Solana-based memecoin launchpad Pump.Fun experienced a sharp 33% decline in revenue this week after disabling its live-streaming feature. According to DefiLlama data, the platform’s revenue fell from $5 million to $3.6 million in just one day, marking its most significant single-day drop since March. The decision came after a series of controversial incidents that triggered […]
The Central Bank of Brazil (BCB) has unveiled a regulatory proposal prohibiting centralized exchanges from allowing users to withdraw stablecoins to self-custodial wallets. According to the public consultation notice, the transfer of stablecoins — called “tokens denominated in foreign currencies” — between residents would be restricted in cases where Brazilian law already allows payments in […]
PEPE coin has reached a significant milestone in this bull cycle, posting a new ATH of $0.00002524.
However, an ongoing market shift could threaten its momentum, limiting further gains.
AMP to continue its ascent if it cements its status above the $0.009176 level.
Despite AMP’s active addresses hitting new highs since May, 72% of the holders still in loss.
BTC’s rally comes as its exchange reserve continues to decline.
Sentiment suggests BTC might drop further until it finds a critical point for a rebound.
Lost in a maze of datasets and endless data dictionaries? Say goodbye to tedious variable hunting! Discover how to quickly identify and extract the variables you need from multiple SAS files using two simple R functions. Streamline your workflow, save time, and make data preparation a breeze!
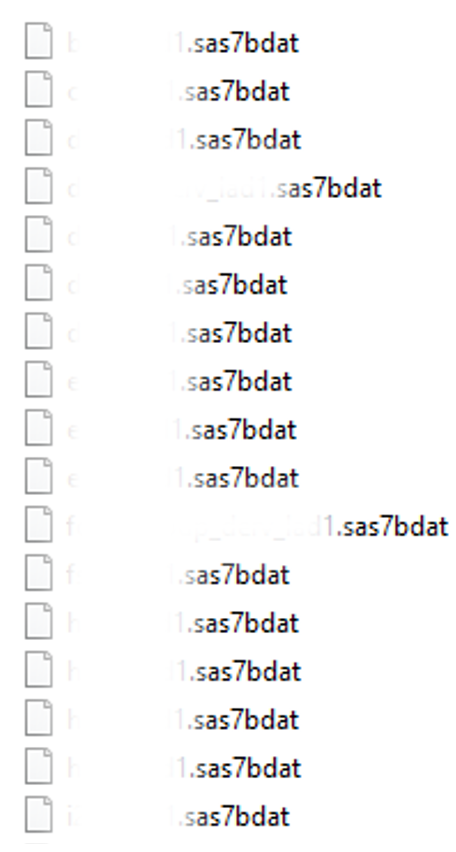
As a researcher with over seven years of experience working with health data, I’ve often been handed folders full of datasets. For example, imagine opening a folder containing 56 SAS files, each with unique data (example below). If you’ve been in this situation, you know the frustration: trying to locate a specific variable in a sea of files feels like looking for a needle in a haystack.
Screenshot taken by the author of a local folder. File names have been blurred to maintain the confidentiality of the datasets.
