The European Securities and Markets Authority (ESMA) has recently called for public feedback to help shape the criteria for classifying cryptocurrency assets as financial instruments. The latest move follows the European Parliament’s passage of the Markets in Crypto Assets (MiCA)…
Invesco and Galaxy Digital have announced fee reductions for their spot Bitcoin (BTC) ETF (BTCO). According to filings with the U.S. Securities and Exchange Commission, the fee is reduced by 14 basis points, from 0.39% to 0.25%. Invesco and Galaxy…
The global market for NFTs has witnessed a downward trend in trading volumes, marking a consistent decline for the third week of January. According to the latest figures from CryptoSlam.io, a prominent on-chain data aggregator, the trading sales volume in…
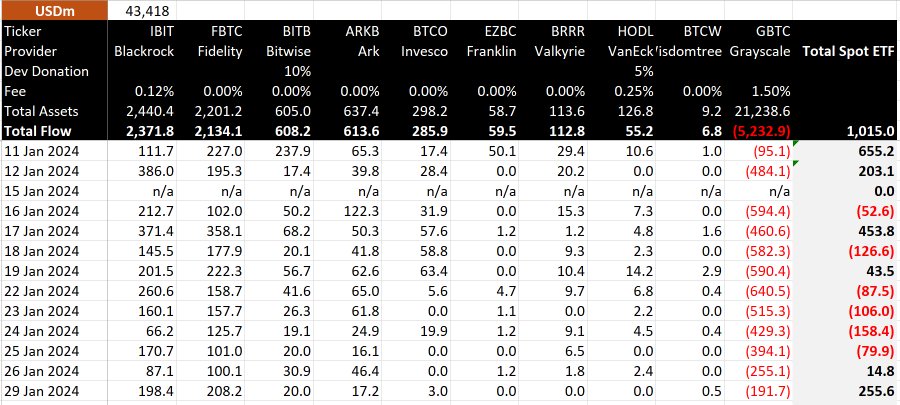
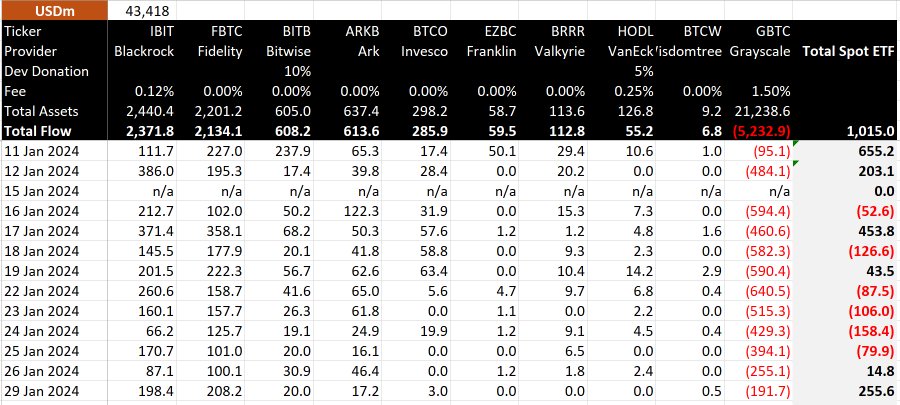
Grayscale’s Bitcoin Trust (GBTC) is experiencing a slowdown in outflows, with just under $200 million withdrawn from the fund on Jan. 29. Data from BitMEX Research indicates a total outflow of around $192 million during this reporting period. Notably, this marks the lowest outflows since the fund’s inception, surpassing only the initial day of trading […]
HyperFund founders Lee and Chunga sued for $1.7B crypto scam. Chunga has agreed to a settlement, pending court approval, while Lee faces legal action. Additional charges have been filed by the US Attorney’s Office. The US Securities and Exchange Commission (SEC) has taken decisive legal action against individuals allegedly involved in a cryptocurrency ‘Ponzi’ scheme […]
Binance reportedly plans to reduce its stake in Korean crypto exchange Gopax within the next two months to address regulatory reporting issues. Crypto exchange Binance, the major shareholder of Korean crypto trading platform Gopax, is set to reduce its stake…
pandas 2.2 was released on January 22nd 2024. Let’s take a look at the things this release introduces and how it will help us to improve our pandas workloads. It includes a bunch of improvements that will improve the user experience.
pandas 2.2 brought a few additional improvements that rely on the Apache Arrow ecosystem. Additionally, we added deprecations for changes that are necessary to make Copy-on-Write the default in pandas 3.0. Let’s dig into what this means for you. We will look at the most important changes in detail.
