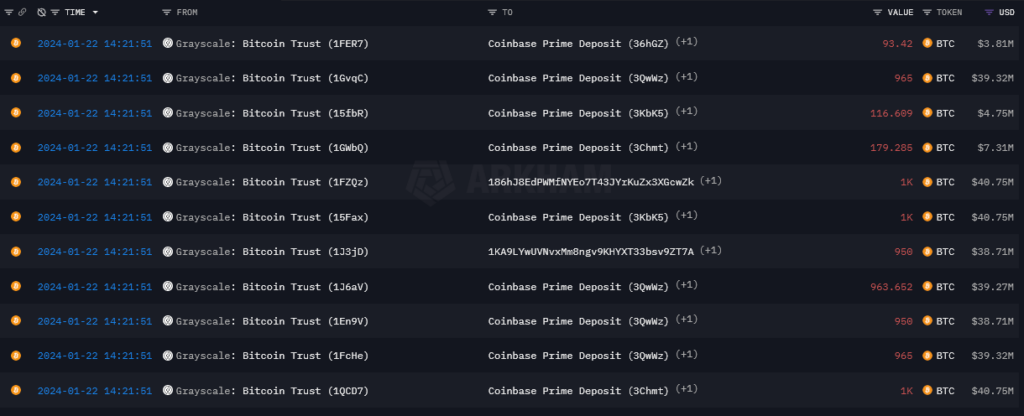
Data from Arkham Intelligence shows Grayscale has continued its daily Bitcoin outflows, which have occurred daily shortly before the U.S. market opened each day since its conversion to a spot Bitcoin ETF. With famously high fees, the trust continues to see investors leave the fund seeking lower fees or to lock in profits. The trust […]
The Ethereum Foundation, a non-profit organization dedicated to the blockchain network’s ecosystem, liquidated $1.6 million worth of ETH, according to crypto analytical firm Arkham Intelligence. Data from the platform reveals that the foundation utilized the CoW Protocol to sell 700 ETH, acquiring $1.6 million in DAI stablecoin. Subsequently, the funds were transferred to an address […]
Often for many domain-specific problems, a lack of data can hinder the effectiveness and even disallow the use of deep neural networks. Recent architectures of Generative Adversarial Networks (GANs), however, allow us to synthetically augment data, by creating new samples that capture intricate details, textures, and variations in the data distribution. This synthetic data can act as additional training input for deep neural networks, thus making domain tasks with limited data more feasible.
StyleGAN-2 with ADA was first introduced by NVIDIA in the NeurIPS 2020 paper: “Training Generative Adversarial Networks with Limited Data” [2]. In the past, training GANs on small datasets typically led to the network discriminator overfitting. Thus rather than learning to distinguish between real and generated data, the discriminator tended to memorize the patterns of noise and outliers of the training set, rather than learn the general trends of the data distribution. To combat this, ADA dynamically adjusts the strength of data augmentation based on the degree of overfitting observed during training. This helps the model to generalize better and leads to better GAN performance on smaller datasets.
Augmenting The Dataset
To use the StyleGAN-2 ADA model, we used the official NVIDIA model implementation from GitHub, which can be found here. Note that this is the StyleGAN-3 repo but StyleGAN-2 can still be run.
!git clone https://github.com/NVlabs/stylegan3
Depending on your setup you may have to install dependencies and do some other preprocessing. For example, we chose to resize and shrink our dataset images to 224×224 since we only had access to a single GPU, and using larger image sizes is much more computationally expensive. We chose to use 224×224 because ResNet, the pre-trained model we chose for the CNN, is optimized to work with this size of image.
!pip install pillow from PIL import Image import os
'''Loops through the files in an input folder (input_folder), resizes them to a specified new size (new_size), an adds them to an output folder (output_folder).''' def resize_images_in_folder(input_folder, output_folder, new_size): # Loop through all files in the input folder for filename in os.listdir(input_folder): input_path = os.path.join(input_folder, filename)
# Check if the file is an image if os.path.isfile(input_path) and filename.lower().endswith(('.png', '.jpg', '.jpeg', '.gif')): # Open the image file image = Image.open(input_path)
#Convert to RGB image = image.convert('RGB')
# Resize the image resized_image = image.resize(new_size)
# Generate the output file path output_path = os.path.join(output_folder, filename)
# Save the resized image to the output folder resized_image.save(output_path)
print(f"Resized {filename} and saved to {output_path}")
To begin the training process, navigate to the directory where you cloned the repo and then run the following.