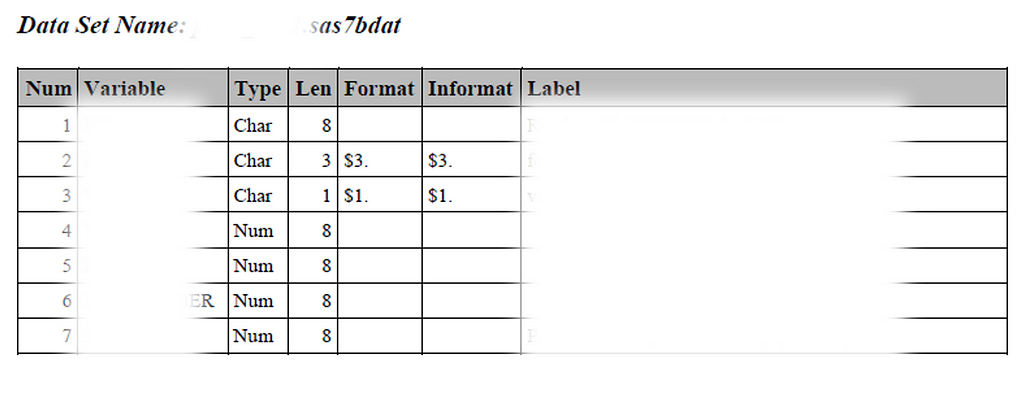
At first glance, this may not seem like an issue if you already know where your variables of interest are. But often, you don’t. While a data dictionary is usually provided, it’s frequently a PDF document that lists variables across multiple pages. Finding what you need might involve searching (Ctrl+F) for a variable on page 100, only to realize the dataset’s name is listed on page 10. Scrolling back and forth wastes time.
Screenshot taken by the author of a data dictionary. Variable names and labels have been blurred to maintain the confidentiality of the datasets.
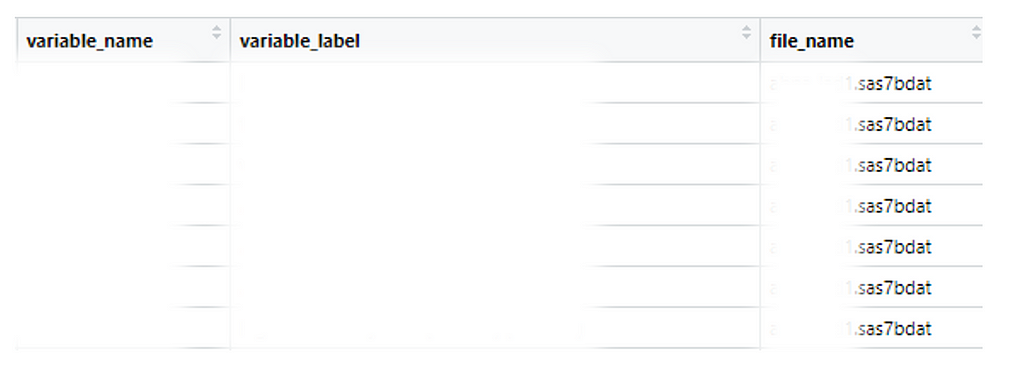
To save myself from this tedious process, I created a reproducible R workflow to read all datasets in a folder, generate a consolidated dataframe of variable names and their labels (example below), and identify where each variable is located. This approach has made my work faster and more efficient. Here’s how you can do it, step by step.
Screenshot taken by the author of of how the names_labels dataset looks like (see step 2). Variable names and labels have been blurred to maintain the confidentiality of the datasets.
Step-by-Step Guide
Step 1: Use the get_names_labels Function
First, use the custom function get_names_labels (code provided at the end of this post). This function requires the folder path where all your datasets are stored.
The get_names_labels function will create a dataframe named names_labels (like the example above), which includes:
· Variable name (variable_name)
· Variable label (variable_label)
· The name of the dataset(s) where the variable was found (file_name)
Depending on the number and size of the datasets, this process may take a minute or two.
Step 3: Search for Variables
Once the names_labels dataframe is generated, you can search for the variables you need. Filter the variable_name or variable_label columns to locate relevant terms. For example, if you’re looking for gender-related variables, they might be labeled as sex, gender, is_male, or is_female.
Be mindful that similar variables might exist in multiple datasets. For instance, age could appear in the main questionnaire, a clinical dataset, and a laboratory dataset. These variables might look identical but differ based on how and where the data was collected. For example:
· Age in the main questionnaire: Collected from all survey participants.
· Age in clinical/lab datasets: Limited to a subset invited for further assessments or those who agreed to participate.
In such cases, the variable from the main questionnaire might be more representative of the full population.
