In neuroscience and other biomedical sciences, it is common to use behavioral tests to assess responses to experimental conditions or treatments. We can assess many aspects, from basic motor and exploratory behaviors to memory and learning. Many of these variables are continuous (numerical) responses, i.e. they can take (finite or infinite) values in a given range. Time in the open field, animal weight, or the number of cells in a brain region are some examples.
However, there are other types of variables that we record in our experiments. A very common one is ordered categorical variables, also called ordinal variables. These are categorical variables that have a natural order, analogous to the well-known surveys in which we answer whether we agree or disagree with a statement, with 0 being strongly disagree and 5 being strongly agree. To facilitate the recording of these variables in printed or digital datasheets, we codify them (by convention) as numbers. This is the case of the 5-point Bederson score used in the context of cerebral ischemia research in rodent models (1), which is coded as follows:
– 0 = no observable deficit
– 1 = forelimb flexion
– 2 = forelimb flexion and decreased resistance to lateral push
– 3 = circling
– 4 = circling and spinning around the cranial-caudal axis
– 5 = no spontaneous movement.
Note that the numbers are just simple conventions. We could also use a,b,c,d,e; excellent, good, not so good, bad, very bad, almost dead; etc. I do not think it is presumptuous to stress the self-evident nature of the matter.
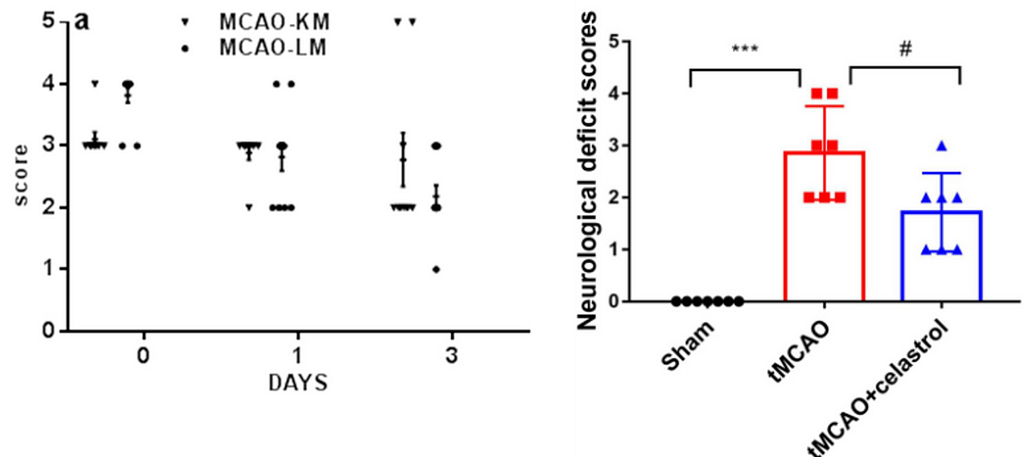
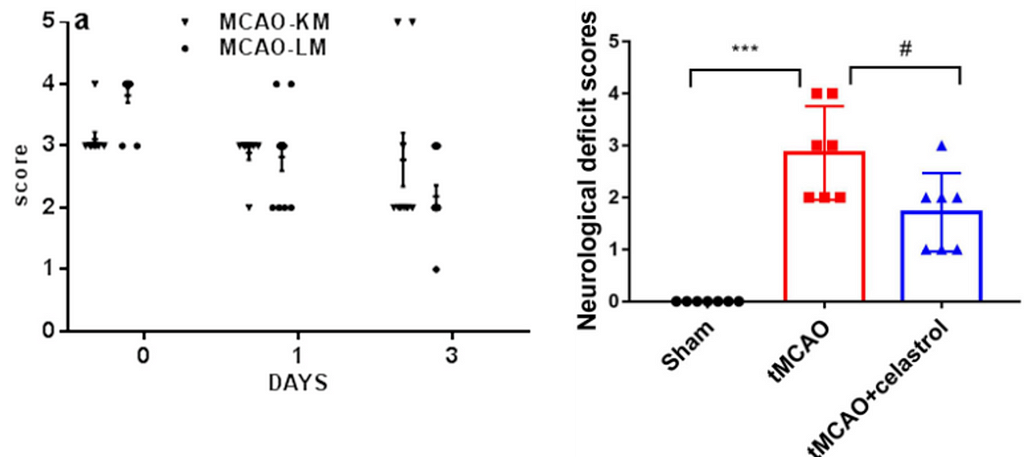
Surprisingly, however, Figure 1 represents a particular and widespread malpractice that scientists in this field have been practicing for years: They use t-tests and ANOVAS to analyze such ordered categorical variables.
