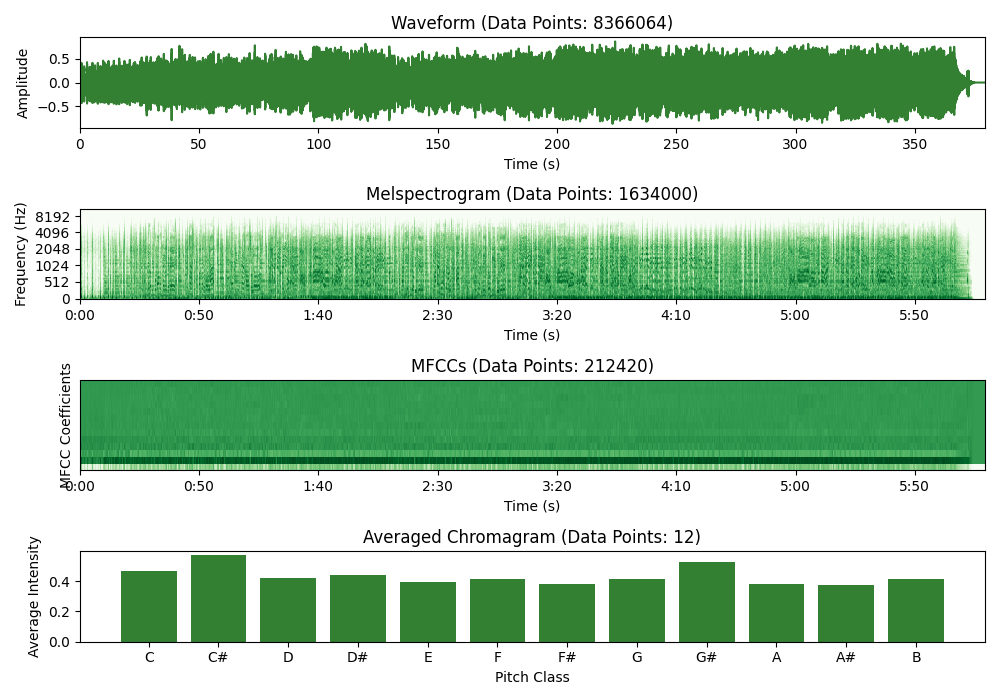
While mel spectrograms can be used as an input for key detection systems (and possibly should be if you have enough data), a simple chromagram averaged along the time dimension reveals this specific information much quicker. That is why spectrograms require complex models like CNNs while a chromagram can be easily analyzed by traditional models like logistic regression or decision trees.
In summary, the established spectrogram + CNN combination remains highly effective for many problems, provided you have enough data. However, with smaller datasets, it might make sense to revisit some feature engineering techniques from MIR or develop your own task-specific representations.
Tip 3: Leverage Pretrained Models or Embeddings

When data is scarce, one of the most effective strategies is to leverage pretrained models or embeddings. This approach allows you to build upon existing knowledge from models that have been trained on large datasets, thereby mitigating the limitations of your smaller dataset.
Why Use Pretrained Models?
Pretrained models have already learned to identify and extract meaningful features from their training data. For instance, a model trained on genre classification has likely learned a variety of meaningful musical patterns during training. If we now want to build our own mood tagging model, it might make sense to use the pretrained genre model as a starting point.
If the pretrained model was trained on a similar task, you can transfer their learned representations to your specific task. This process is known as transfer learning. Transfer learning can drastically reduce the amount of data and computational resources needed to train your own model from scratch.
Popular Pretrained Models in Music AI
A few years ago, the most common approach was to take pretrained models like genre classifiers and finetune them on specific tasks. Models like MusiCNN were commonly used for this.
However, nowadays, it is more common to use pretrained models that were specifically trained to yield meaningful music embeddings, i.e. vector representations of songs. Here are three pretrained embedding models that are commonly used:
From my personal experience, I’ve had the best results using Microsoft’s CLAP for transfer learning and LAION CLAP for similarity search.
Different Ways to Leverage Pretrained Models
Pretrained models can be used in a variety of ways:
- Full Fine-Tuning: Use a pretrained classification or embedding model and fine-tune it on a smaller dataset of task-specific data. This method often achieves optimal results, if you can afford to use the full, large model for training and inference and know how to implement it.
- Embeddings as Input Features: A more resource-efficient approach can be to extract embeddings from a pretrained model to use them as inputs for a new, much smaller model. As these embeddings are often 500–1000 dimensional vectors, a smaller neural network with a few thousand parameters can be attached to fine-tune more efficiently. For smaller datasets, this method is usually preferred over a full tine-tune.
- Using Embeddings Directly: Even without any fine-tuning, embeddings can be used directly. For instance, embeddings from pretrained models are commonly used for music similarity search. CLAP models can even be used for text-to-music retrieval or (although still rather poorly) for zero-shot classification, i.e. classification without training.
Leveraging embeddings from pretrained models can significantly enhance your Music AI projects. By building on the learned pattern-recognition of these models, you avoid reinventing the wheel. When data is scarce, pretrained models should always be considered.
Conclusion
Don’t let data scarcity hold you back! Many use cases that required hundreds of thousands of training examples a few years ago have now essentially become commodities.
To achieve robust performance with small datasets, your number one priority should be not to waste any of your valuable data. Let’s review the main points from this article:
- Data augmentation is a great way to let your models learn from training examples several times with small but effective variations, increasing robustness.
- Smaller models and more efficient data representations force your model to focus on the most important, underlying patterns in the data, avoiding overfitting.
- Pretrained models allow you to borrow some of the intelligence from larger AI systems through fine-tuning. No reason to train from scratch anymore!
Of course, there are natural limitations to what you can achieve with small datasets. If you have 100 labeled tracks and your goal is to build a multi-label genre classifier with 10 genres and 30 subgenres, you will not get very far — even if you use all of my tricks.
Still, I’ve developed surprisingly capable genre & mood classifiers with as little as 1000 labeled songs. Only 2 years ago, achieving this with such a small dataset would have been impossible. These democratization effects are one of the most exciting aspects of the current AI hype, in my opinion.
If you have a small but high-quality music dataset and are considering using it for machine learning, now is the best time to give it a try!
Interested in Music AI?
If you liked this article, you might want to check out some of my other work:
- “3 Music AI Breakthroughs to Expect in 2024”. Medium Blog
- “The Human Element in a World of Generative AI Music”. Video interview on the Audiosocket podcast
- “How Google Used Your Data to Improve their Music AI”. Medium Blog
You can also follow me on Linkedin to stay updated about new papers and trends in Music AI.
Thanks for reading this article!
3 Practical Tips to Combat Data Scarcity in Music AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
3 Practical Tips to Combat Data Scarcity in Music AI
Go Here to Read this Fast! 3 Practical Tips to Combat Data Scarcity in Music AI