Step 4: Identify Relevant Datasets
Once you’ve determined which variables you need, filter the names_labels dataframe to identify the original datasets (file_name) containing them. If a variable appears in multiple datasets (e.g., ID), you’ll need to identify which dataset includes all the variables you’re interested in.
# Say you want these two variables variables_needed <- c('ID', 'VAR1_A') names_labels <- names_labels[which(names_labels$variable_name %in% variables_needed), ]
If one of the variables can be found in multiple original datasets (e.g., ID), you will filter names_labels to keep only the original dataset with both variables (e.g., ID and VAR1_A). In our case, the names_labels dataframe will be reduced to only two rows, one for each of the two variables we were looking for, both of which will be found in the same original dataset.
Now, use the read_and_select function (provided at the end). Pass the name of the original dataset containing the variables of interest. This function creates a new dataframe in your R environment with only the selected variables. For example, if your variables are in ABC.sas7bdat, the function will create a new dataframe called ABC with just those variables.
unique(names_labels$file_name) # Sanity check, that there is only one dataframe read_and_select(unique(names_labels$file_name)[1])
Step 6: Clean Your Environment
To keep your workspace tidy, remove unnecessary elements and retain only the new dataframe(s) you need. For example, if your variables of interest came from ABC.sas7bdat, you’ll keep the filtered dataframe ABC which was the output of the read_and_select function.
If your variables of interest are in more than one dataset (e.g., ABC and DEF), you can merge them. Use a unique identifier, such as ID, to combine the datasets into a single dataframe. The result will be a unified dataframe with all the variables you need. You will get a df dataframe with all the observations and only the variables you needed.
# Get a list with the names of the dataframes in the environment (“ABC” and “DEF”) object_names <- ls()
# Get a list with the actual dataframe object_list <- mget(object_names)
# Reduce the dataframes in the list (“ABC” and “DEF”) by merging conditional on the unique identifier (“ID”) df <- Reduce(function(x, y) merge(x, y, by = "ID", all = TRUE), object_list)
# Clean your environment to keep only the dataframes (“ABC” and “DEF”) and a new dataframe “df” which will contain all the variables you needed. rm(object_list, object_names)
Why This Workflow Works?
This approach saves time and organizes your work into a single, reproducible script. If you later decide to add more variables, simply revisit steps 2 and 3, update your list, and rerun the script. This flexibility is invaluable when dealing with large datasets. While you’ll still need to consult documentation to understand variable definitions and data collection methods, this workflow reduces the effort required to locate and prepare your data. Handling multiple datasets doesn’t have to be overwhelming. By leveraging my custom functions like get_names_labels and read_and_select, you can streamline your workflow for data preparation.
Have you faced similar challenges when working with multiple datasets? Share your thoughts or tips in the comments, or give this article a thumbs up if you found it helpful. Let’s keep the conversation going and learn from each other!
Below are the two custom functions. Save them in an R script file, and load the script into your working environment whenever needed. For example, you could save the file as _Functions.R for easy access.
# You can load the functions as source('D:/Folder1/Folder2/Folder3/_Functions.R')
## STEPS TO USE THESE FUNCTIONS: ## 1. DEFINE THE OBJECT 'PATH_FILE', WHICH IS A PATH TO THE DIRECTORY WHERE ## ALL THE DATASETS ARE STORED. ## 2. APPLY THE FUNCTION 'get_names_labels' WITH THE PATH. THE FUNCTION WILL ## RETURN A DATAFRAME NAMES 'names_labels'. ## 3. THE FUNCTION WILL RETURN A DATASET ('names_labels) SHOWING THE NAMES OF ## THE VARIABLES, THE LABELS, AND THE DATASET. VISUALLY/MANUALLY EXPLORE THE ## DATASET TO SELECT THE VARIABLES WE NEED. CREATE A VECTOR WITH THE NAMES ## OF THE VARIABLES WE NEED, AND NAME THIS VECTOR 'variables_needed'. ## 4. FROM THE DATASET 'names_labels', KEEP ONLY THE ROWS WITH THE VARIABLES WE ## WILL USE (STORED IN THE VECTOR 'variables_needed'). ## 5. APPLY THE FUNCTION 'read_and_select' TO EACH OF THE DATASETS WITH RELEVANT ## VARIABLES. THIS FUNCTION WILL ONLY NEED THE NAME OF THE DATASET, WHICH IS ## STORED IN THE LAST COLUMN OF DATASET 'names_labels'.