Figure 1: Left: Neurological score by Onufriev et. al (2021) (CC-BY). Right: Neurological score by Liu et al. (2022) (CC-BY).
I still cannot find a logical explanation for why dozens of authors, reviewers, and editors feel comfortable with this scenario. Not only is it not logical, but more importantly, it leads to biased effect sizes, low detection rates, and type I error rates, among other things (2).
When I have played the role of reviewer 2 and emphasized this point to authors, asking them why they evaluate a categorical response with a statistical test designed to deal with continuous numerical variables, what I get is a long list of published articles that follow this irrational practice. So I finally found an answer to why they do it:
what Gerd Gigerenzer (2004) calls “the ritual of mindless statistics” (3).
In fact, most of us scientists have little idea what we are doing with our data, and are simply repeating common malpractices passed down from generation to generation in labs around the world.
In this article, we’ll then look at a more viable alternative for analyzing ordered categorical variables using R, brms (4) and elements from the tidyverse (5).
Facing the ritual of mindless statistics
To avoid the ritual of mindless statistics, we’ll recreate the data set from Liu et. al (2022) in Figure 1 by eyeballing the data points and organizing them in a table:
# We create an empty data frame to populate df <- data.frame(Group = character(), Response = integer())
# We populate the data frame for (group in names(observations)) { for (response in unique(observations[[group]])) { df <- rbind(df, data.frame(Group = rep(group, sum(observations[[group]] == response)), Response = rep(response, sum(observations[[group]] == response)))) } }
head(df)
If you look at the R code (in R-studio) at this point, you will notice that the variable `Response’ is identified as a number ranging from 0 to 4. Of course, we are fully aware that this response is not numeric, but an ordered (ordinal) categorical variable. So we do the conversion explicitly:
plot.margin = margin(t = 10, # Top margin r = 2, # Right margin b = 10, # Bottom margin l = 10) # Left margin )
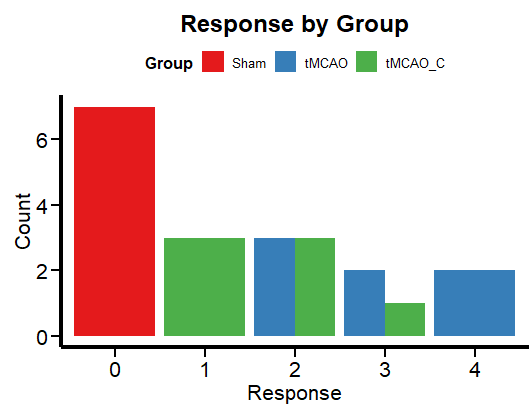
A simple way to visualize categorical data is with a bar graph.
ggplot(df, aes(x = factor(Response), fill = Group)) + geom_bar(position = "dodge") + labs(x = "Response", y = "Count", title = "Response by Group") + theme_minimal() + scale_fill_brewer(palette = "Set1") + Plot_theme + theme(legend.position = "top", legend.direction = "horizontal")
Figure 2: Response colored by group
Figure 2 shows the frequency per group. This is more in line with the logic of a categorical variable than box plots, which are more relevant for continuous numerical variables. Now let’s run a regression to unravel the mysteries (if any) of this data set.
Fitting an Ordinal Regression with brms
We’ll use brms to fit a cumulative model. This model assumes that the neurological score Y is derived from the categorization of a (presumably) latent (but not observable or measured) continuous variable Y˜ (2). As usual in most brms tutorials, I must apologize for skipping the “priors” issue. Let’s assume an “I have no idea” mentality and let the default (flat) brms priors do the dirty work.
We fit the cumulative model by following the usual formula syntax and adding cumulative(“probit”) as a family (assuming the latent variable and the corresponding error term are normally distributed). We have only one predictor variable, the experimental group to which each animal belongs.