import os
!python dataset_tool.py --source= "Raw Data Directory" --dest="Output Directory" --resolution='256x256'
# Training EXPERIMENTS = "Output directory where the Network Pickle File will be saved"" DATA = "Your Training DataSet Directory" SNAP = 10 KIMG = 80
# Build the command and run it cmd = f"/usr/bin/python3 /content/stylegan3/train.py --snap {SNAP} --outdir {EXPERIMENTS} --data {DATA} --kimg {KIMG} --cfg stylegan2 --gpus 1 --batch 8 --gamma 50" !{cmd}
SNAP refers to the number of Ticks (training steps where information is displayed) after which you would like to take a snapshot of your network and save it to a pickle file.
KIMG refers to the number of thousands of images you want to feed into your GAN.
GAMMA determines how strongly the regularization affects the discriminator.
Initial Generated ImagesGenerated Images During Training
Once your model has finished training (this can take multiple hours depending on your compute resources) you can now use your trained network to generate images.
pickle_file = "Network_Snapshot.pkl" model_path = f'Path to Pickle File/{pickle_file}' SAMPLES = Number of samples you want to generate !python /content/stylegan3/gen_images.py --outdir=Output Directory --trunc=1 --seeds {SAMPLES} --network=$model_path
Normal Real Image (Left) vs Normal Generated Image (Right)
Transfer Learning & Convolutional Neural Network
To benchmark the effectiveness of our synthetically generated data, we first trained a CNN model on our original data. Once we had a benchmark accuracy on the test set, we re-trained the model with increasing amounts of synthetic data in the training mix.
To feed our data into the model we used Keras data generators which flow the samples directly from a specified directory into the model. The original dataset has 4 classes for different types of cancer, however, for simplicity, we turned this into a binary classification problem. The two classes we decided to work with from the original Kaggle dataset were the normal and squamous classes.
# Define directories for training, validation, and test datasets train_dir = 'Your training data directory' test_dir = 'Your testing data directory' val_dir = 'Your validation data directory'
# Utilize data genarators to flow directly from directories train_generator = train_datagen.flow_from_directory( train_dir, target_size=(224, 224), batch_size=20, class_mode='binary', #Use 'categorical' for multi-class classification shuffle=True, seed=42 )
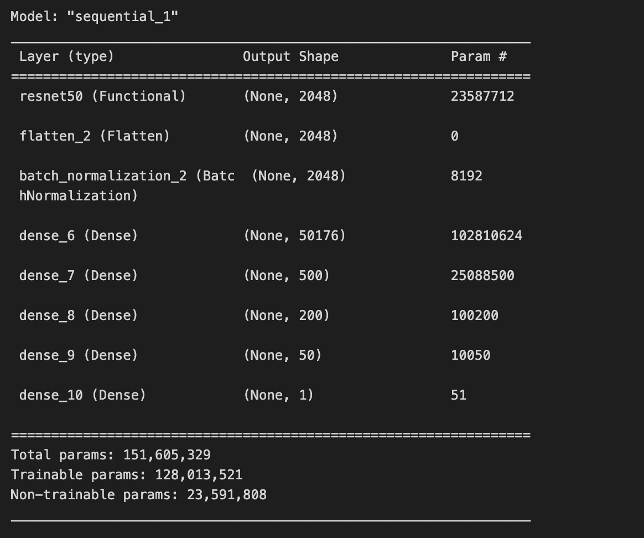
To build our model, we began by using the ResNet50 base architecture and model weights. We chose to use ResNet50 due to its moderate-size architecture, good documentation, and ease of use through Keras. After importing ResNet50 with the Imagenet model weights, we then froze the ResNet50 layers and added trainable dense layers on top to help the network learn our specific classification task.
We also chose to incorporate batch normalization, which can lead to faster convergence and more stable training by normalizing layer inputs and reducing internal covariate shift [3]. Additionally, it can provide a regularization effect that can help prevent overfitting in our added trainable dense layers.