### FUNCTION TO 1) READ ALL DATASETS IN A FOLDER; 2) EXTRACT NAMES AND LABELS; ### 3) PUT NAMES AND LABELS IN A DATASET; AND 4) RETURN THE DATASET. THE ONLY ### INPUT NEEDED IS A PATH TO A DIRECTORY WHERE ALL THE DATASETS ARE STORED.
### FUNCTION TO READ EACH DATASET AND KEEP ONLY THE VARIABLES WE SELECTED; THE ### FUNCTION WILL SAVE EACH DATASET IN THE ENVIRONMENT. THE ONLY INPUNT IS THE ### NAME OF THE DATASET.
Background licensed from elements.envato.com, edit by Marcel Müller 2024
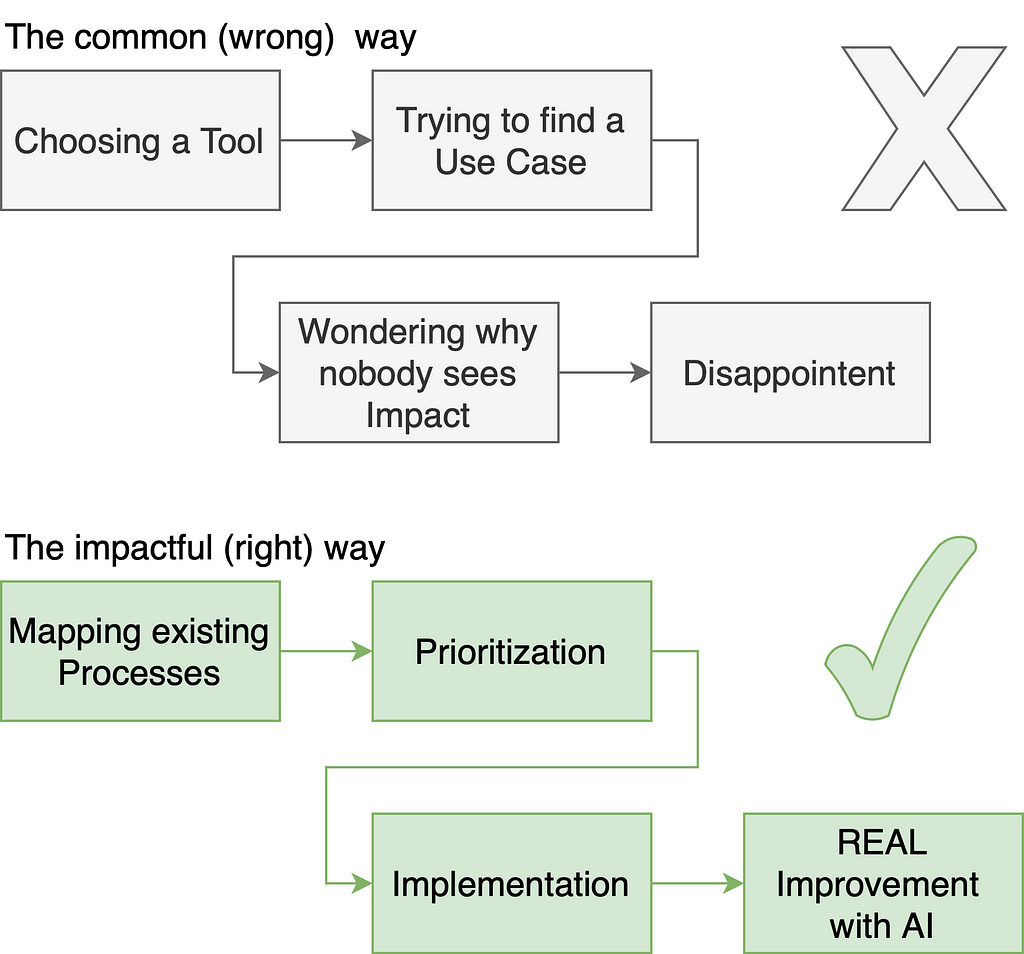
The most common disillusion that many organizations have is the following: They get excited about generative AI with ChatGPT or Microsoft Co-Pilot, read some article about how AI can “make your business better in some way,” then try to find other use cases where they can slap a chatbot on and in the end are disappointed when the results are not super satisfying. And then, the justification phase comes. I often hear things like, “The model is not good enough” or “We need to upskill the people to write better prompts.”