Ordinal_Fit <- brm(Response ~ Group, data = df, family = cumulative("probit"), # seed for reproducibility purposes seed = 8807, control = list(adapt_delta = 0.99), # this is to save the model in my laptop file = "Models/2024-04-03_UseAndAbuseANOVA/Ordinal_Fit.rds", file_refit = "never")
# Add loo for model comparison Ordinal_Fit <- add_criterion(Ordinal_Fit, c("loo", "waic", "bayes_R2"))
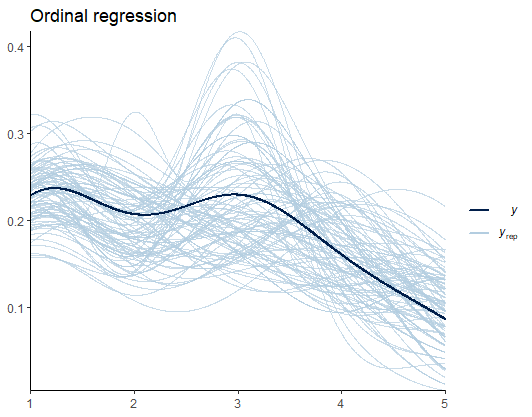
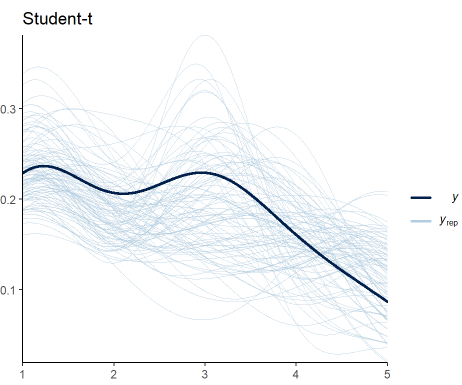
Before we look at the results, let’s do some model diagnostics to compare the observations and the model predictions.
Figure 3: Model diagnostics for the ordinal regression
From Figure 3, I speculate that such deviations are the results of the uneven distribution (variance) of scores across groups. Later, we’ll see if predicting the variance yields better estimates. For now, we are good to go.
Checking the results for the ordinal regression
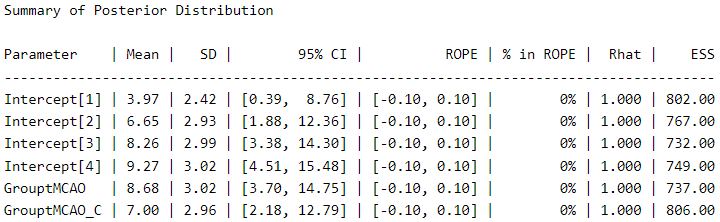
Let’s take a look at the posterior distribution using the describe_posterior function from the bayestestR package (6), as an alternative to the typical summary function.
The thresholds (score thresholds) are labeled as “Intercepts” in this model, which apply to our baseline “sham” condition. The coefficients for “GrouptMCAO” and “GrouptMCAO_C” indicate the difference from sham animals on the latent Y˜ scale. Thus, we see that “GrouptMCAO” has 8.6 standard deviations higher scores on the latent Y˜ scale.
I want to point out a crucial (and not trivial) aspect here as a reminder for a future post (stay tuned). In my opinion, it is irrelevant to make comparisons between a group that does not have a distribution (which is 0 in all cases), such as the sham group, and a group that does have a distribution (the experimental groups). If you think about it carefully, the purpose of this procedure is null. But let us follow the thread of modern scientific culture and not think too much about it.
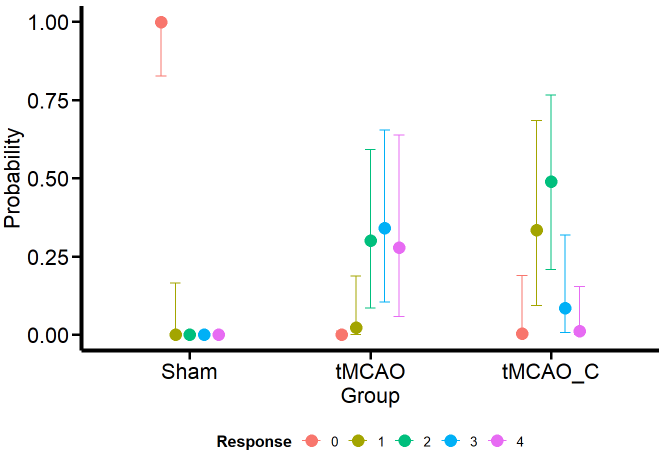
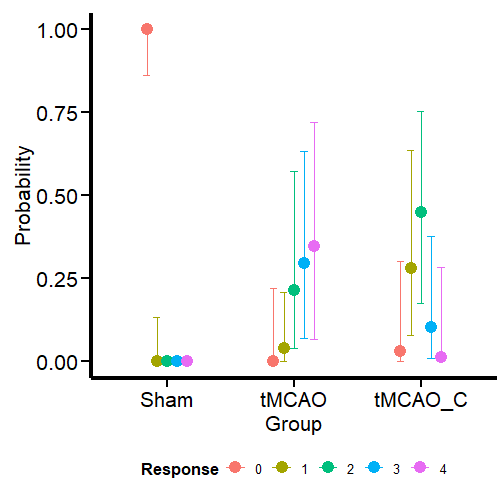
Of course, appreciating the difference between the groups becomes more feasible if we look at it visually with the conditional effects’ function ofbrms’.