Our Model Architecture
Originally, our model was not performing well. We solved this issue by switching our activation function from ReLU to leaky ReLU. This suggested that our network may have been facing the dying ReLU or dead neuron problem. In short, since the gradient of ReLU will always be zero for negative numbers, this can lead to neurons “dying” and not contributing to the network [4][5]. Since leaky ReLU is nonzero for negative values, using it as an activation function can help combat this issue.
Results
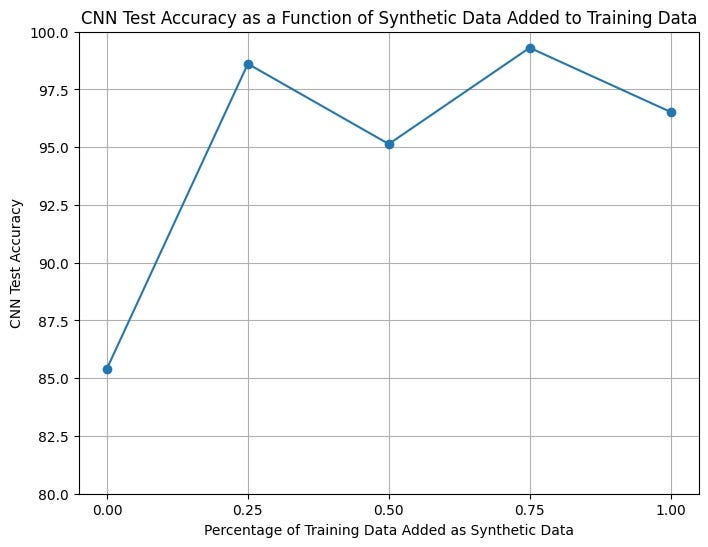
To test our synthetic data, we trained the above CNN on 5 separate instances with 0%, 25%, 50%, 75%, and 100% additional synthetic samples. For example, 0% synthetic samples meant that the data was all original, while 100% meant the training set contained equal amounts of original and synthetic data. For each network, we then evaluated the performance using an accuracy metric on a real set of unseen test data. The plot below visualizes how different proportions of synthetic data affect the testing accuracy.
Test Accuracy on Binary (Normal vs Squamous Tumor) Classification
Training the model was unstable, thus we ruled out iterations where the accuracy was 1.0 or extremely low. This helped us avoid training iterations that were under or over fit.
We can see that from 0 to 25% we see a sharp increase in the testing accuracy, suggesting that even augmenting the dataset by a small amount can have a large impact on problems where the data is initially minimal.
Since we only trained our GAN on 80 KIMG (due to compute limitations) the quality of our synthetic data could have potentially been better, given more GAN training iterations. Notably, an increase in synthetic data quality could also influence the graph above. We hypothesize that an increase in synthetic quality will also lead to an increase in the optimal proportion of synthetic data used in training. Further, if the synthetic images were better able to fit the real distribution of our training data, we could incorporate more of them in model training without overfitting.
Conclusion
In this project, using GANs for the augmentation of limited data has shown to be an effective technique for expanding training sets and more importantly, improving classification accuracy. While we opted for a small and basic problem, this could easily be upscaled in a few ways. Future work may include using more computational resources to get better synthetic samples, introducing more classes into the classification task (making it a multi-class problem), and experimenting with newer GAN architectures. Regardless, using GANs to augment small datasets can now bring many previously data-limited problems into the scope of deep neural networks.
Kaggle Dataset
We compiled our augmented and resized images into the following Kaggle dataset. This contains 501 normal and 501 squamous 224×224 synthetic images which can be used for further experimentation.
A European probe has found massive ice deposits beneath the equator of Mars, a finding that could alter our fundamental understanding of the red planet’s climatic history. The discovery was made by the European Space Agency’s Mars Express orbiter. This veteran spacecraft has circled the red planet for 20 years, revealing several secrets about its past and present climate. While it’s not the first time the probe has found ice deposits, this is by far the largest amount of water ice ever detected at the equator of Mars. It’s estimated that the deposits are around 3.7km thick, which means that…
Today’s hottest deals include 35% off an Alpine Loop 49mm Apple Watch band, $180 off a Pioneer 65″ 4K TV, 62% off a Klipsch Reference Premiere home theater pack, an Anker portable power bank power station for $110, and more.
Save $140 on an Apple Magic Keyboard for iPad Pro
The AppleInsider team searches the web for unbeatable deals at online retailers to develop a list of fantastic discounts on trending tech gadgets, including deals on Apple products, TVs, accessories, and other items. We share our top finds daily to help you upgrade your tech without breaking the bank.