In 90% of the cases, these are not the correct conclusions and come from the issue that we think in Chatbots. I have developed over three dozen generative AI applications for organizations of three people to global enterprises with over three hundred thousand employees and I have seen this pattern everywhere.
There are thousands of companies out there telling you that you need to have “some kind of chatbot solution” because everybody does that. OpenAI with ChatGPT, Microsoft Copilot, Google with Gemini and all the other companies selling you chatbots are doing a great job breaking down initial barriers to creating a chatbot. But let me tell you: 75% of the really painful problems you can solve with generative AI do not benefit from being a chatbot.
Too often, I see managers, program directors, or other decision-makers start with the idea: “We have here some product with AI that lets us build chatbots — let’s find as many places as possible to implement it.” In my experience, this is the wrong approach because you are starting from a solution and trying to fit an existing problem into it. What would be the correct way would be to look into a problem, analyze it and find an AI solution that fits. A chatbot may be a good interface for some use cases, but forcing every issue into a chatbot is problematic.
In this article, I’ll share insights and the method I’ve developed through hands-on experience building countless applications. These applications, now live in production and serving thousands of users, have shaped my thinking about building impactful generative AI solutions — instead of blindly following a trend and feeling disappointed if it does not work.
Think about your Processes first — Chatbots (or other interfaces) second
I tell you not to start your thinking from chatbots, so where should you start? The answer is simple: business processes.
Everything that happens within a company is a business process. A business process is a combination of different activities (“units of work”), events (for example, errors), and gateways (for example, decisions) connected into a workflow [1]. There are tools for modeling business processes [2] in well-known diagram forms and a whole research discipline centered around analyzing and improving business processes [3][4][5]. Business Process Management is a good tool because it is not theoretical but is used everywhere in companies — even though they do not know what to call it.
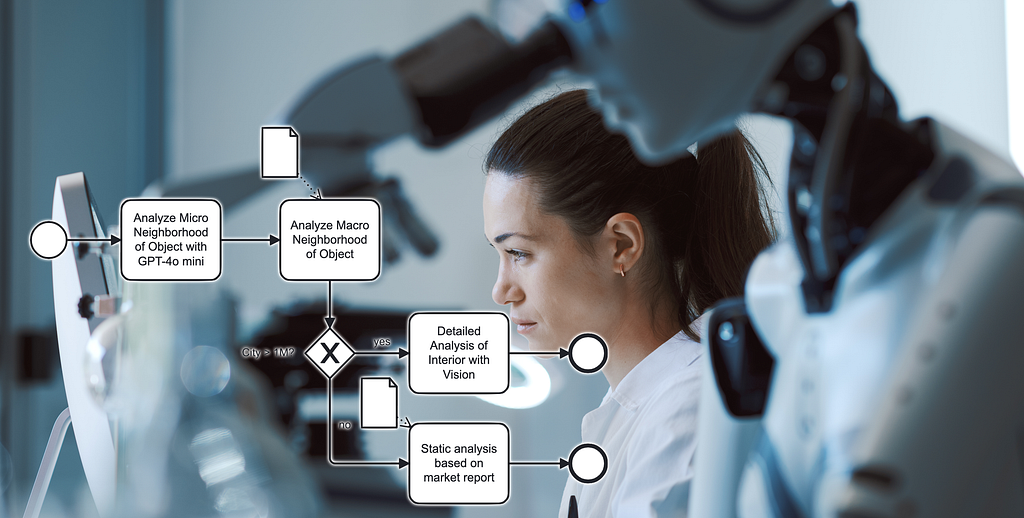
Let me give you an example. Imagine you are a company that does real estate valuations for a bank. Before banks give out mortgages, they ask real estate valuers to estimate how much the object is worth so that they know that in case the mortgage cannot be paid back, they have the actual price.