Figure 4: Conditional effects for the Ordinal model
Curiously (or perhaps not so much from the MCMC simulation framework), the model estimates that the dummy group can have values of 1, although we have not seen this in the data. One possible reason is that the model estimates a common variance for all groups. We’ll see if this aspect changes when we model the variance as a response.
Otherwise, the estimates obtained for the tMCAO and tMCO_C groups are much closer to the data. This allows us to make more precise statements instead of running an ANOVA (incorrectly for ordinal variables) and saying that there is “a significant difference” between one group and the other, which is a meaningless statement. For example, the model tells us that scores of 2–4 for the tMCAO group have a similar probability (about 25%). The case is different for the tMCAO_C group, where the probability of 2 in the neurological score is higher (with considerable uncertainty) than for the other scores. If I were confronted with this data set and this model, I would claim that the probability that the tMCAO_C group reflects less neurological damage (based on scores 1 and 2) is higher than for the tMCAO group.
Can we get precise numbers that quantify the differences between the scores of the different groups and their uncertainty? Of course, we can! using the emmeans package (7). But that will be the subject of another post (stay tuned).
Including the variance as a response variable
For this type of cumulative model, there is no sigma parameter. Instead, to account for unequal variances, we need to use a parameter called disc. For more on this aspect, see the Ordinal Regression tutorial by Paul-Christian Bürkner, the creator of brms (2).
Ordinal_Fit2 <- brm( formula = Ordinal_Mdl2, data = df, family = cumulative("probit"), # seed for reproducibility purposes seed = 8807, control = list(adapt_delta = 0.99), # this is to save the model in my laptop file = "Models/2024-04-03_UseAndAbuseANOVA/Ordinal_Fit2.rds", file_refit = "never")
# Add loo for model comparison Ordinal_Fit2 <- add_criterion(Ordinal_Fit2, c("loo", "waic", "bayes_R2"))
Model diagnostics
We perform the model diagnostics as done previously:
Figure 5: Model diagnostics for our model predicting the variance
Figure 5 shows that my expectations were not met. Including the variance as a response in the model does not improve the fit to data. The trend is maintained, but the predictions still vary significantly. Nevertheless, this is another candidate we can consider to be our generative model.
Checking the results for our new model
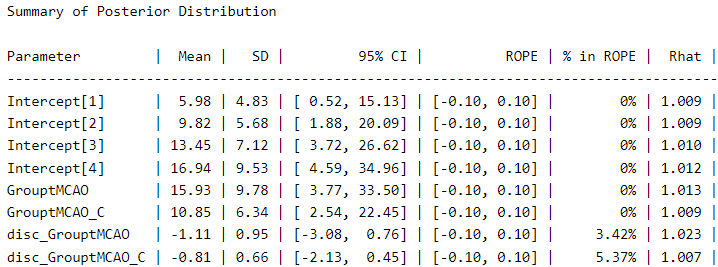
We visualize the posterior distribution for this model:
We can see a meaningful difference in the coefficients compared to the first model. The coefficient for “GrouptMCAO” increases from 8.6 to 15.9 and that for “GrouptMCAO_C” from 7 to 10.8. Undoubtedly, this model gives us a different picture. Otherwise, the variance term is presented under the names “disc_GrouptMCAO” and “disc_GrouptMCAO_C”. We can see that both variances are very different from our “sham” baseline.
Figure 6: Conditional effects for our model including the variance as a response
Contrary to what I expected, the model still predicts that sham animals have a small probability of scoring 1. What we have confirmed here is that this prediction is not based on the (false) assumption that all groups have the same variance. Nevertheless, it is still a logical prediction (not irrational) within this framework (ordinal regression) based on thresholds. If we go to Richard McElreath’s Statistical Rethinking (8) we find the same situation with monkeys pulling levers. Fitting a more constrained model will require the use of informative priors. Leave that for a future post. I know I made three promises here, but I will keep them.