I am part of the pandas core team. I am an open source engineer for Coiled where I work on Dask, including improving the pandas integration.
Improved PyArrow support
We have introduced PyArrow backed DataFrame in pandas 2.0 and continued to improve the integration since then to enable a seamless integration into the pandas API. pandas has accessors for certain dtypes that enable specialized operations, like the string accessor, that provides many string methods. Historically, list and structs were represented as NumPy object dtype, which made working with them quite cumbersome. The Arrow dtype backend now enables tailored accessors for lists and structs, which makes working with these objects a lot easier.
This is a series that contains a dictionary in every row. Previously, this was only possible with NumPy object dtype and accessing elements from these rows required iterating over them. The struct accessor now enables direct access to certain attributes:
The next release will bring a CategoricalAccessor based on Arrow types.
Integrating the Apache ADBC Driver
Historically, pandas relied on SqlAlchemy to read data from an Sql database. This worked very reliably, but it was very slow. Alchemy reads the data row-wise, while pandas has a columnar layout, which makes reading and moving the data into a DataFrame slower than necessary.
The ADBC Driver from the Apache Arrow project enables users to read data in a columnar layout, which brings huge performance improvements. It reads the data and stores them into an Arrow table, which is used to convert to a pandas DataFrame. You can make this conversion zero-copy, if you set dtype_backend=”pyarrow” for read_sql.
Let’s look at an example:
import adbc_driver_postgresql.dbapi as pg_dbapi
df = pd.DataFrame( [ [1, 2, 3], [4, 5, 6], ], columns=['a', 'b', 'c'] ) uri = "postgresql://postgres:postgres@localhost/postgres" with pg_dbapi.connect(uri) as conn: df.to_sql("pandas_table", conn, index=False)
# for round-tripping with pg_dbapi.connect(uri) as conn: df2 = pd.read_sql("pandas_table", conn)
The ADBC Driver currently supports Postgres and Sqlite. I would recommend everyone to switch over to this driver if you use Postgres, the driver is significantly faster and completely avoids round-tripping through Python objects, thus preserving the database types more reliably. This is the feature that I am personally most excited about.
Adding case_when to the pandas API
Coming from Sql to pandas, users often miss the case-when syntax that provides an easy and clean way to create new columns conditionally. pandas 2.2 adds a new case_when method, that is defined on a Series. It operates similarly to what Sql does.
The method takes a list of conditions that are evaluated sequentially. The new object is then created with those values in rows where the condition evaluates to True. The method should make it significantly easier for us to create conditional columns.
Copy-on-Write
Copy-on-Write was initially introduced in pandas 1.5.0. The mode will become the default behavior with 3.0, which is hopefully the next pandas release. This means that we have to get our code into a state where it is compliant with the Copy-on-Write rules. pandas 2.2 introduced deprecation warnings for operations that will change behavior.
df = pd.DataFrame({"x": [1, 2, 3]})
df["x"][df["x"] > 1] = 100
This will now raise a FutureWarning.
FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0! You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy. A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
I wrote an earlier post that goes into more detail about how you can migrate your code and what to expect. There is an additional warning mode for Copy-on-Write that will raise warnings for all cases that change behavior:
pd.options.mode.copy_on_write = "warn"
Most of those warnings are only noise for the majority of pandas users, which is the reason why they are hidden behind an option.
This will raise a lengthy warning explaining what will change:
FutureWarning: Setting a value on a view: behaviour will change in pandas 3.0. You are mutating a Series or DataFrame object, and currently this mutation will also have effect on other Series or DataFrame objects that share data with this object. In pandas 3.0 (with Copy-on-Write), updating one Series or DataFrame object will never modify another.
The short summary of this is: Updating view will never update df, no matter what operation is used. This is most likely not relevant for most.
I would recommend enabling the mode and checking the warnings briefly, but not to pay too much attention to them if you are comfortable that you are not relying on updating two different objects at once.
This will give you the new release in your environment.
Conclusion
We’ve looked at a couple of improvements that will improve performance and user experience for certain aspects of pandas. The most exciting new features will come in pandas 3.0, where Copy-on-Write will be enabled by default.
Thank you for reading. Feel free to reach out to share your thoughts and feedback.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.