Creating a real estate valuation report is one large business process we can break down into subprocesses. Usually, valuers physically drive to the house, take pictures and then sit there writing a 20–30 page report describing their valuation. Let us, for a moment, not fall into the “uh a 20–30 page report, let me sit in front of ChatGPT and I will probably be faster” habit. Remember: processes first, then the solution.
We can break this process down into smaller sub-processes like driving to the house, taking pictures and then writing the different parts of the report: location description of the house, describing the condition and sizes of the different rooms. When we look deeper into a single process, we will see the tasks, gateways, and events involved. For example, for writing the description of the location, a real estate valuer sits at their desk, does some research, looks on Google Maps what shops are around, and checks out the transport map of the city to determine how well the house is connected and how the street looks like. These are all activities (or tasks) that the case worker has to do. If the home is a single farm in the middle of nowhere, the public transport options are probably irrelevant because buyers of such houses usually are car dependent anyway. This decision on which path to go in a process is called a gateway.
This process-driven mindset we apply here starts with assessing the current process before throwing any AI on it.
Orchestration Instead of Chat-Based Interactions
With this analysis of our processes and our goal we can now start looking into how a process with AI should look like. It is important to think about the individual steps that we need to take. If we only focus on the subprocess for creating the description that may look like this:
analyzing the locations and shops around the house
describing the condition of the interior
unless the location is very remote: finding the closest public transport stops
writing a page of text for the report
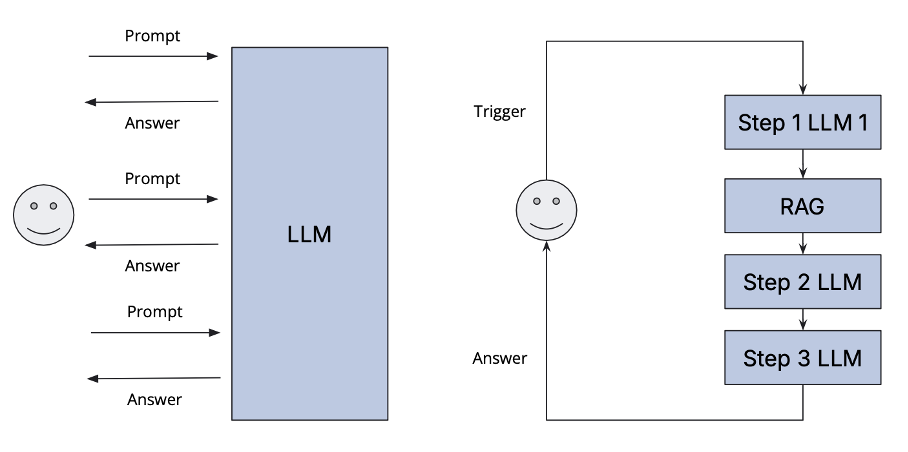
And yes, you can do that in an interactive way with a chatbot where you work with an “AI sparring partner” until you have your output. But this has in a company setting three major issues:
Reproducibility: Everybody prompts differently. This leads to different outputs depending on the skill and experience level of the prompting user. As a company, we want our output to be as reproducible as possible.