In this model, the probabilities for the different outcomes in the tMCAO group shift slightly. However, given the high uncertainty, I will not change my conclusion about the performance of this group based on this model. For the tMCAO_C group, on the other hand, the predictions do not shift in a way that is readily apparent to the eye. Let’s conclude this blog post by comparing the two models.
Model comparison
We do the model comparison using the the loo package (9, 10) for leave-one-out cross validation. For an alternative approach using the WAIC criteria (11) I suggest you read this post also published by TDS Editors.
loo(Ordinal_Fit, Ordinal_Fit2)
Under this scheme, the models have very similar performance. In fact, the first model is slightly better for out-of-sample predictions. Accounting for variance did not help much in this particular case, where (perhaps) relying on informative priors can unlock the next step of scientific inference.
I would appreciate your comments or feedback letting me know if this journey was useful to you. If you want more quality content on data science and other topics, you might consider becoming a medium member.
In the future, you may find an updated version of this post on my GitHub site.
3. G. Gigerenzer, Mindless statistics. The Journal of Socio-Economics. 33, 587–606 (2004).
4. P.-C. Bürkner, Brms: An r package for bayesian multilevel models using stan. 80 (2017), doi:10.18637/jss.v080.i01.
5. H. Wickham, M. Averick, J. Bryan, W. Chang, L. D. McGowan, R. François, G. Grolemund, A. Hayes, L. Henry, J. Hester, M. Kuhn, T. L. Pedersen, E. Miller, S. M. Bache, K. Müller, J. Ooms, D. Robinson, D. P. Seidel, V. Spinu, K. Takahashi, D. Vaughan, C. Wilke, K. Woo, H. Yutani, Welcome to the tidyverse. 4, 1686 (2019).
9. A. Vehtari, J. Gabry, M. Magnusson, Y. Yao, P.-C. Bürkner, T. Paananen, A. Gelman, Loo: Efficient leave-one-out cross-validation and WAIC for bayesian models (2022) (available at https://mc-stan.org/loo/).
While the solar eclipse is one of the most photographed moments in time, it’s also when our eyes and fragile camera sensors are most vulnerable to damage. Here’s what to know.
Apple’s second-generation AirPods Pro have dipped to under $200 in a deal from Amazon. The AirPods Pro, which normally cost $250, are $60 off right now, bringing the price down to just $190. That’s the same price we saw during Amazon’s Big Spring Sale. The AirPods Pro offer a number of premium features over the standard AirPods, including active noise cancellation for when you want to shut out the world, and an impressive transparency mode for when you want to hear your surroundings.
The second-generation AirPods Pro came out in 2022 and brought Apple’s H2 chip to the earbuds for a notable performance boost. It offers Adaptive Audio, which will automatically switch between Active Noise Cancellation and Transparency Mode based on what’s going on around you. With Conversation Awareness, they can lower the volume when you’re speaking and make it so other people’s voices are easier to hear.
We gave this version of the AirPods Pro a review score of 88, and it’s one of our picks for the best wireless earbuds on the market. The second-generation AirPods Pro are dust, sweat and water resistant, so they should hold up well for workouts, and they achieve better battery life than the previous generation. They can get about six hours of battery life with features like ANC enabled, and that goes up to as much as 30 hours with the charging case. Apple says popping the AirPods Pro in the case for 5 minutes will give you an hour of additional listening or talking time.
AirPods Pro also offer Personalized Spatial Audio with head tracking for more immersive listening while you’re watching TV or movies. The gesture controls that were introduced with this generation of the earbuds might take some getting used to, though. With AirPods Pro, you can adjust the volume by swiping the touch control.
This article originally appeared on Engadget at https://www.engadget.com/apples-second-generation-airpods-pro-are-back-on-sale-for-190-142626914.html?src=rss
Rebel Satoshi ($RBLZ) has received endorsement from several market experts amid its ICOs. Some market experts are optimistic that Ethereum (ETH) will reach a price of $4,853 in 2024. A number of analysts believe Shiba Inu (SHIB) will experience a 59% price surge in 2024. Rebel Satoshi (RBLZ) remains one of the altcoins to watch […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.