Samsung has made it clear that they are shipping a smart ring in the near future. Apple has been considering the concept for almost a decade, and here’s how we know, and a glimpse of what they may have planned.
An Oura smart ring
During Samsung’s Unpacked event for 2024, which saw the launch of new Galaxy S24 smartphones, the South Korean electronics giant also teased an entry into a relatively small market. Going beyond smartwatches, Samsung declared it was working on a smart ring, the Galaxy Ring, that could be released later in 2024.
Smart rings have been around for a while, with the most well-known model being the Oura Ring. The wearable, which appears like discrete jewelry, is lined with sensors in a similar manner to a smartwatch, with it tracking data points for heart rate, blood oxygen level, movement, and nightly body temperature.
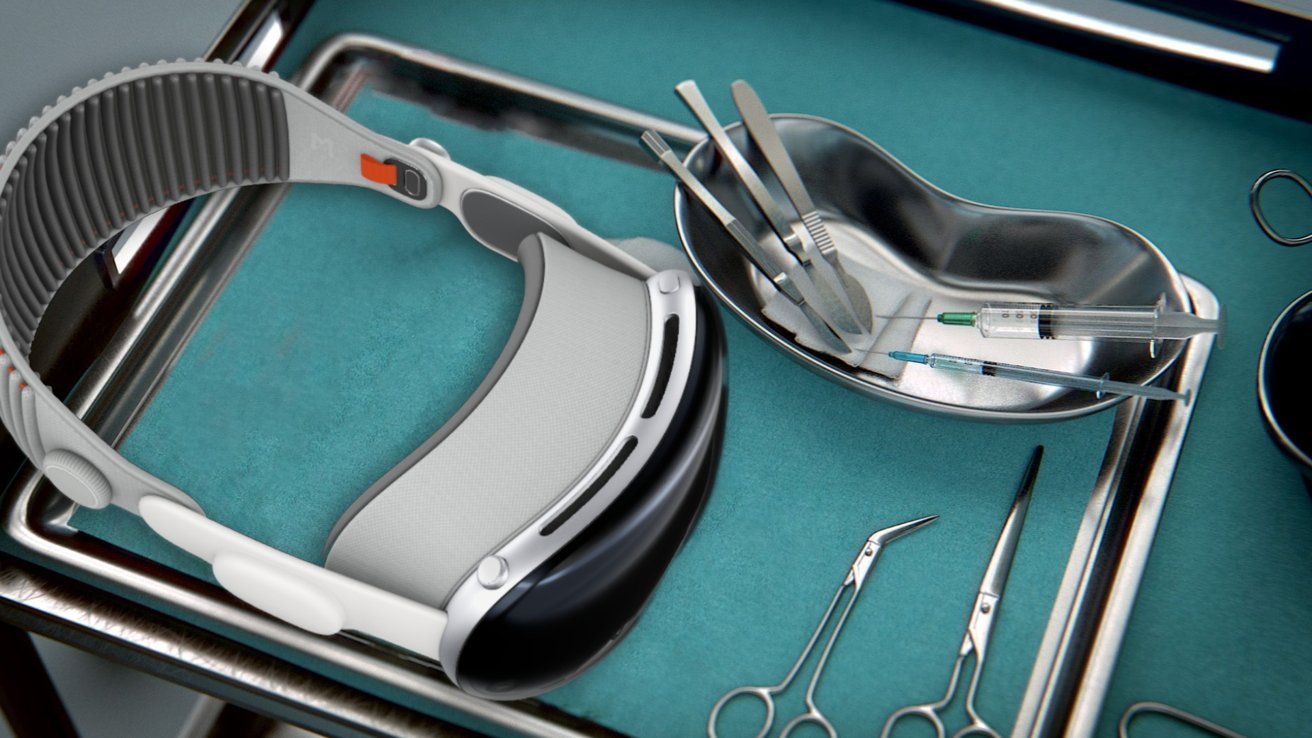
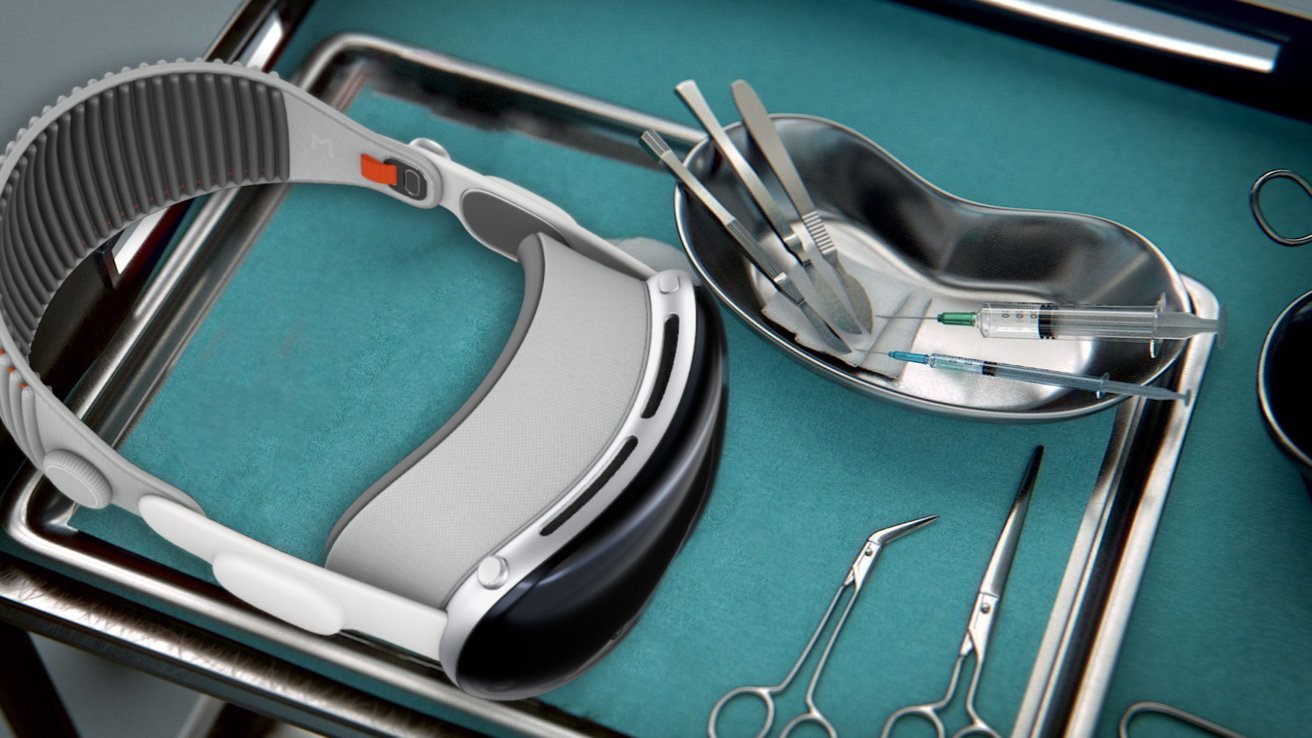
A surgeon who used Google Glass in the operating room is excited by the launch of the Apple Vision Pro, with the mixed-reality headset potentially a great tool for documentation during surgeries.
Apple Vision Pro may make its way to the operating room
The Apple Vision Pro is shipping on February 2, and potential users are awaiting the opportunity to try out the mixed-reality headset for themselves. In one case, it could end up helping to save lives.
In a Sunday post to X, Dr Rafael Grossmann discussed the possibility of using the Apple Vision Pro in healthcare. Grossmann is known as the first surgeon to introduce Google Glass to the operating room in 2013, with a deep interest in the use of new technologies in medical fields, including working as a robotic surgeon.
On this episode, Johnathan Hui and Sujata Neidig join the HomeKit Insider podcast from the Thread Group to break down the latest news and talk about changes to Thread networking.
HomeKit Insider Podcast
Despite the avalanche stemming from CES, there was still Apple Home news to share on this week’s podcast, including more product announcements.
During the electronics show, we saw a new Find My-enabled travel safe. French company UpFiner is launching a new handheld case to store small items in while you travel that syncs with the Find My app and has an alarm when moved.
Thread Group stops by, where are HomeKit routers & more CES news on HomeKit Insider
Originally appeared here:
Thread Group stops by, where are HomeKit routers & more CES news on HomeKit Insider
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.