Varying quality: You probably have had interactions with ChatGPT where you needed to rephrase prompts multiple times until you had the quality that you wanted. And sometimes you get completely wrong answers. In this example, we have not found a single LLM that can describe the shops around in high quality without hallucinating.
Data and existing systems integration: Every company has internal knowledge that they might want to use in those interactions. And yes, you can do some retrieval augemented generation (RAG) with chatbots, but it is not the easiest and most universal approach that leads to good results in each case.
Those issues come from the core foundation that LLMs behind chatbots have.
Instead of relying on a “prompt-response” interaction cycle, enterprise applications should be designed as a series of orchestrated, (partially) AI-driven process steps, each targeting a specific goal. For example, users could trigger a multi-step process that integrates various models and potentially multimodal inputs to deliver more effective results and combine those steps with small scripts that retrieve data without using AI. More powerful and automated workflows can be created by incorporating Retrieval-Augmented Generation (RAG) and minimizing human intervention.
This orchestration approach delivers significant efficiency improvements compared to manual orchestration through an interactive interface. Also, not every step in the process should be done by relying purely on an AI model. In the example above, we actually discovered that using the Google Maps API to get nearby stops and transit stations is far superior in terms of quality than asking a good LLM like GPT-4o or even a web search RAG engine like Perplexity.
Efficiency Gains Through Orchestration
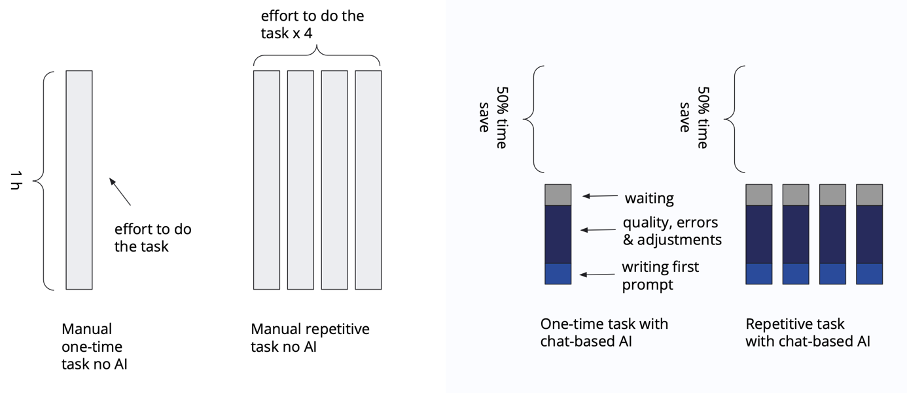
Let us think for a moment about a time without AI. Manual processes can take significant time. Let’s assume a task takes one hour to complete manually, and the process is repeated four times, requiring four hours in total. Using a chatbot solution powered by generative AI could save 50% (or whatever percentage) of the time. However, the remaining time is spent formulating prompts, waiting for responses, and ensuring output quality through corrections and adjustments. Is that as good as it gets?
For repetitive tasks, despite the time savings, the need to formulate prompts, wait, and adjust outputs for consistency can be problematic in organizations where multiple employees execute the same process. To address this, leveraging process templates becomes critical.
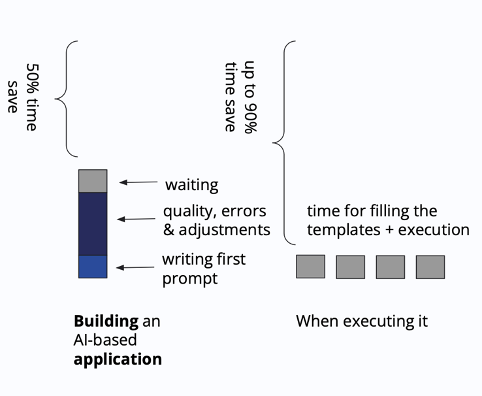
With templates, processes are generalized and parametrized to be reusable. The effort to create a high-quality process template occurs only once, while the execution for individual cases becomes significantly more efficient. Time spent on prompt creation, quality assurance, and output adjustments is dramatically reduced. This is the core difference when comparing chatbot-based solutions to AI-supported process orchestration with templates. And this core difference has a huge impact on quality and reproducibility.
