A detailed guideline for designing machine learning experiments that produce reliable, reproducible results.

Machine learning (ML) practitioners run experiments to compare the effectiveness of methods for both specific applications and for general types of problems. The validity of experimental results hinges on how practitioners design, run, and analyze their experiments. Unfortunately, many ML papers lack valid results. Recent studies [5] [6] reveal a lack of reproducibility in published experiments, attributing this to practices such as:
- Data contamination: engineering training datasets to include data that is semantically similar to, or directly from, the test dataset
- Cherrypicking: selectively choosing an experimental setup or results that favorably present a method
- Misreporting: including “the improper use of statistics to analyze results, such as claiming significance without proper statistical testing or using the wrong statistic test [6]
Such practices are not necessarily done intentionally — practitioners may face pressure to produce quick results or lack adequate resources. However, consistently using poor experimental practices inevitably leads to costly outcomes. So, how should we conduct Machine Learning experiments that achieve reproducible and reliable results? In this post, we present a guideline for designing and executing rigorous Machine Learning experiments.
Experiments: factors and response functions
An experiment involves a system with an input, a process, and an output, visualized in the diagram below. Consider a garden as a simple example: bulbs are the input, germination is the process, and flowers are the output. In an ML system, data is input into a learning function, which outputs predictions.
A practitioner aims to maximize some response function of the output — in our garden example, this could be the number of blooming flowers, while in an ML system, this is usually model accuracy. This response function depends on both controllable and uncontrollable factors. A gardener can control soil quality and daily watering but cannot control the weather. An ML practitioner can control most parameters in a ML system, such as the training procedure, parameters and pre-processing steps, while randomness comes from data selection.
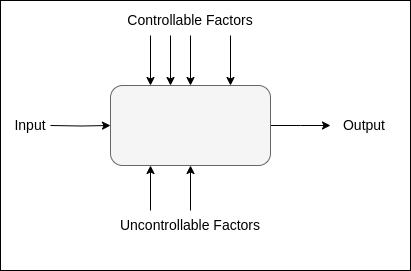
The goal of an experiment is to find the best configuration of controllable factors that maximizes the response function while minimizing the impact of uncontrollable factors. A well-designed experiment needs two key elements: a systematic way to test different combinations of controllable factors, and a method to account for randomness from uncontrollable factors.
Building on these principles, a clear and organized framework is crucial for effectively designing and conducting experiments. Below, we present a checklist that guides a practitioner through the planning and execution of an ML experiment.
A Machine Learning Experiment Checklist
To plan and perform a rigorous ML experiment:
- State the objective of your experiment
- Select the response function, or what you want to measure
- Decide what factors vary, and what remains the same
- Describe one run of the experiment, which should define:
(a) a single configuration of the experiment
(b) the datasets used - Choose an experimental design, which should define:
(a) how we explore the factor space and
(b) how we repeat our measurements (cross validation) - Perform the experiment
- Analyze the data
- Draw conclusions and recommendations
1. State the objective of the experiment
The objective should state clearly why is the experiment to be performed. It is also important to specify a meaningful effect size. For example, if the goal of an experiment is “to determine the if using a data augmentation technique improves my model’s accuracy”, then we must add, “a significant improvement is greater than or equal to 5%.”
2. Select the response function, or what you want to measure
The response function of a Machine Learning experiment is typically an accuracy metric relative to the task of the learning function, such as classification accuracy, mean average precision, or mean squared error. It could also be a measure of interpretability, robustness or complexity — so long as the metric is be well-defined.
3. Decide what factors vary, and what remains the same
A machine learning system has several controllable factors, such as model design, data pre-processing, training strategy, and feature selection. In this step, we decide what factors remain static, and what can vary across runs. For example, if the objective is “to determine the if using a data augmentation technique improves my model’s accuracy”, we could choose to vary the data augmentation strategies and their parameters, but keep the model the same across all runs.
4. Describe one run of the experiment
A run is a single instance of the experiment, where a process is applied to a single configuration of factors. In our example experiment with the aim “to determine the if using a data augmentation technique improves my model’s accuracy”, a single run would be: “to train a model on a training dataset using one data augmentation technique and measure its accuracy on a held-out test set.”
In this step, we also select the data for our experiment. When choosing datasets, we must consider whether our experiment a domain-specific application or for generic use. A domain-specific experiment typically requires a single dataset that is representative of the domain, while experiments that aim to show a generic result should evaluate methods across multiple datasets with diverse data types [1].
In both cases, we must define specifically the training, validation and testing datasets. If we are splitting one dataset, we should record the data splits. This is an essential step in avoiding accidental contamination!
5. Choose an experimental design
The experimental design is is the collection of runs that we will perform. An experiment design describes:
- What factors and levels (categories or values of a factor) will be studied
- A randomization scheme (cross validation)
If we are running an experiment to test the impact of training dataset size on the resulting model’s robustness, which range of sizes will we test, and how granular should we get? When varying multiple factors, does it make sense to test all possible combinations of all factor/level configurations? If we plan to perform statistical tests, it could be helpful to follow a specific experiment design, such as a factorial design or randomized block design (see [3] for more information).
Cross validation is essential for ML experiments, as this reduces the variance of your results which come from the choice of dataset split. To determine the number of cross-validation samples needed, we return to our objective statement in Step 1. If we plan to perform a statistical analysis, we need to ensure that we generate enough data for our specific statistical test.
A final part of this step is to think about resource constraints. How much time and compute does one run take? Do we have enough resources to run this experiment as we designed it? Perhaps the design must be altered to meet resource constraints.
6. Perform the experiment
To ensure that the experiment runs smoothly, It is important to have a rigorous system in place to organize data, track experiment runs, and analyze resource allocation. Several open-source tools are available for this purpose (see awesome-ml-experiment-management).
7. Analyze the data
Depending on the objective and the domain of the experiment, it could suffice to look at cross-validation averages (and error bars!) of the results. However, the best way to validate results is through statistical hypothesis testing, which rigorously shows that the probability of obtaining your results given the data is not due to chance. Statistical testing is necessary if the objective of the experiment is to show a cause-and-effect relationship.
8. Draw conclusions
Depending on the analysis in the previous step, we can now state the conclusions we draw from our experiment. Can we make any claims from our results, or do we need to see more data? Solid conclusions are backed by the resulting data and are reproducible. Any practitioner who is unfamiliar with the experiment should be able to run the experiment from start to finish, obtain the same results, and draw from the results the same conclusions.
Final Thoughts
A Machine Learning experiment has two key factors: a systematic design for testing different combinations of factors, and a cross-validation scheme to control for randomness. Following the ML experiment checklist of this post throughout the planning and execution of an experiment can help a practitioner, or a team of practitioners, ensure that the resulting experiments are reliable and reproducible.
Thank you for reading! If you found this post useful, please consider following me on Medium, or checking out my website.
References
[1] Joris Guerin “A Quick Guide to Design Rigorous Machine Learning Experiments.” Towards Data Science. Available Online.
[2] Design & Analysis of Machine Learning Experiments — Machine Learning — Spring 2016 — Professor Kogan. YouTube video.
[3] Lawson, John. Design and analysis of experiments with R. Available Online.
[4] Questionable Practices in Machine Learning. ArXiv preprint.
[5] Improving Reproducibility in Machine Learning Research. Journal of Machine Learning Research, 2022. Available Online.
[6] A Step Toward Quantifying Independently Reproducible Machine Learning Research. ArXiv preprint.
Machine Learning Experiments Done Right was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Machine Learning Experiments Done Right
Go Here to Read this Fast! Machine Learning Experiments Done Right