Also, we now have a narrow field where we can test and validate our solution. In a chatbot where the user can insert anything, testing and finding confidencein a quantifiable way is hard. The more we define and restrict the possible parameters and files a user can insert, the better we can validate a solution quantitatively.
Using templates in AI-supported processes mirrors the principles of a Business Process Engine in traditional process management. When a new case arises, these engines utilize a repository of templates and select the corresponding template for orchestration. For orchestration, the input parameters are then filled.
In our example case of the real estate evaluation process, our template has three inputs: The type of object (single-family home), a collection of pictures of the interior and the address.
The process template looks like this:
Use the Google Places API with the given address to find the shops around.
Use the OpenAI vision API to describe the interior conditions.
Use the Google Places API to find the closest transport options.
Take the output JSON objects from 1. and 3. and the description of the transport options and create a page of text with GPT-4o with the following structure: Description of the object, shops and transport, then followed by the interior description and a conclusion giving each a score.
In our example use case, we have implemented the application using the entAIngine platform with the built-in no-code builder.
Note that in this process, only 1 out of 4 steps uses a large language model. And that is something good! Because the Google Maps API never hallucinates. Yes, it can have outdated data, but it will never “just make something up that sounds like it could be a reality.” Second, we have verifiability for a human in the loop because now we have real sources of information that we can analyze and sign off on.
In traditional process management, templates reduce process variability, ensure repeatability, and enhance efficiency and quality (as seen in methodologies like Six Sigma). This is the same mindset we have to adopt here.
Interfaces for Generative AI Applications
Now, we have started with a process that uses an LLM but also solves a lot of headaches. But how does a user interact with it?
The implementation of such a process can work by coding everything manually or by using a No-Code AI process engine like entAIngine [6].
When using templates to model business processes, interactions can occur in various ways. According to my experience in the last 2 years, for 90% of generative AI use cases, the following interfaces are relevant:
• Knowledge Retrieval Interface: Functions like a search engine that can cite and reference sources.
• Document Editor Interface: Combines text processing with access to templates, models, and orchestrations.
• Chat Interface: For iterative, interactive engagement.
• Embedded Orchestration without a Dedicated Interface (RPA): Integrates into existing interfaces via APIs.
The question in the end is, what is the most efficient way of interacting? And yes, for some creative use cases or for non-repetitive tasks, a chat interface can be the tool of choice. But often, it is not. Often, the core goal of a user is to create some sort of document. Then, having those templates available in an editor interface is a very efficient way of interacting. But sometimes, you do not need to create another isolated interface if you have an existing application that you want to augment with AI. The challenge here is merely to execute the right process, get the input data for it in the existing application, and show the output somewhere in the application interface.
These mentioned interfaces here form the foundation for the majority of generative AI use cases that I have encountered so far and, at the same time, enable scalable integration into enterprise environments.
The Bottom Line
By getting their minds away from “How can I use an AI chatbot everywhere?” to “What processes do which steps and how can generative AI be utilized in those steps?” businesses create the foundation for real AI impact. Combine AI with existing systems and then only look into the type of user interface that you need. In that way, you can unlock efficiency that businesses that cannot think beyond chatbots never even dream of.
References
[1] Dumas et al., “Fundamentals of Business Process Management”, 2018
[2] Object Management Group. “Business Process Model and Notation (BPMN) Version 2.0.2.” OMG Specification, Jan. 2014
[3] van der Aalst, “Process Mining: Data Science in Action”, 2016
[4] Luthra, Sunil, et al. “Total Quality Management (TQM): Principles, Methods, and Applications.” 1st ed., CRC Press, 2020.
[5] Panagacos, “The Ultimate Guide to Business Process Management”, 2012
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.